시작에 앞서
매번 Redis 를 깊이있게 학습해야겠다 다짐만 하다가 드디어 학습을 시작하게 되었네요! Redis 의 내부구조부터 동작원리까지 자세하게 소개해볼까 합니다.
Redis 란?
Redis 란 key-value 구조의 비정형 데이터를 저장하고 관리하기 위한 비관계형 데이터베이스 관리 시스템(DBMS) 입니다.
데이터베이스, 캐시, 메시지 브로커로 사용되며 인메모리 데이터 구조를 가진 저장소이죠. 오픈소스로써 NoSQL 로 분류되기도 합니다.
또 Redis 는 Remote Dictionary Server 의 약자로써 외부에서 사용 가능한 key-value 쌍의 해시 맵 형태의 서버라고 생각할 수 있습니다. 따라서 별도의 쿼리문 작성없이 key값으로 빠르게 결과를 가져올 수 있습니다.
- Remote : 외부
- Dicitionary : 딕셔너리 자료구조
- Server : 서버 =>딕셔너리 자료구조 형태를 사용하는 외부에 존재하는 서버
Cache, Memory Hierarchy
이제 본격적으로 Redis 에 대해 자세히 살펴봅시다. 우선 Redis 는 In-memory Database 로써 캐시(Cache) 영역에 존재하는 데이터베이스입니다.
Memory Hierarchy
