학습 및 도입배경
현재 운영중인 서비스가 아직 데이터베이스 구축하기 전 단계에 있습니다. 최근들어 신규 유입 유저가 약 5000명 가량이 늘었는데, 리전이 대한민국 외에도 중국, 미국등 다양한 국가의 유저들이 유입되었습니다. 데이터베이스 서버의 부하를 줄이는 방법으로는 인덱스(Index) 를 비롯한 각종 개선요소가 있겠지만, 그 중 하나로 데이터베이스 레플리케이션(Replication) 을 떠올리게 되었고, 서비스에 도입해보고자 이렇게 학습을 진행합니다.
레플리케이션 (Replication)
데이터베이스의 레플리케이션 (replication) 이란 말그래도 "복재" 하는 해위를 의미합니다. 가용성과 확장성 측면에서는 빠질 수 없는 요소라고 볼 수 있습니다. 트래픽이 증가했을때 인프라에서 수직확장(Scale Up) 만으로는 한계가 있으므로 로드밸런싱 환경으로 수평확장(Scale Out) 환경을 구축해야 하듯이, 부하를 감당하고 가용성과 확장성을 위해선 데이터베이스도 복제가 반드시 필요합니다.
source-replica 구조 (Master/Slave 구조)
기본적으로 DB 레플레키이션 구조에서 원본 데이터를 가진 서버를 source(Master) 라고하며, 복제된 서버를 replica(Slave) 서버라고 합니다. source 서버에 문제가 발생하면 replica 서버를 source 서버로 전환하여 사용할 수도 있고, source 서버를 쓰기전용 DB 로, replica 서버를 읽기전용 DB 로 분리해서 부하를 해결하는등의 다양한 전략으로 구현 가능합니다.
