자바의 동시성 제어 키워드 : volatile 과 synchornized
volatile 과 가시성
volatile 키워드를 사용하면 멀티 쓰레드 환경에서 모든 쓰레드들이 CPU 메인 메모리의 동일한 변수를 공유할 수 있게됩니다.
CPU Cache
가시성과 volatile 를 이해하기 위해선 CPU Cache 에 대해 먼저 이해해야합니다. 이를 위해, 멀티코어 CPU 환경에섯 저희는 공유자원 count 를 동시에 2개의 쓰레드가 변경하는 경우에 대해 생각해볼 겁니다.
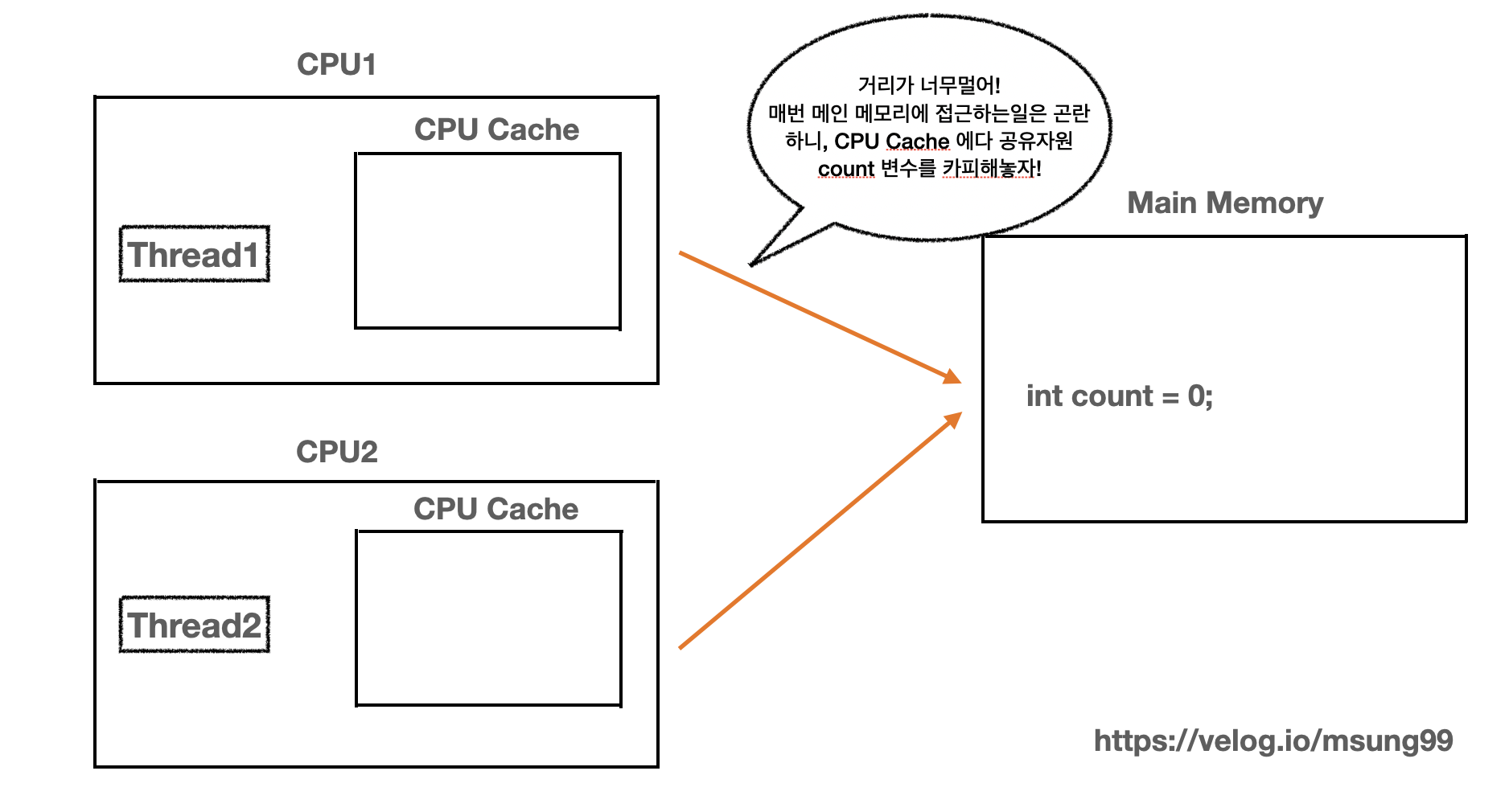
우선 쓰레드를 실행하는건 CPU가 실행합니다. 쓰레드를 CPU가 실행할 때 메인 메모리에서 변수 값을 읽어오는데, 메인 메모리와 한 CPU 사이의 거리가 멀어서 매번 리소스(공유자원)을 획득하려고 접근하는건은 번거롭습니다. 따라서 CPU 내부에 CPU Cache 를 생성하고 공유자원을 카피해서 캐싱해놓는 방식입니다.