캐시(Cache) 라는 영역이 무엇인지 이해하려면 우선 메모리 계층에 대해 알아야합니다. 메모리는 아래처럼 크게 4자기의 메모리 계층구조로 이루어져있죠.
아래 계층구조를 보면 각 계층의 메모리는 위로 갈수록 빠르고 비싸며, 아래로 갈수록 느려지고 저렴한 메모리 저장소라는 특징이 있습니다.
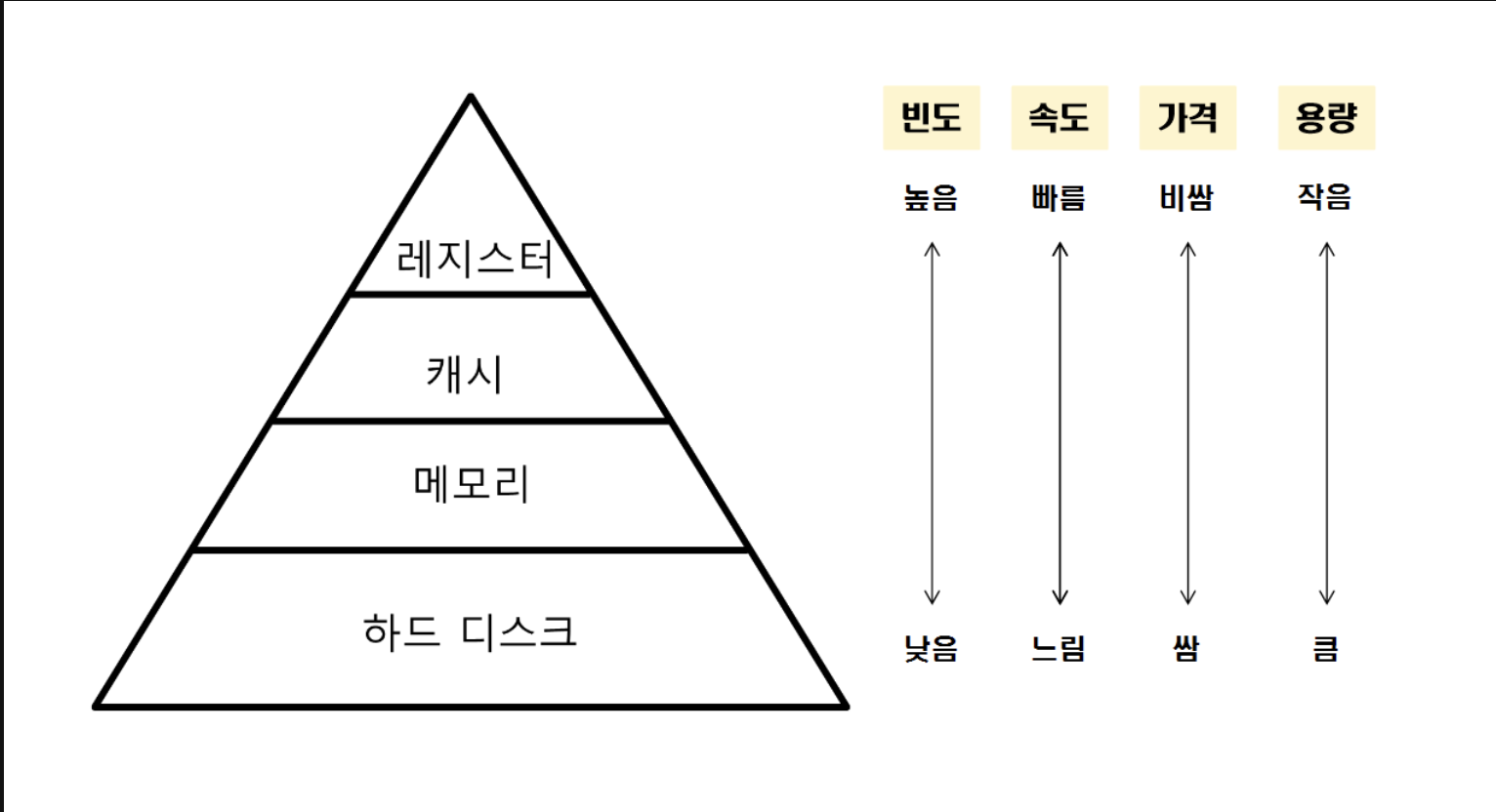
- Main Memory(DRAM) : 비교적 빠르고 적당한 크기 + 휘발성
- Disk(SSD, HDD) : 비교적 느리고 엄청 큰 크기 + 비휘발성
Cache (In-memory Database)
기본적으로 데이터베익스는 컴퓨터가 꺼지더라도 데이터를 저장해야하므로 SSD(디스크) 에 데이터를 저장합니다. 즉 데이터베이스의 데이터에 접근하려면 시간이 조금 느린것이죠.
이때 데이터베이스 보다는 더 자주 접근하고 덜 자주 바뀌는 데이터를 Memory(메모리) 상에 저장해서 빠르고 쉽게 접근하자는 개념에서 등장한 것이 바로 In-memory Database(Cache) 인 Redis 입니다.
Redis 의 필요성