참고로 마스터(Master) 와 슬래이브(Slave) 라는 표현으로도 사용되고 있으나, 최근에는 잘 사용되지는 않는 표현이라고 합니다.
바이너리 로그 기반 복제
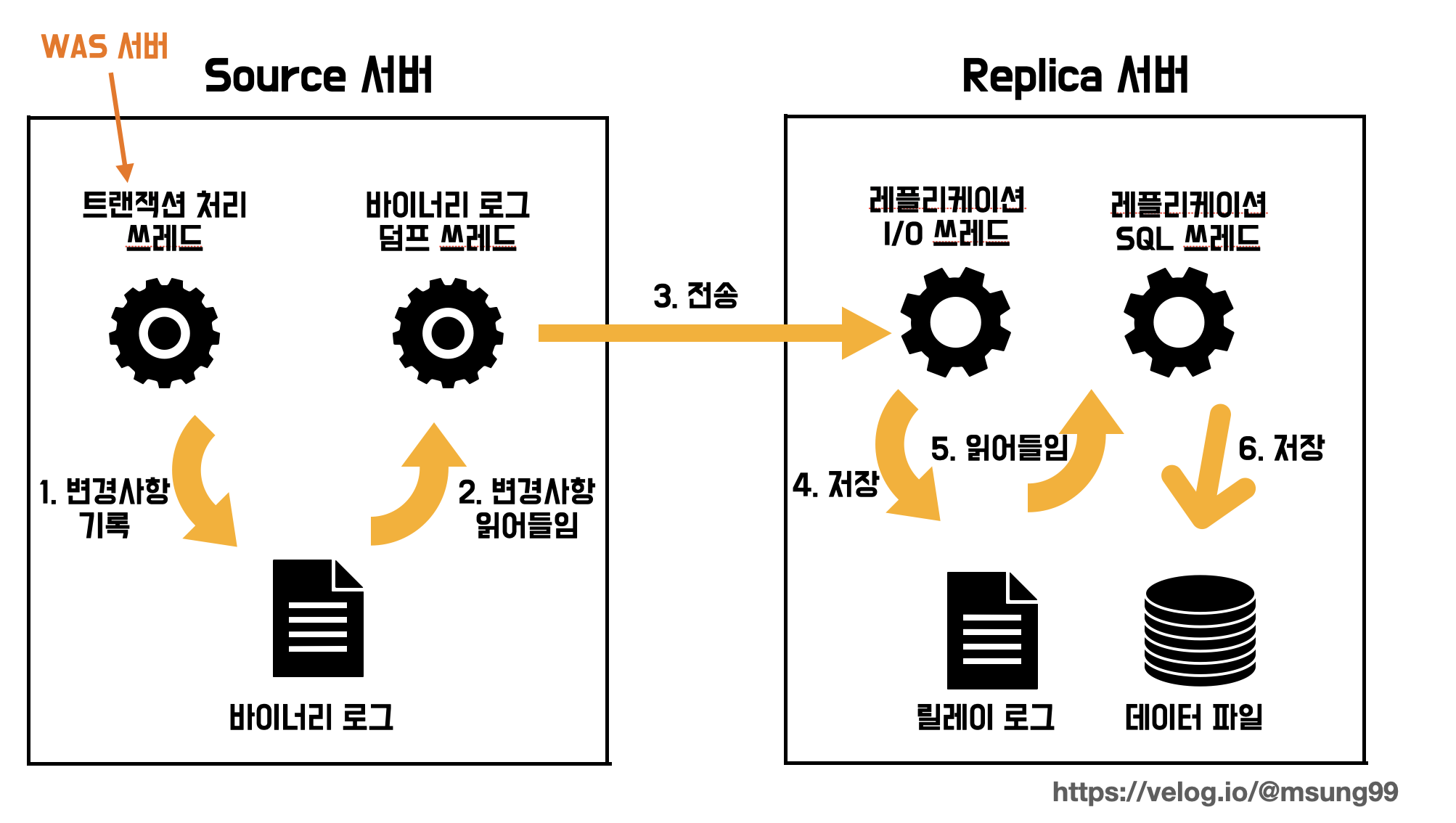
MySQL 의 복제 방식은 바이너리 로그 기반 복제 방식으로 이루어집니다. WAS 서버에서 source 서버로 보낸 변경사항(이벤트) 들은 바이너리 로그 파일에 담기게 되는데, 소스(Source) 서버에 변경사항이 일어나서 바이너리 로그가 기록이 되면 그 이벤트는 레플리카(Replica) 서버가 자신의 로컬 파일에 저장하는 방식입니다.
더 자세히 설명해겠습니다. 우선 트랜잭션 처리 쓰레드를 제외했을떄, 복제 과정에는 3가지 종류의 쓰레드가 참여합니다. source 서버의 바이너리 로그에 이벤트 변경사항이 일어아면 바이너리 로그덤프 쓰레드 가 이 이벤트를 읽어서 레플리카 서버로 전송합니다. 레플리카 서버의 I/O 쓰레드 는 이 변경사항을 자신으 로컬 파일인 릴레이 로그 에 저장합니다. 아직까지는 변경사항이 레플리카 서버에는 반영되지 않은 상태인데, 이를 반영하기 위해 SQL 쓰레드 가 변경내용을 데이터 파일에 저장합니다.
