시작에 앞서
요즘 가장 핫한 ChatGPT AI Model (정확히는 ChatGPT 모델과 동일한 모델에 기반한 davinci-003 모델입니다.)을 활용해 애플리케이션에서 AI와 통신하는 RestAPI 를 개발하는 과정을 한번 만들어보고자 이렇게 포스트를 다루게 되었습니다.
API Key
본격적인 시작전에 사전 준비물이 하나 있습니다. 바로 OpenAI 를 사용하기 위한 API Key를 발급받는 것이죠. OpenAI API 에 접속하셔서 API-Key 를 발급받고 스프링부트 애플리케이션에서 적용시켜야 인증된 유저로써 OpenAI 를 원활하게 사용 가능합니다.
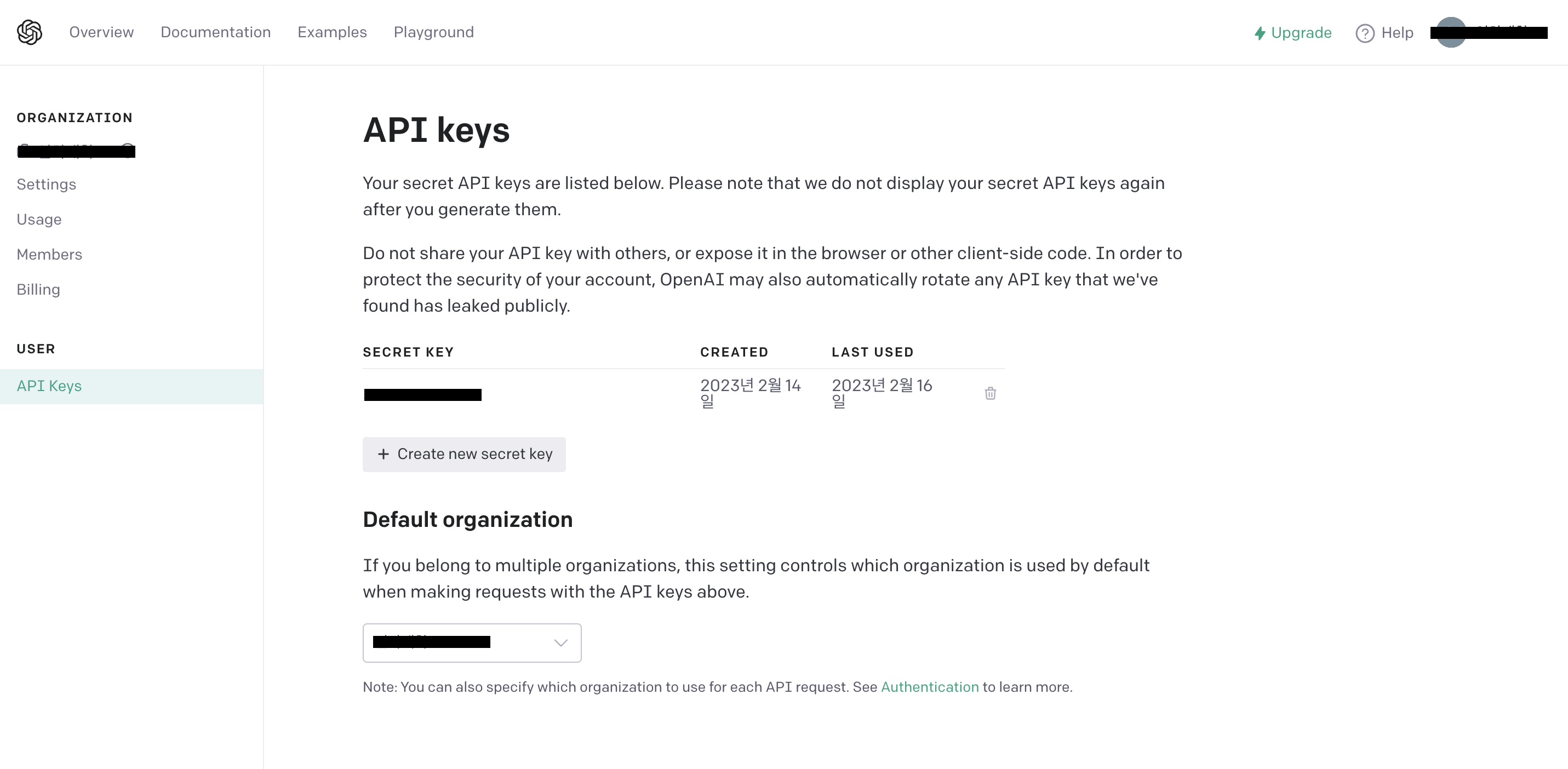
위와 같이 Api Key 를 발급받으면 성공한 것입니다. 발급받은 키를 복사하신후 따로 저장해둡시다.