private final Map<String, Object> redis = new HashMap<>();그런데 자바에서 이런 HashMap 을 데이터베이스로 사용해서 저장해도 memory 데이터베이스이지 않을까요? 따라서 Redis 가 아닌 자바의 HashMap 을 사용해도 되지 않나라는 생각이 들 수 있습니다.
그러나 자바를 데이터베이스로 택했을때 다음과 같은 문제점이 발생합니다.
Consistency (일관성) 문제
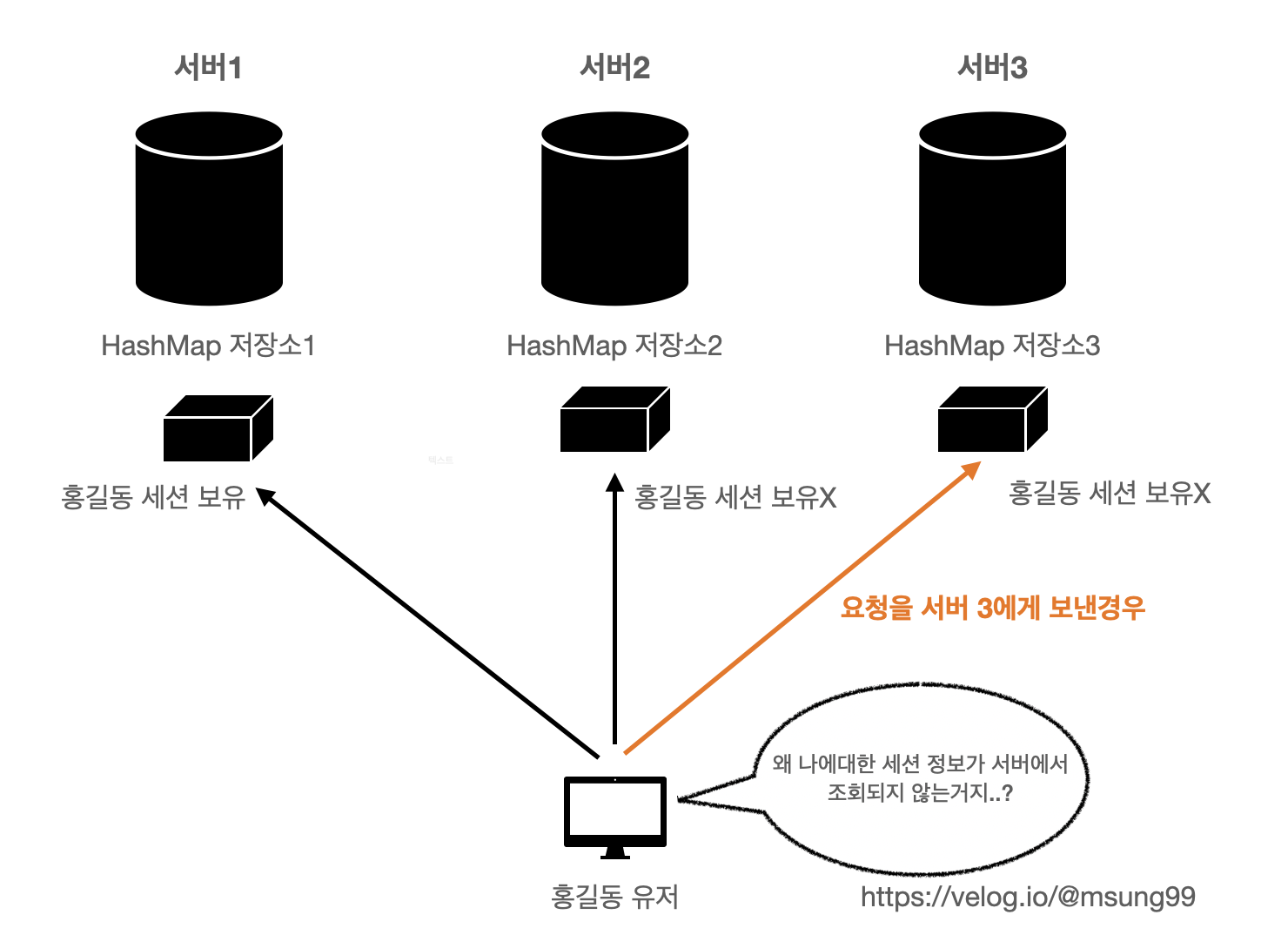
자바 HashMap 을 사용시, 서버가 여러대인 경우 각 HashMap 각자 다른 데이터를 보유하고 있기 때문에 Consistency 문제가 발생합니다. 실제로 Session(세션) 같은 것들을 이렇게 자바의 객체로 저장한다면 다른 서버에서는 해당 세션이 없으므로 문제가 발생할 수 있죠.
Race Condition 문제
또 멀티 쓰레드 환경에서 Race Condition 문제가 발생할 수 있습니다.
특정 코드 묶음이 있다고 하죠. 그 묶음에는 Write 연산을 해야하는 명령어가 여려개 존재하는데, 그 코드를 어떤 프로세스나 쓰레드가 실행하는가에 따라 결과가 달라지는 상황을 Race 이라고 합니다.
여러개의 쓰레드가 경합하면서 Context Switching 이 주기적으로 발생하다보면 원치않은 결과가 발생하는 것입니다.
Race 라는게 이해가 잘 안가요!