글로벌 트랜잭션 아이디(GTID) 기반 복제
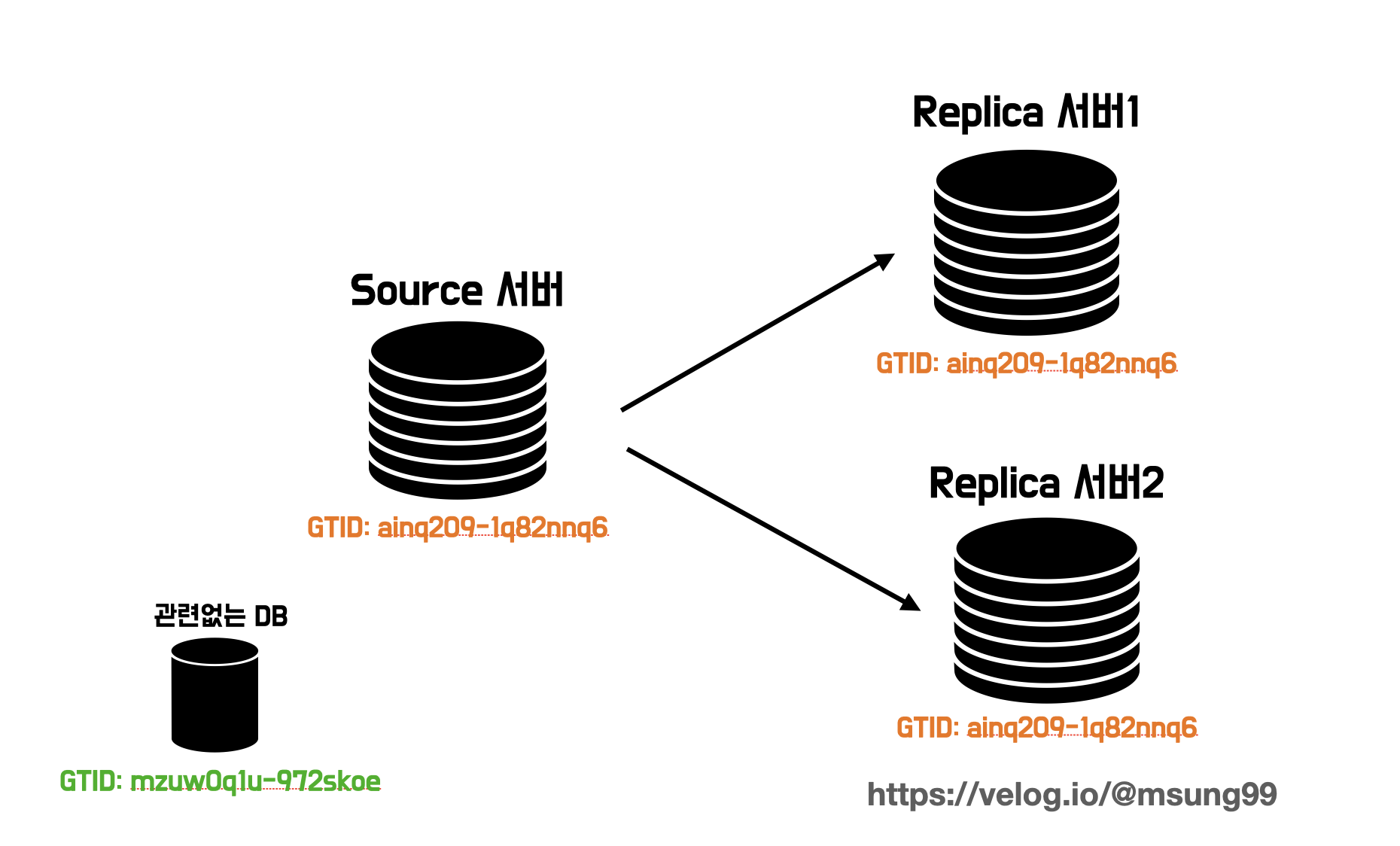
그렇다면 레플리카 서버는 서버의 바이너리 로그에 기록된 변경내역(이벤트) 들을 어떻게 식별해서 반영할지를 살펴보면, MySQL 5.0 이상부터는 글로벌 트랜잭션 아이디 기반 복제(GTID) 방식을 기본으로 채택하고 있습니다.
모든 데이터베이스들은 고유한 식별값을 가지고 있습니다. 그 "식별값" 이란 바로 글로벌 트랜잭션 아이디라는 것인데, 같은 레플리케이션에 참여한 모든 데이터베이스들의 "식별자" 값은 모두 동일합니다. 이 값들이 모두 동일하기 때문에, 동일한 이벤트(변경사항) 에 대해서 같은 값을가진 DB 들만 읽어오면 같은 복제 그룹 대상들에게 변경사항을 동일하게 반영시킬 수 있습니다.