build.gradle
우선 다음과 같이 gradle 파일에서 의존성을 주입해줍시다. 이때 annotationProcessor 는 사실 꼭 의존성 주입을 하지 않아도 되지만, 저는 spring-boot-starter 에 있는 코드를 조금 더 변경하고 응용하면서 자세한 기능들을 소개해볼까 합니다.
implementation 'io.github.flashvayne:chatgpt-spring-boot-starter:1.0.0'
annotationProcessor "org.springframework.boot:spring-boot-configuration-processor"gradle 파일에 의존성 코드까지 추가해주셨다면, bootJar 를 통해 빌드 테스트도 한번 실행해보시길 바랍니다. BUILD SUCCESSFUL 에 성공하도록 말이죠.
application.yml : API-Key 적용
이제 발급받은 API-key 를 스프링부트 애플리케이션에 적용시켜 줍시다. 아래와 같이 yml 내에 명시해주시면 됩니다. 앞서 말씀드린 내용이지만, 만일 API-Key 를 명시해주지 않는다면 인가되지 않은 유저로써 401 UnAuhorized 에러 메세지를 리턴받게 될겁니다.
spring:
profiles:
include: API-KEY
openai:
api-key: qowjfkopqw-UWnein12321313 // api key
chatgpt:
api-key: qowjfkopqw-UWnein12321313 // api keyAPI-Key 사용시 유의사항
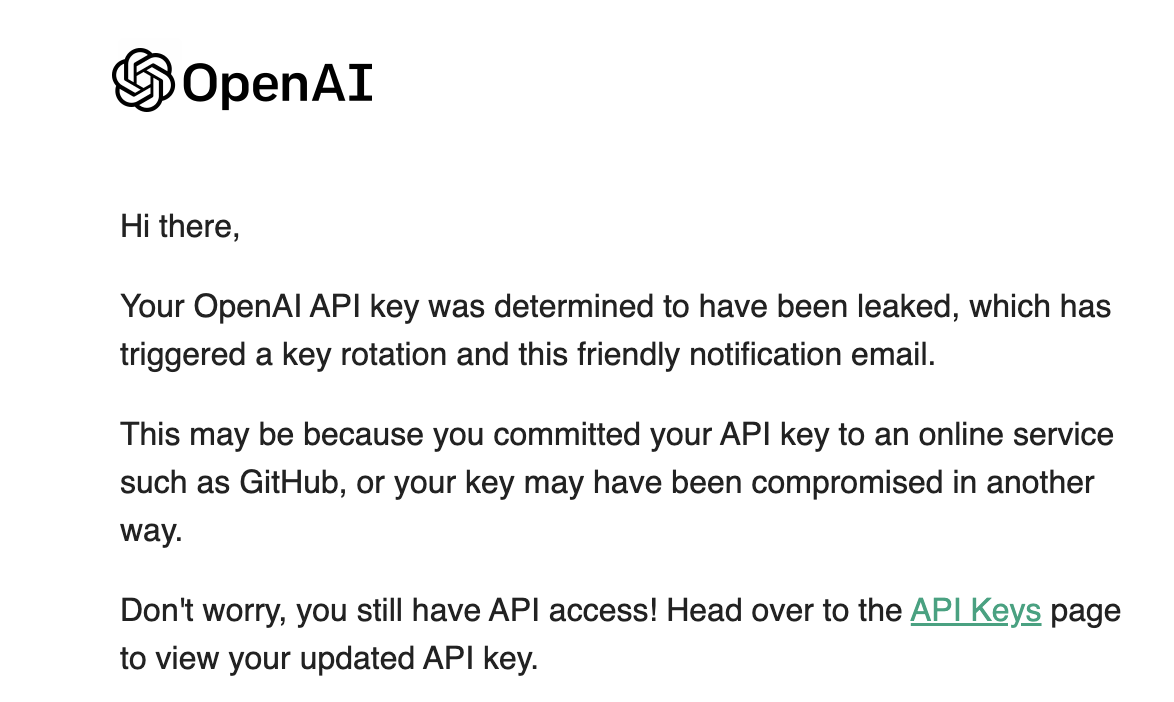
API-Key 를 애플리케이션 단에 적용시킬 때 꼭 주의하셔할 사항이 있습니다.