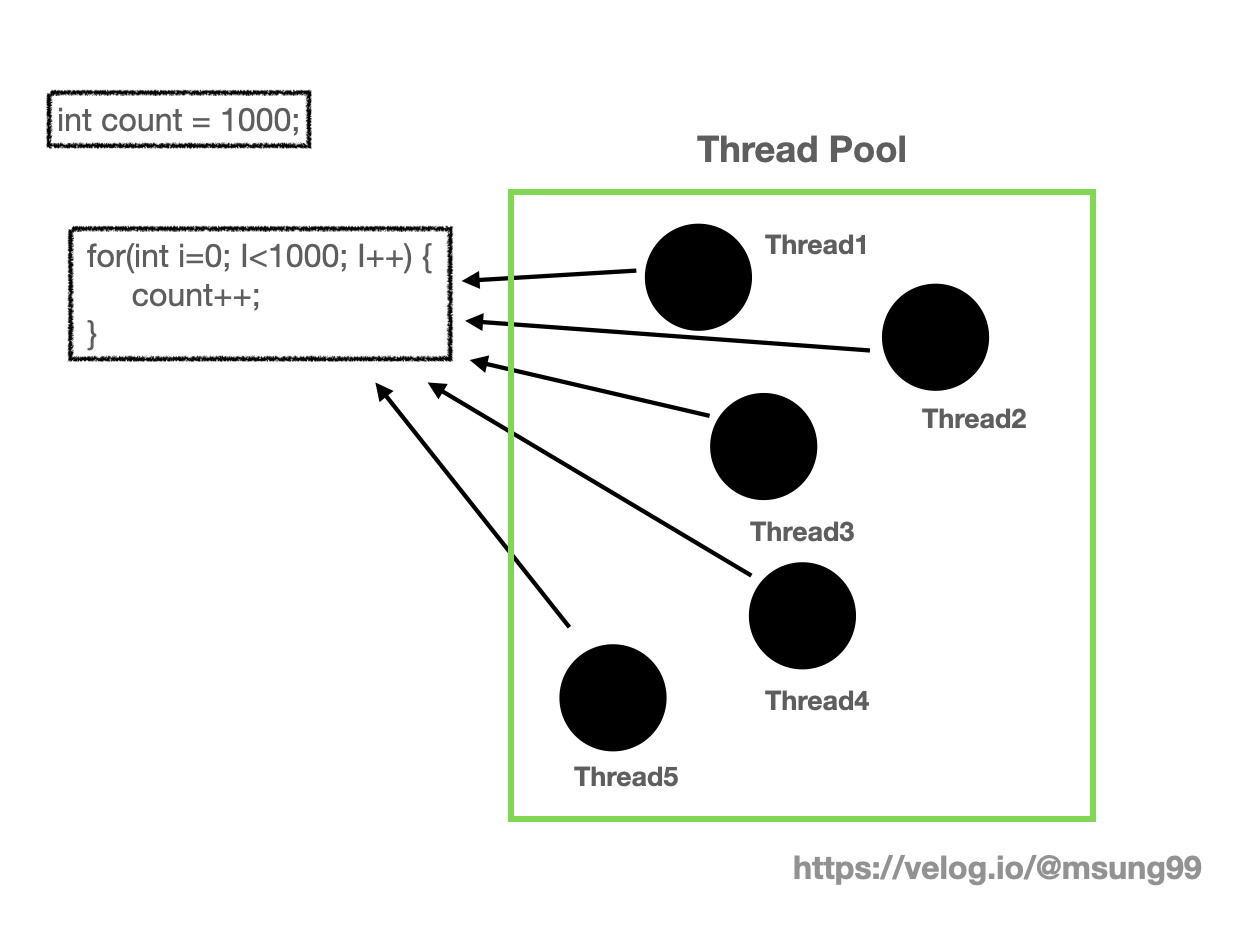
예를들어 위와같은 멀티 쓰레드 환경이 있다고 해봅시다. 멀티 쓰레드 환경에서는 모든 쓰레드들이 같은 코드를 공유하는 상황입니다. 그런데 위와같은 for문을 실행할경우 저희가 원하는 count 변수의 결과값은 6000 으로 변하길 원하나, 막상 실제 결과값은 6000 이 안될수도 있다는 것입니다.
count 라는 것이 전역변수라면 모든 쓰레드들이 함꼐 공유하는 변수가 됩니다. 따라서 어떤 한 쓰레드가 count 값에 대해서 write 연산 (count++) 연산을 하고있는 도중에 다른 쓰레드들도 동시에 write 하려고 하는 상황이 발생한다면 정상적으로 count 변수에 대해 write 연산이 반영되지 않는것이죠.
좀 더 풀어쓰자면, 현재 count 값이 2000 인 상황을 가정해봅시다. Thread1 이 count++ 연산(write)을 진행하고 저장(save) 을 하기 이전에, 그 사이에 Thread2 가 count++ 연산을 진행해버린다면 2001 아닌 2000 이라는 값에 대해서 또 연산을 진행해버리는 상황이 발생해버리는 것입니다. 즉, 저장을 아직 못해서 count 변수가 아직 값이 1이 증가하지 못한 상황에서 1증가 연산을 또 다른 쓰레드가 하려고하니 결과값이 비정상적으로 도출되는 것이죠.