복제 데이터 포맷
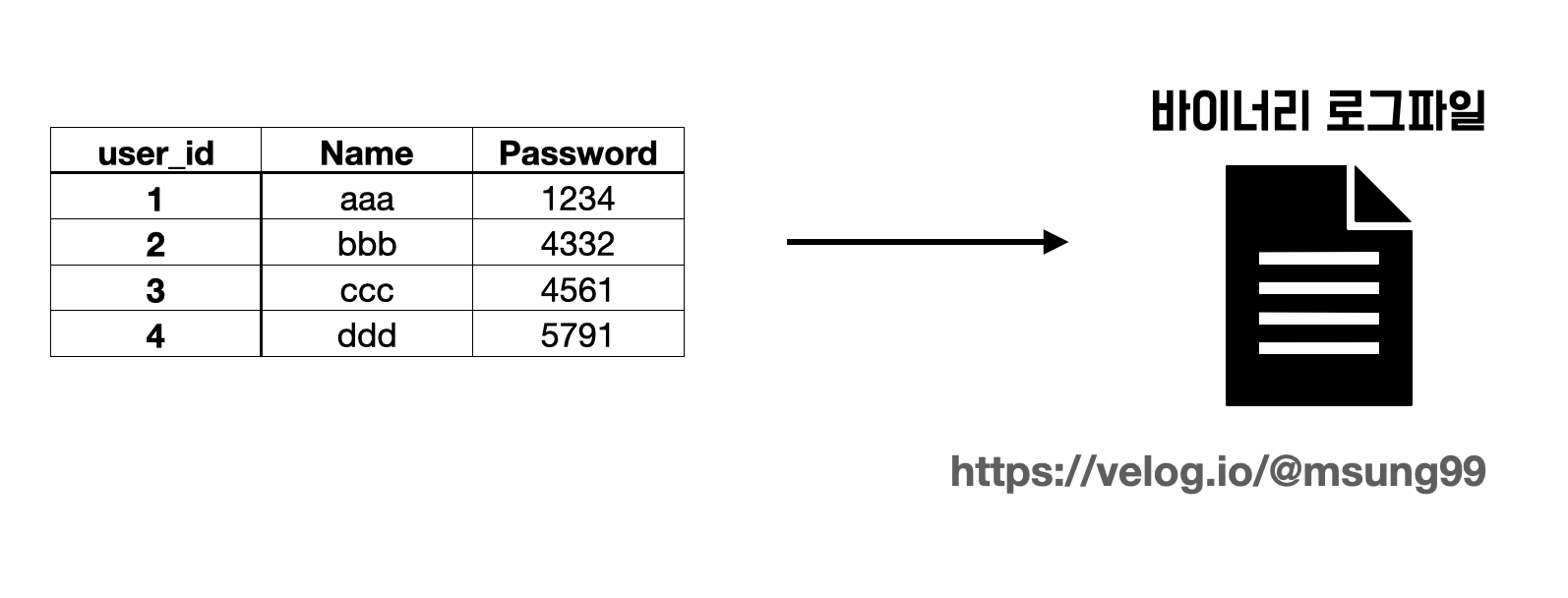
앞서 언급했듯이, WAS 서버에서 보낸 데이터는 트랜잭션 처리 쓰레드 에 의해 바이너리 로그에 이벤트(변경사항) 이 저장됩니다. 이때 어떤 타입으로, 즉 어떤 바이너리 로그 타입의 이벤트가 바이너리 로그 파일에 담기게될까요? MySQL 5.7.7 이전까지는 실행된 SQL 문을 그대로 저장했으나, 이후로는 row 기반 바이너리 로그 타입 을 기본적으로 저장하고 있습니다. 이 방식은 변경값 자체가 바이너리 로그에 그대로 저장되는 방식입니다.
복제 토폴로지 방식
그렇다면 소스 서버와 레플리카 서버를 어떻게 구성할 수 있을지에 대해서도 생각해봅시다.