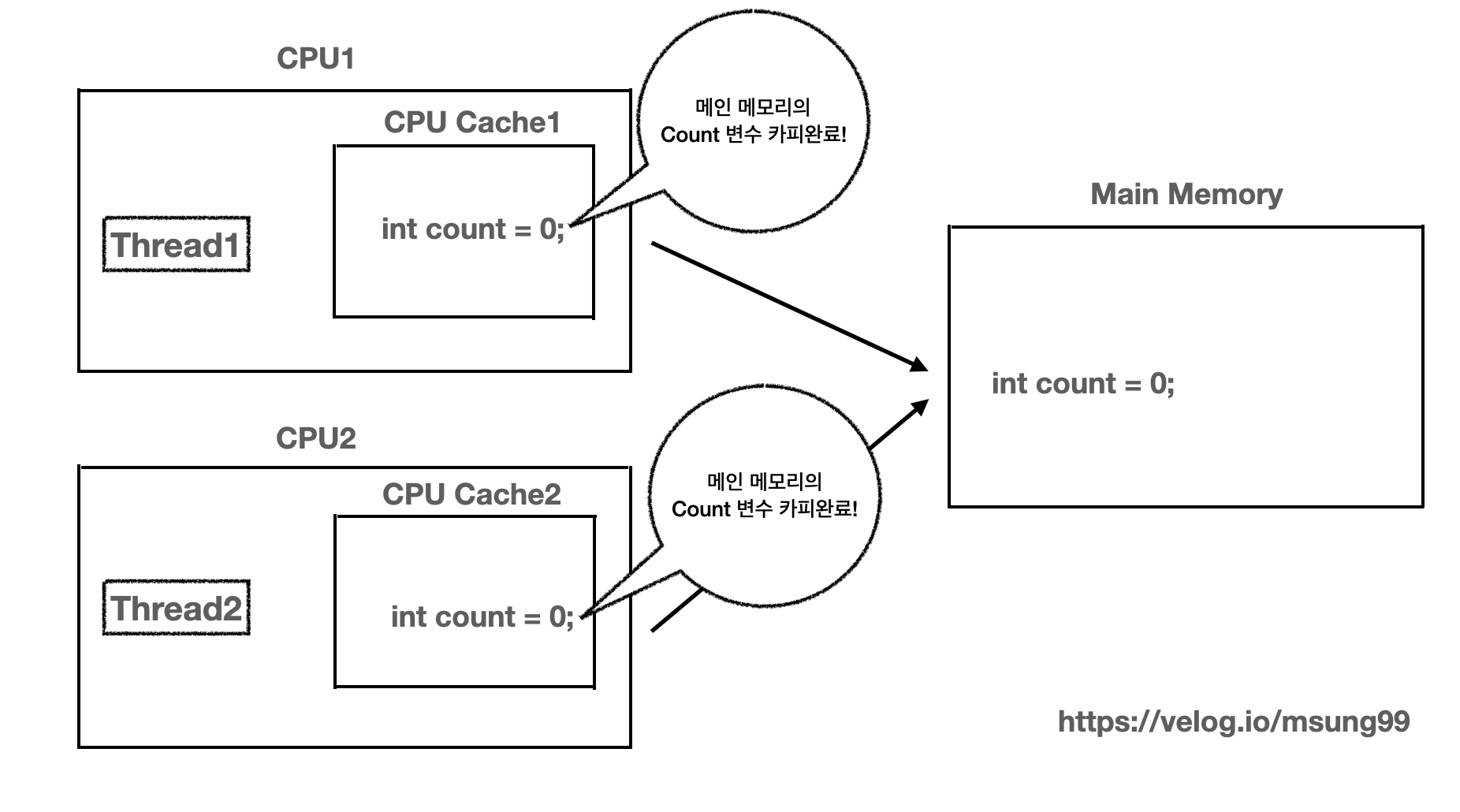
더 자세히 풀어써보면, 쓰레드1 을 실행할 CPU 는 쓰레드를 실행할때 필요한 값을 메인메모리에서 카피해와서 CPU 캐시에 담아두고, 쓰레드 1에게 CPU 캐시에 카피해둔 자원에 대한 연산을 진행하도록 지시합니다. 그러고 CPU1 의 Cache에 카피해둔 자원에 대해 모든 연산을 반영한 다음, 캐시에 최신화된 값을 메인 메모리에도 반영시켜줍니다.
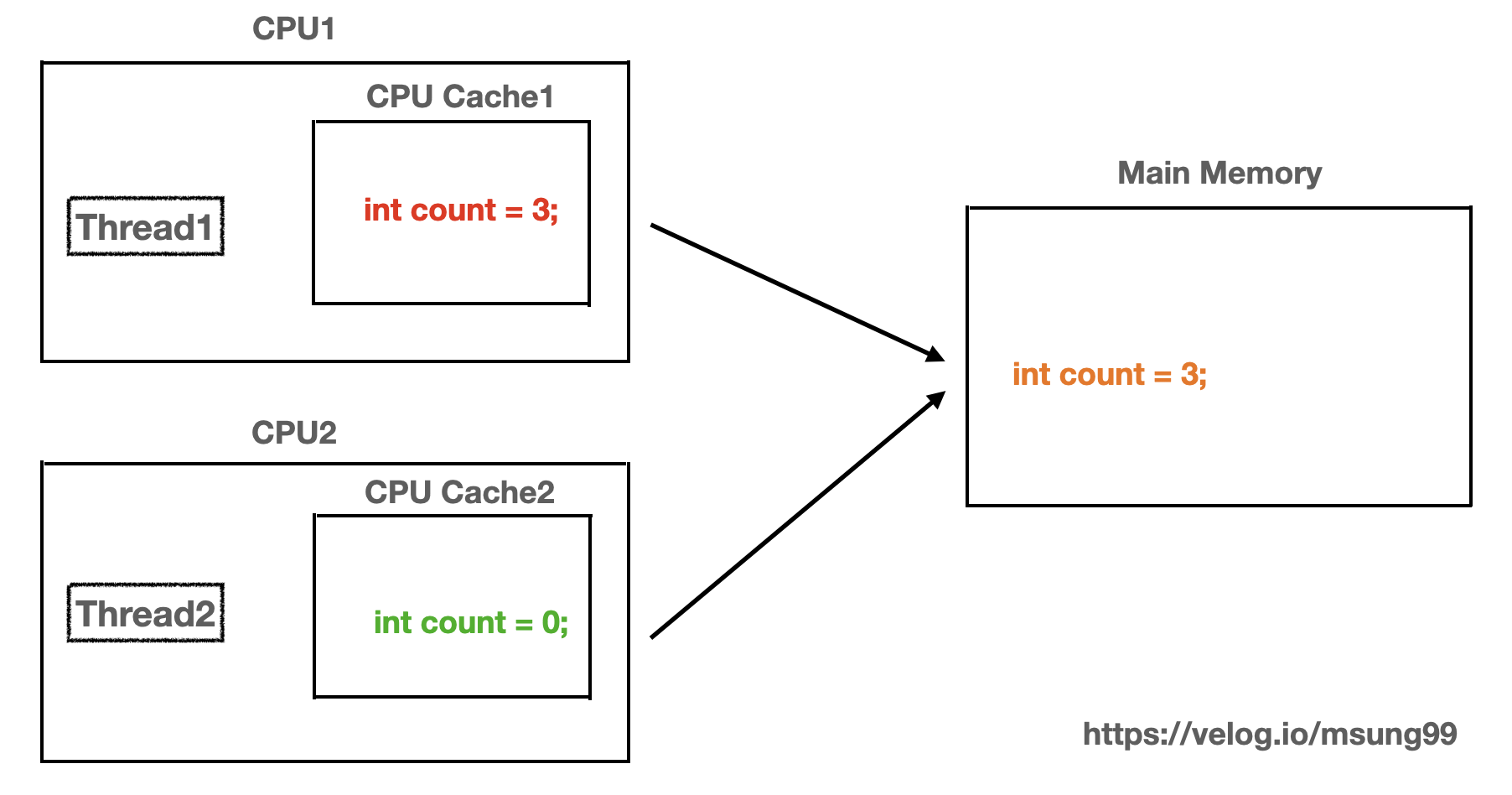
그런데 여기서 문제가 발생할 수 있습니다. 만약 CPU Cache1 이 최신화한 공유자원 값(count = 3)을 메인메모리에도 반영하기 이전에 CPU Cache2가 구버전 값(count = 0) 을 읽어올 수도 있습니다. 즉, CPU2에 대한 쓰레드인 Thread2 는 최신화되기 이전에 구버전 count 값을 기반으로 연산을 진행할 수도 있는 것입니다.
volatile