싱글 쓰레드, Critical Section 동기화 환경 제공
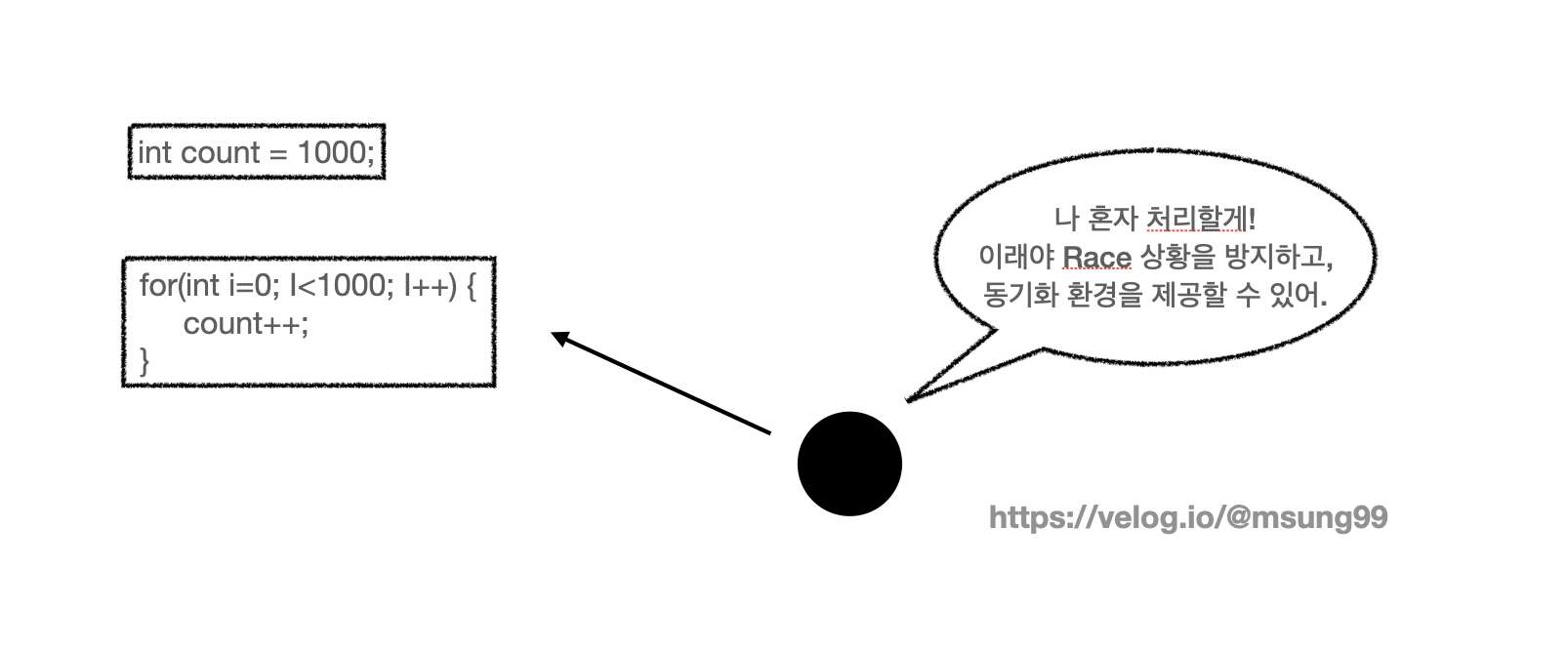
위와 같은 Race 상황을 방지하도록 Redis 는 싱글 쓰레드(Single Thread) 환경에 기반하여 동작합니다. 또 Redis 의 자료구조는 Cirtical Section 이라는 영역에 대해 동기화(Synchornization) 환경을 제공해줍니다.
Critical Section 이란?
Critical Section 이란 동시에 여러 프로세스가 접근하면 안되는 영역입니다. 여러 Read, Write 연산들에 대한 동기화를 시켜줌으로써 Race 와 같이 원치않는 결과를 막아주도록 Redis 의 자료구조가 구현되어 있습니다.
Redis 를 언제쓰지?