API-Key 를 방금 말씀드렸듯이 특정 사용자가 OpenAI 를 원활하게 사용하기 위해 인증받는 키로써, 절대 퍼블릭으로 유출되어선 안됩니다. 예를들어 깃허브 레포지토리에 공개로 절대 유출시키면 안되는 것이죠.
만일 깃허브 레포지토리에 public 으로 그대로 API-Key 를 유출시킨다면 몇시간후에 보안을 위해 OpenAI 사이트에서 자동으로 해당 API-Key 를 위처럼 만료시켜주긴 합니다.
그래도 최대한 보안 문제를 위해 본인 로컬에서만 사용하시거나, 또는 레포지토리에 소스코드를 올린다면 .git ignore 로 yml 파일을 제외시켜 주시야겠죠?
RestController
이제 본격적인 스프링부트 RestAPI 개발 내용을 시작해봅시다. 우선 컨트롤러를 먼저 소개해볼까 합니다. 질문 하나를 사용자로 부터 입력받으면, chatGPT 에 해당 질문을 던지고 그에대한 대답을 리턴받는 API 입니다.
이때 저는 qreQuestion 을 보시듯이 "안녕, ChatGPT! 나 질문이 있어." 이라는 디폴트 질문과 함께, 사용자로부터 입력받는 Request 문자열을 합쳐서 chatGPT 에게 질문을 던지는 방식으로 개발을 진행했습니다.
@RequestMapping("/chatGPT")
@RestController
public class MyChatGPTController {
String qreQuestion = "안녕, ChatGPT! 나 질문이 있어.";
private final MyChatGPTService chatGPTService;
private final JwtService jwtService;
@Autowired
public MyChatGPTController(MyChatGPTService chatGPTService, JwtService jwtService){
this.chatGPTService = chatGPTService;
this.jwtService = jwtService;
}
@ResponseBody
@PostMapping("/askChatGPT")
public BaseResponse<ChatGptRes> askToChatGPT(@RequestBody ChatGptReq chatGptReq){
try {
int userIdx = jwtService.getUserIdx();
String resultQuestion = qreQuestion + chatGptReq.getQuestion();
ChatGptRes chatGptRes = chatGPTService.getChatResponse(resultQuestion);
return new BaseResponse(chatGptRes);
} catch (BaseException baseException){
return new BaseResponse(baseException.getStatus());
}
}
}ChatGptReq
위 컨트롤러 단에서 @RequestBody로 입력받는 클래스입니다. 보시듯이 질문란 필드 하나를 정의해두었습니다.
@Data
@AllArgsConstructor
@NoArgsConstructor
public class ChatGptReq {
String question;
}ChatGptService
다음으로는 ChatGPT 를 사용하기 위한 핵심적인 비즈니스 로직인 Service 단입니다. ChatgptService 를 생성자 의존관계 주입을 진행해주시고, sendMessage() 메소드를 호출하여 ChatGPT 에게 질문을 보내는 로직을 만들어 봤습니다.
@Service
public class MyChatGPTService {
private ChatgptService chatgptService;
@Autowired
public MyChatGPTService(ChatgptService chatgptService){
this.chatgptService = chatgptService;
}
public ChatGptRes getChatResponse(String prompt) throws BaseException {
try {
// ChatGPT 에게 질문을 던집니다.