volatile 키워드를 사용해서 CPU 메모리 영역에 캐싱된 값이 아니라 항상 최신의 값을 가지도록 메인 메모리 영역에서 값을 참조하도록 할 수 있습니다. 즉, 각 CPU 의 쓰레드가 가진 CPU Cache 에다 캐싱을 하는것이 아니라, 모든 쓰레드가 공유하는 메인 메모리에서 읽고 쓰는 연산을 진행하도록 하는 방법입니다.
public class MyClass {
public volatile int counter = 0; // 이렇게 volatile 키워드를 공유변수에
// 사용하면 멀티 쓰레드 환경에서 메인메모리의 변수를 공유할 수 있습니다.
private void Mytest() {
// ... (비즈니스 로직)
}
}volatile 은 언제쓸까?
앞서 말했듯이, volatile 키워드로 변수를 선언해서 여러개의 쓰레드에서 공유할 수 있도록할 때 사용하면 됩니다. 그러나 주의할점은, Volatile 은 Write 를 하나의 쓰레드에서만 할때 유용하고 여러 쓰레드에서 Write 한다면 부적절합니다. 지난번에 살펴봤던 경쟁상태인 Read-Modify-Write 패턴이 발생하 수 있기 때문이죠. 여러개의 변수가 동시에 읽고 그 시점을 기준으로 데이터를 변경할 때 혼란이 생기기 때문입니다.
아래에서 설명드릴 synchronized 와 비교해볼 경우 동기화 이슈로 인해 volatile 대신에 synchronized 키워드를 사용하면 되지 않나? 라는 생각이 들수 있습니다. 하지만 synchronized 를 사용할경우 대규모 서비스에서 심각한 성능저하가 생긴다는 장점이 생기므로, 상황을 적절히 고려하여 어떤걸 사용할지 결정해야합니다.
synchronized
synchronized 를 사용하면 값을 변경하기 위해 읽고-저장하는 연산(비-원자적 연산)은 동시간에 하나의 쓰레드만 처리할 수 있도록 일종의 락을 거는 방법입니다. 경쟁상태를 방지하는 가장 안전한 방벙이지만, 앞서 설명했듯이 서비스에 트래픽이 발생할 경우 심각한 성능 저하가 발생할 수 있다는점에 유의합시다.