세션과 같은 여러 서버에서 같은 데이터를 공유해야하는 상황에서 사용하면 됩니다.
또한 몰론 단일 서버 1개이더라도 캐시(Cache) 의 기능으로 빠른 연산 및 접근이 가능하도록 사용할 수도 있죠.
Redis 사용시 주의점
앞서 언급드렸듯이 Redis는 Single Thread 서버 환경에서 동작하므로 반드시 시간 복잡도를 고려해서 사용해야 합니다.
1) O(n) 시간복잡도가 걸리는 상황
만일 Redis 에서 제공하는 기능중에서 특정 데이터를 찾는 연산을 사용한다고 해봅시다. 그렇다면 처음부터 차례대로 모든 원소들을 다 뒤져봐야할텐데, 이 경우는 최악의 경우에 O(n) 시간이 걸리겠죠? 1천만개의 데이터가 있다고 하면, 1천만개에 대해 모두 연산을 해야하는 것이라 시간이 오래걸릴겁니다.
대표적으로 모든 key 를 가져오는 연산이나, Flush, GetAll 과 같은 명령어들이 이에 해당합니다. 모든 데이터를 다루는 연산이므로 주의해야겠죠?
2) 서버가 다운되는 상황
Redis 는 네트워크로부터 요청을 받아서 명령어를 처리하는데, O(n)이 걸리는 명령어를 실해아고 처리하는 과정이 싱글 쓰레드 방식입니다. 때문에 이 명령어가 오랜 시간이 걸릴경우 나머지 요청들이 모두 거절되고 서버가 다운되는 상황이 발생할 수 있습니다.
3) Memory Fragmentation
또한 Redis 사용할시 메모리 단편화(Memory Fragmentation) 문제를 고려해서 메모리를 적당히, 여유롭게 사용하는것이 좋습니다.
Memory Fragmentation 에는 크게는 2가지로 나뉩니다. Internal Fragmentation, External Fragmentation 으로 나뉘는데, 저희는 External Fragmentation 를 중점으로 알아보겠습니다.
External Fragmentation
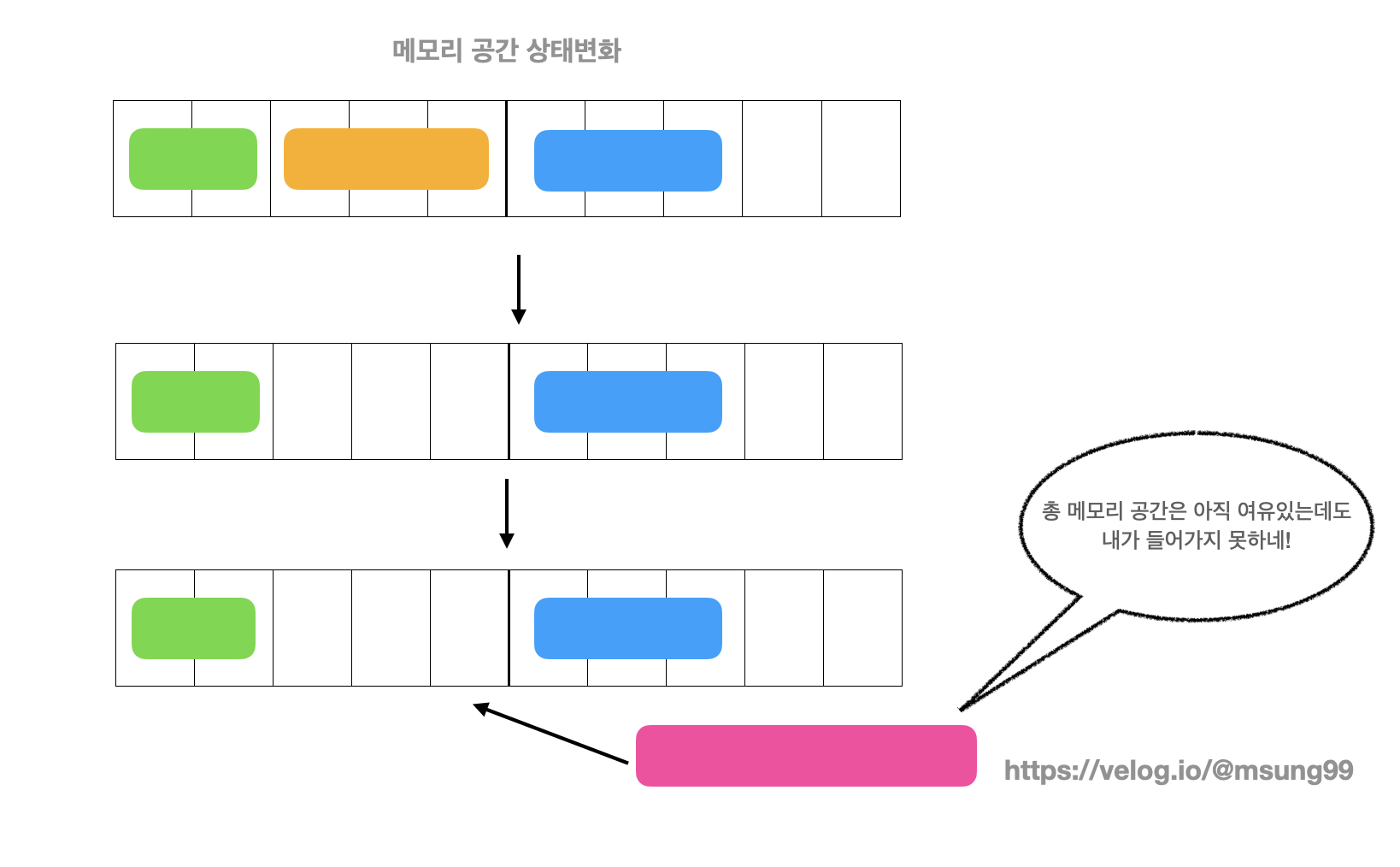
메모리 단편화, 즉 External Fragmentation 이란 할당된 메모리 사이의 중간중간에 사용하지 않는 작은 메모리 공간이 여럿 생겨나게 되어, 총 메모리 공간은 충분하지만 실제로는 더 많은 데이터를 할당할 수 없는 현상을 의미합니다.
