캐시 (Cache)
캐시는 서버의 부하를 감소하고 성능을 높이고자 사용되는 기술입니다. DB 에서조회 및 계산처리를 하는 과정이 복잡하고 시간이 오래걸리는 경우, 캐시에 결과를 저장해두고 추후에 재요청없이 즉시 캐시에서 가져옴으로써 빠른 처리가 가능합니다.
@Cacheable
스프링부트에서는 @Cacheable 이라는 어노테이션을 통한 캐싱 기능을 제공합니다. 캐시는 메소드의 리턴값과 파라미터를 저장할 내용으로 주 타킷으로 삼기 때문에, 보통 메소드 단위로 설정하게 되며 클래스나 인터페이스 레벨에 캐시를 하는일은 드뭅니다.
우선 아래와 같이 의존성을 추가해줍시다.
implementation 'org.springframework.boot:spring-boot-starter-cache'@EnableCaching
다음으로 일반적으로 @EnableCaching 어노테이션은 스프링 부트의 메인 애플리케이션 클래스인 @SpringBootApplication 어노테이션이 지정된 클래스에 추가해줍시다. 이렇게 하면 스프링부트 애플리케이션이 시작될 때 자동으로 캐시가 활성화됩니다.
@EnableCaching
@SpringBootApplication
public class CoreApplication {
public static void main(String[] args) {
SpringApplication.run(CoreApplication.class, args);
}
}Book
간단한 캐시 테스트를 위해, 엔티티 클래스를 간단히나마 정의했습니다.
@Entity
@AllArgsConstructor @NoArgsConstructor
@Setter @Getter
public class Book {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
}BookService
@Service
public class BookService {
private final BookRepository bookRepository;
@Autowired
public BookService(BookRepository bookRepository){
this.bookRepository = bookRepository;
}
@Cacheable(value = "book")
public Book getBookById(Long id, BookReq bookReq) throws InterruptedException {
// ... (데이터베이스에서 데이터 로딩하는 로직)
return new Book(id, "minsung");
}
}캐싱을 위해서 위와 같이 메소드위에 @Cacheable 어노테이션을 붙이면됩니다.
value = "book" 을 부여하면, 서버의 메모리에 book 이라는 이름을 가진 해시테이블을 생성합니다. key 값으로는 파라미터인 id 와 bookReq 로 하고, value 값은 반환값인 Book 객체로 해서 데이터를 캐시에 저장하게 됩니다.
현재 데이터베이스 코드는 생략했지만 findById() 등으로 DB 에 접근해서 데이터를 가져오고, 두번째 조회부터는 캐싱된 데이터를 가지고 즉각 리턴하게됩니다.
로깅을 통해 직접 확인해보기
@Cacheable(value = "book")
public Book getBookById(Long id, BookReq bookReq) throws InterruptedException {
System.out.println("Finding book" + id + " from databases...");
Thread.sleep(5_000); // 데이터베이스 조회 쿼리가 5초 걸린다는 가정
// ... (데이터베이스에서 데이터 로딩하는 로직)
return new Book(id, "minsung");
}위와 같은 코드를 만들어서 캐싱이 잘 되는지를 직접 확인해봅시다. 쓰레드를 5초동안 잠재우도록 했는데, 이는 데이터베이스의 조회 쿼리가 5초 걸린다는 가정과 같은 맥락입니다.
AppRunner
로깅을 위한 AppRunner 라는 클래스를 만들어봤습니다.
@Component
public class AppRunner implements CommandLineRunner {
private static final Logger logger = LoggerFactory.getLogger(AppRunner.class);
private final BookService bookService;
public AppRunner(BookService bookService){
this.bookService = bookService;
}
@Override
public void run(String... args) throws Exception {
BookReq bookReq1 = new BookReq("책1");
BookReq bookReq2 = new BookReq("책2");
logger.info("......Fetching Books........");
logger.info("bookId1 = " + bookService.getBookById(1L, bookReq1));
logger.info("bookId1 = " + bookService.getBookById(1L, bookReq1));
logger.info("bookId1 = " + bookService.getBookById(1L, bookReq1));
logger.info("bookId1 = " + bookService.getBookById(1L, bookReq1));
logger.info("bookId2 = " + bookService.getBookById(2L, bookReq2));
logger.info("bookId2 = " + bookService.getBookById(2L, bookReq2));
logger.info("bookId2 = " + bookService.getBookById(2L, bookReq2));
logger.info("bookId2 = " + bookService.getBookById(2L, bookReq2));
}
}위 코드는 1번 책을 4번 조회하고, 2번 책을 4번 조회하는 코드입니다. 캐싱을 했기 때문에 결과를 예상해보자면 첫번째 조회 결과에서는 5초가 걸릴것이고, 2번째 조회부터는 캐싱된 데이터를 사용하기 때문에 1번, 2번책 데이터를 곧바로 가져올겁니다.