synchronized 키워드의 경우 synchronized 블록에 진입하기 전에 CPU 캐시 메모리와 메인 메모리 값을 동기화하여 가시성을 해결합니다.
private static long number = 0;
public static synchronized void MyFunction(){
number++;
System.out.println(number);
}배타적 실행(동기화)
이렇듯 synchronized 키워드를 붙여서 동시에 하나의 쓰레드만 진입할 수 있도록 하는 것을 배타적 실행(동기화)라고 합니다.
통신 동기화
또 synchronized 는 단일 쓰레드만 진입하도록하는 배타적 실행뿐만 아니라, 메인 메모리에서 가장 최근의 값을 가져오는 동기화 가능도 함께 수행합니다.
volatile VS synchronized
volatile 만으로 동기화 되는 상황이라면 synchronized 보다는 volatile 만으로 동기화 처리르 하는것이 낫습니다. 배타적 실행을 위해 락을 획득하고 반환하는 비용이 발생하지 않기 때문이죠. 반면 배타적 실행이 필요하다면 synchronized 를 사용하면 되겠죠?
Atomic variable
추가적으로 Atomic 변수(AtomicInteger, AtomicLong, AtomicBoolean 등)을 사용하면 CAS(compare-and-swap)알고리즘을 이용해서 synchronized보다 효율적으로 동시성 및 원자성을 보장합니다. 멀티쓰레드에서 write도 가능합니다.
보통 synchronized 를 사용하여 해당 블럭 전체를 블로킹(blocking) 해버리는데, 이 경우 다른 쓰레드는 아무런 작업을 하지 못하고 기다리는 상황이 발생할 수 있어서 낭비가 심합니다. 따라서 논블로킹(Non Blocking) 하면서 동기화 문제를 해결하기 위한 방법이 Atomic 입니다.
CAS 알고리즘은 쓰레드가 가지고 있던 원래 값이 현재의 값과 같은 지 비교하고, 같으면 그냥 사용하고 다르면 현재의 값을 받아옵니다. 그래서 asynchronized보다 훨씬 작은 범위에 Lock을 걸 수 있게되고, volatile의 문제를 해결할 수 있습니다.
public class MyClass {
private static AtomicLong number = new AtomicLong(0);
// AtomicLong, AtomicInteger, AtomicBoolean, ...
public static void MyFunc() {
for(int i=0; i<1000; i++){
number.set(number.get() + 1);
// 또는 number.incrementAndGet();
System.out.println(number);
}
}
}만약 위 코드를 동시에 2개의 쓰레드가 실행시킬때, 변수가 atomic 변수가 아닌 일반 정수형 변수 int 였다면 동기화가 지켜지지 않았을겁니다.
CAS 알고리즘
CAS 를 알고리즘은 앞서 살핀 volatile 키워드의 성능을 조금 더 개선시킨 것입니다. volatile 의 문제점은 메인메모리의 저장된 값과 CPU 캐시에 저장된 값이 다른 경우가 발생할 수 있다는 점이죠.
이 방식은 현재 쓰레드에 저장된 값과 메인 메모리에 저장된 값을 비교하여 일치하는경우 새로운 값으로 교체되고, 일치하지않는다면 실패하고 무한 루프를 돌면서 일치할 때 까지 재시도합니다.
atomic variable VS synchornized
atomic 변수가 활용하는 CAS 알고리즘은 원자성뿐 아니라 가시성 문제도 해결해주는 것을 볼 수 있습니다. 또한 non-blocking 이 가능하므로 blocking 방식인 synchornized 보다 성능상 이점이 있죠.
참고
[Java] atomic과 CAS 알고리즘 자바 동기화 처리 - volatile 와 synchronized Java - Atomic Variable (+ 동시성 제어 비교 with volatile, synchronized) [10분 테코톡] 알렉스, 열음의 멀티스레드와 동기화 In Java