위와 같이 메모리 공간이 아직 여유가 있는데도, 핑크색 데이터가 들어갈 수 있는 공간이 없습니다. 이렇게 빈공간이 중간중간에 생겨서 그런것입니다.
이런 문제 때문에 실제 사용하는 것보다 더 많은 메모리를 사용하고 있는거처럼 컴퓨터가 인식하고 이 과정에서 프로세스가 죽는 현상이 발생할 수도 있습니다. 실제로 사용하는 공간보다 더 많은 메모리를 사용하고 있는 것처럼 컴퓨터가 인식하고 이 과정에서 프로세스가 죽는 현상이 발생할 수도 있는 것이죠.
4) Replication : Forking
마지막으로 레플리케이션입니다. Redis 는 아까 말했듯이 휘발성을 가지고있는 메모리상의 데이터 저장소이므로 항상 데이터가 유실될 문제를 염려해야합니다.
이 문제를 해결하도록 Redis 는 데이터 복사 기능(Forking) 을 제공합니다. 부모 프로세스(Redis-Server) 에서 자식 프로세스(Child-Process) 로의 Forking 기능을 제공하는 것이죠.
Redis 서버의 데이터를 복사해서 디스크와 같은 곳으로 전송해서 저장하는 방식입니다. 이때 Redis 서버의 프로세스를 동일하게 복제하여(Forking) 메모리 상에서 복제한 후 사용하는 방식을 사용하는데, 이 과정에서 메모리가 가득 차있다면 이 복사본이 제대로 생성되지않고 서버가 다운되는 현상이 발생할 수 있습니다.
따라서 이런 Forking 연산 사용시에 메모리를 반드시 여유있게 확보해야 서버가 다운되는 현상을 방지할 수 있다는 점을 유의하는 것이 좋겠죠?
마치며
지금까지 Redis 의 자세한 내부 메커니즘에 대해 살펴봤습니다. CS 지식이 많이 요구되는 내용이였는데, 이해가 잘 안되시는 부분이 있다면 충분한 CS 학습을 하신후 다시 읽어보시는 것을 권장드립니다!
참고
Redis Document [OS] 메모리 계층 구조(Memory Hierachy) Redis 요약 정리 [데이터베이스] Redis란? [AWS] Redis란 무엇입니까?