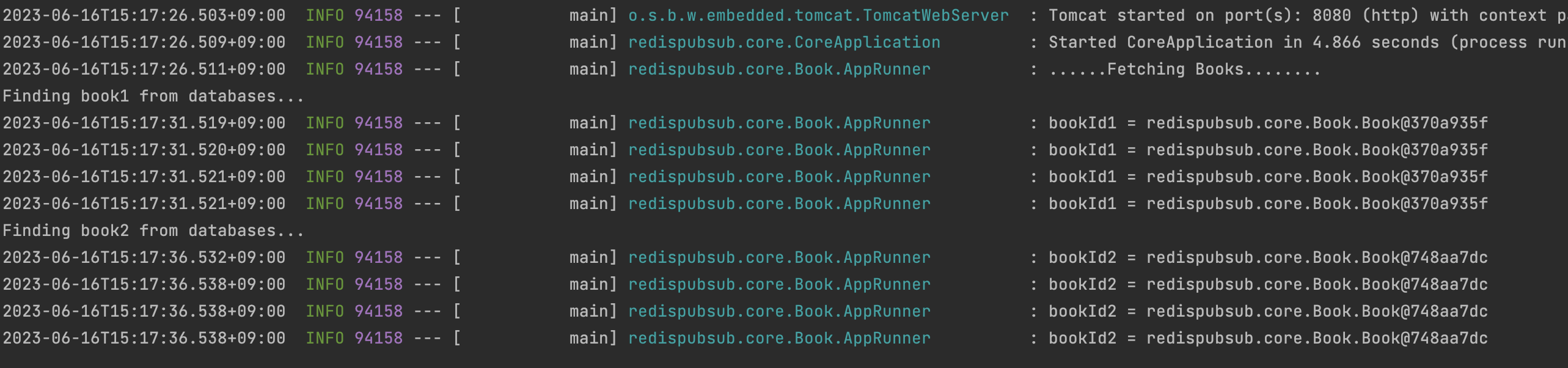
캐싱 결과
그 결과를 보면 아래와 같습니다. 첫번째 조회를 시도할때는 데이터를 얻기위해 5초동안 대기해야하나, 2번째 부터는 매우 빠른 속도로 데이터를 조회할 수 있게됩니다. 또한 보듯이 각 호출 결과를 보면 고작 0.001 초밖에 차이가 나지 않습니다.
@CacheEvict, @CachePut
이 외에도 스프링부트는 캐싱을 위해 @CacheEvict 과 @CachePut 어노테이션을 제공합니다. 앞서 @Cacheable 로 캐싱을 했다면, 반대로 캐싱된 데이터를 캐시에서 삭제하거나 수정하는것도 가능해야할겁니다.
-
@CachePut : @CachePut은 @Cacheable과 유사하게 실행 결과를 캐시에 저장하지만, 조회 시에 저장된 캐시의 내용을 사용하지는 않고 항상 메소드의 로직을 실행한다는 점에서 다릅니다.
-
@CacheEvict : 기본적으로 메소드의 키에 해당하는 캐시만 제거합니다.만약 아래와 같이 메소드에 @CacheEvict를 적용하면 같은 id 값을 가진 데이터만 캐시에서 제거됩니다.
@CacheEvict(value = "book", key = "#id")
public Object deleteBook(Long id) throws InterruptedException {
bookRepository.deleteById(id);
return null;
}
@CachePut(value = "book", key = "#book.id")
public Book updateBook(Book book) throws InterruptedException{
// ... (업데이트 로직)
return bookRepository.save(book);
}옵션 종류
위에서 살펴본 3가지 어노테이션의 원활한 캐싱 기능을 위해, 다양한 옵션들이 존재하니, 추가적으로 알아둡시다.
key
@Cacheable(value = "books", key = "#id")
public Book getBookById(Long id) {
// ...
}캐시의 키를 지정하는 것입니다. 기본적으로 메소드의 매개변수를 기반으로 자동 생성되는데, 사용자가 이 옵션으로 직접 지정도 가능합니다. 위 예시에서 @Cacheable 어노테이션의 key 옵션은 #id로 지정되어 있습니다. 이렇게 하면 메소드의 id 매개변수 값을 기반으로 캐시 키가 생성됩니다.
condition
@Cacheable(value = "books", condition = "#result != null")
public Book getBookById(Long id) {
// ...
}조건문을 지정하며, 조건이 true인 경우에만 캐싱이 수행됩니다. 예를들어, 위와 같이하면 메소드의 실행 결과가 null이 아닌 경우에만 캐싱이 수행됩니다.
sync
@CachePut(value = "books", key = "#book.id", sync = true)
public Book updateBook(Book book) {
// ...
}@CachePut 어노테이션에서 사용되며, 캐시 갱신 작업을 동기 또는 비동기로 수행할지를 지정합니다. 예를들어 위처럼 sync 옵션은 true로 지정하면, 캐시 최신화 작업이 동기적으로 수행됩니다.