String responseMessage = chatgptService.sendMessage(prompt);
return new ChatGptRes(responseMessage, category);
} catch (Exception exception){
throw new BaseException(BaseResponseStatus.SERVER_ERROR);
}
}
}ChatgptService
이때 MyChatGPTService 의 생성자에서 @Autowired 로 의존관계를 주입한 ChatgptService 가 무엇인지 궁금하실겁니다. 이것은 아까 저희가 gradle 파일에서 의존성 주입을 진행했던 중에 하나인 인터페이스이죠. 그에 대한 구성내용은 다음과 같습니다.
당연한 말이지만, 이미 gradle 을 통해 저희 스프링부트 애플리케이션 내에 존재하게 되었으므로, 아래처럼 별도의 선언은 하지 않으셔도됩니다!
package io.github.flashvayne.chatgpt.service;
import io.github.flashvayne.chatgpt.dto.ChatRequest;
import io.github.flashvayne.chatgpt.dto.ChatResponse;
public interface ChatgptService {
String sendMessage(String message);
ChatResponse sendChatRequest(ChatRequest request);
}1차 실행결과
이렇게까지 만드시고 API 테스트를 진행해봅시다. 그러면 아래와 같이 ChatGP 에게 질문을 보내게되고, 그에맞는 대답을 Response 로 받을 수 있는 모습을 확인할 수 있습니다.
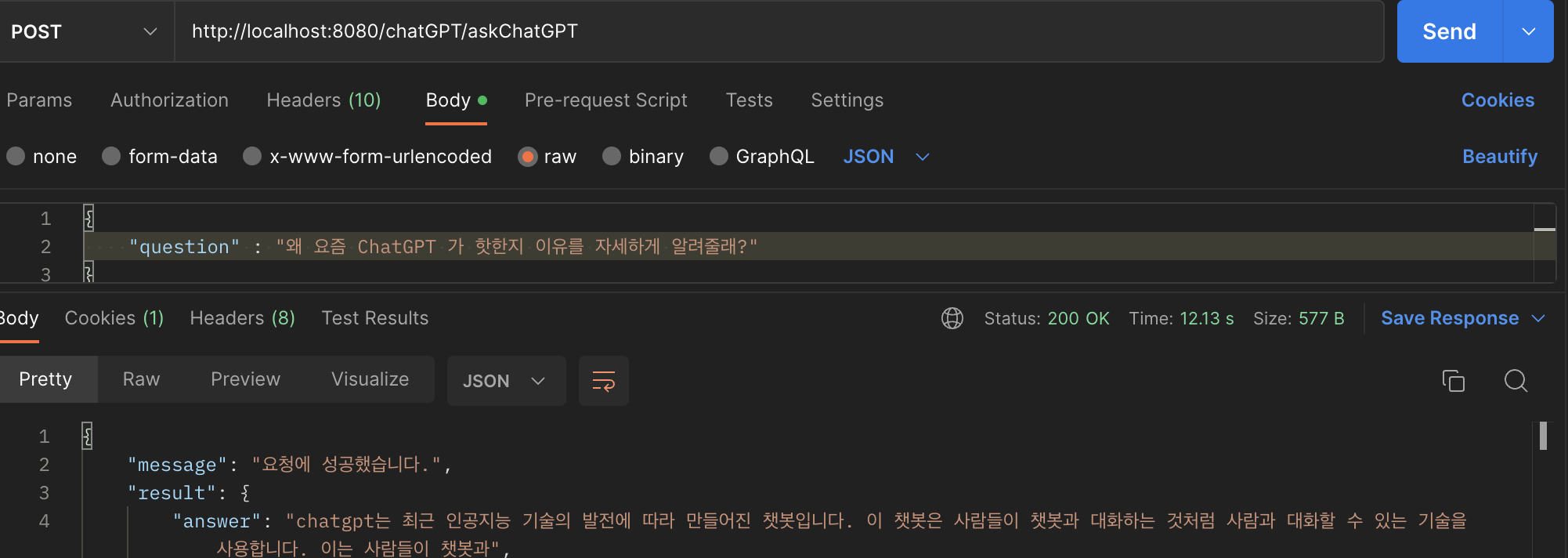
{
"message": "요청에 성공했습니다.",
"result": {
"answer": "chatgpt는 최근 인공지능 기술의 발전에 따라 만들어진 챗봇입니다. 이 챗봇은 사람들이 챗봇과 대화하는 것처럼 사람과 대화할 수 있는 기술을 사용합니다. 이는 사람들이 챗봇과",
}
}Response 개선하기 : Parsing 진행
그런데 조금 아쉬운 점이 하나 있습니다. chatGPT 로 부터 Response 로 받은 대답 내용이 중간에 조금 잘려있죠? 이는 저희가 gradle 에서 의존성 주입한 내용에서 설정된 내용중에 max_token 값이 300으로 제한되어 있기 때문입니다.
이대로 끝나면 너무 부자연스러우니, 성능을 더 개선해봅시다. 저희는 크게 2가지 타이틀을 가지고 성능을 개선해 볼겁니다. 이번에는 2가지 중에 하나만 진행하고, 나머지는 추후 새로운 포스팅으로 다루어볼까 합니다. (다뤄야하는 내용이 너무 길어서, 나중에 다루어볼까 합니다)
문자열 파싱
문자열 파싱을 진행해, 적절한 문장 개수(2개)로 대답을 끊어줍시다.
즉 chatGPT 로 부터 Response 로 받는 문장의 수가 2개 이상일때, 앞에서부터 2개의 문장만 대답으로 받을 수 있도록 하는 것이죠. (2개의 문장 뒤의 여러 문장들은 Response 에서 제외하는 것 )
max_token 값을 직접 조정하기
말그대로 max_token 옵션을 직접 조정할겁니다. chatGPT 의 대답이 중간에 부자연스럽게 끊기는 것 없이, chatGPT 의 대답 길이 제한을 대폭 늘려주는 것이죠.
단, 이 방법은 경우에 따라 chatGPT 의 대답 내용이 지나치게 길 경우에 대답 길이의 제한이 대폭 늘어납니다. 따라서 응답받는 속도가 더 늘려질 수 있다는 단점이 존재하긴 합니다.
ChatGptService 문자열파싱 기능추가
다음과 같이 기존 Service 의 성능을 개선해줍시다. 보시듯이 splitMessage 라는 새로운 메소드가 추가되었습니다.
@Service
public class MyChatGPTService {
private ChatgptService chatgptService;
@Autowired
public MyChatGPTService(ChatgptService chatgptService){
this.chatgptService = chatgptService;
}
public ChatGptRes getChatResponse(String prompt) throws BaseException {
try {
String resultMessage = chatgptService.sendMessage(prompt);
String splitResultMessage = splitMessage(resultMessage);
return new ChatGptRes(splitResultMessage, category);
} catch (Exception exception){
throw new BaseException(BaseResponseStatus.SERVER_ERROR);
}
}splitMessage
문자열 파싱을 진행하는 메소드입니다. 문장 단위를 구분짓기 위해 점 "." 을 기준으로 한 문장씩 잘라줬으며, 잘라진 각 문자열은 tempArr 이라는 문자열 배열에 할당되도록 했습니다.
또 앞에서부터 2개의 문장을 resultArr 문자열 배열에 할당해줬으며, 배열의 각 문장을 하나로 합쳐서 리턴시켜주는 로직을 구현해줬습니다.
public String splitMessage(String message){
String[] tempArr = message.split("[.]");
String[] resultArr = new String[tempArr.length];
for(int i=0; i< 2; i++){
resultArr[i] = tempArr[i];
}
String res = String.join(".", resultArr);
String splitResult = res.replace(String.valueOf("null"), "");
String realSplitResult = splitResult.substring(0, splitResult.length() - 1);
return realSplitResult;
}
}마치며
지금까지 ChatGPT를 애플리케이션에 적용시켜서 직접 Response 까지 받을 수 있는 방법에 대해 자세히 다루어봤습니다.
앞서 언급드렸듯이, 추후 포스팅에서는 max_token 값을 직접 조절하여 ChatGPT 로 부터 받는 응답값을 자유롭게 조절하는 과정을 다루어보겠습니다. 또 그 과정속에서 어떤 로직을 통해 ChatGPT 로 부터 응답값을 받을 수 있는 것인지 자세히 이해할 수 있도록 다루어볼까 합니다. 😉
참고
OpenAI Documentation 오픈AI ChatGPT 사용후기 How to Use ChatGPT in Springboot Project Easily chatgpt-spring-boot-starter How does ChatGPT have such massive token limit?