Single Replica (싱글 레플리카)
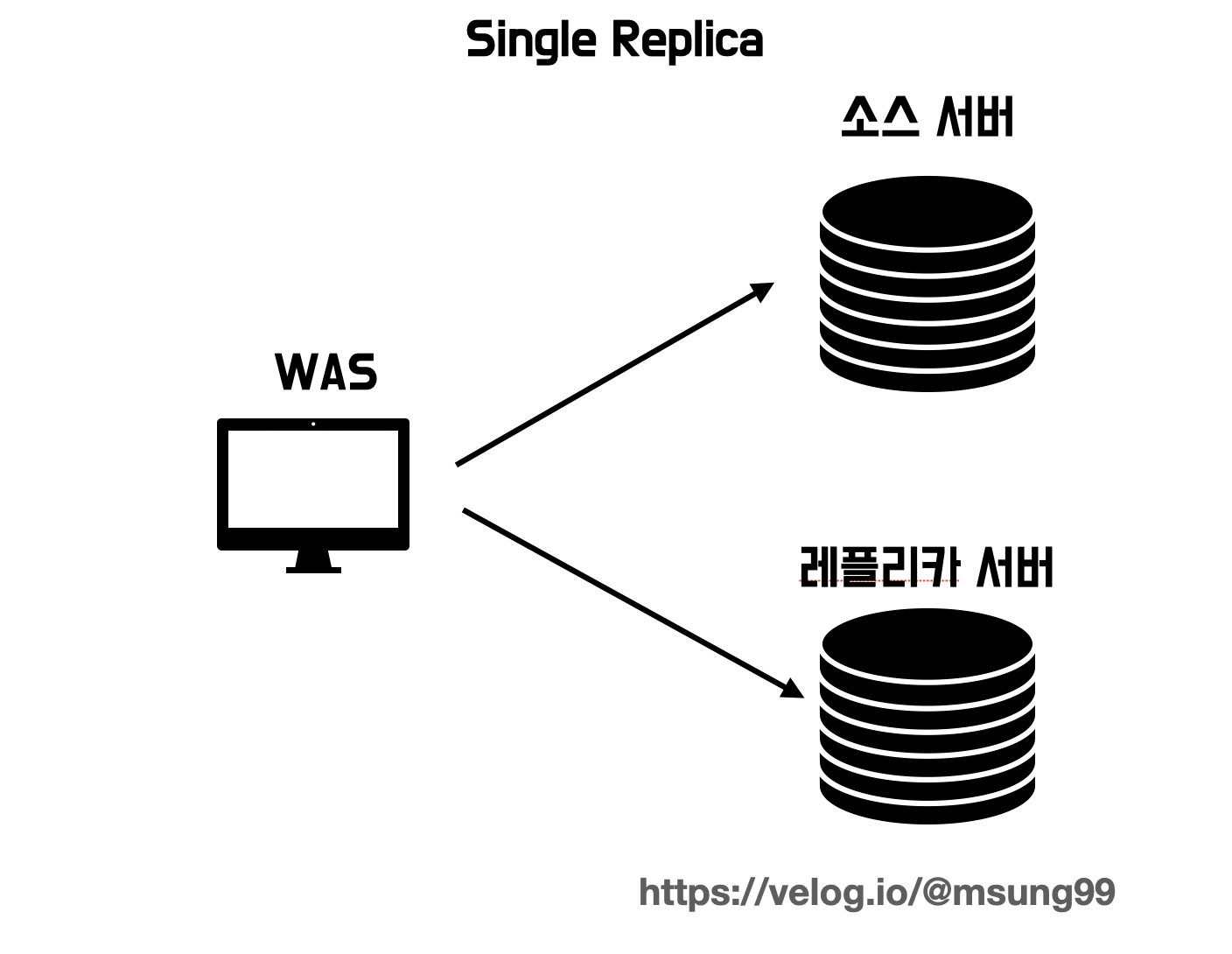
먼저 소스서버 1대와 레플리카 서버 1대를 두는 싱글 레플리카 방식이 있습니다. 레플리카 서버는 예비서버 및 데이터 백업용으로 활용됩니다.
Multi Replica (멀티 레플리카)
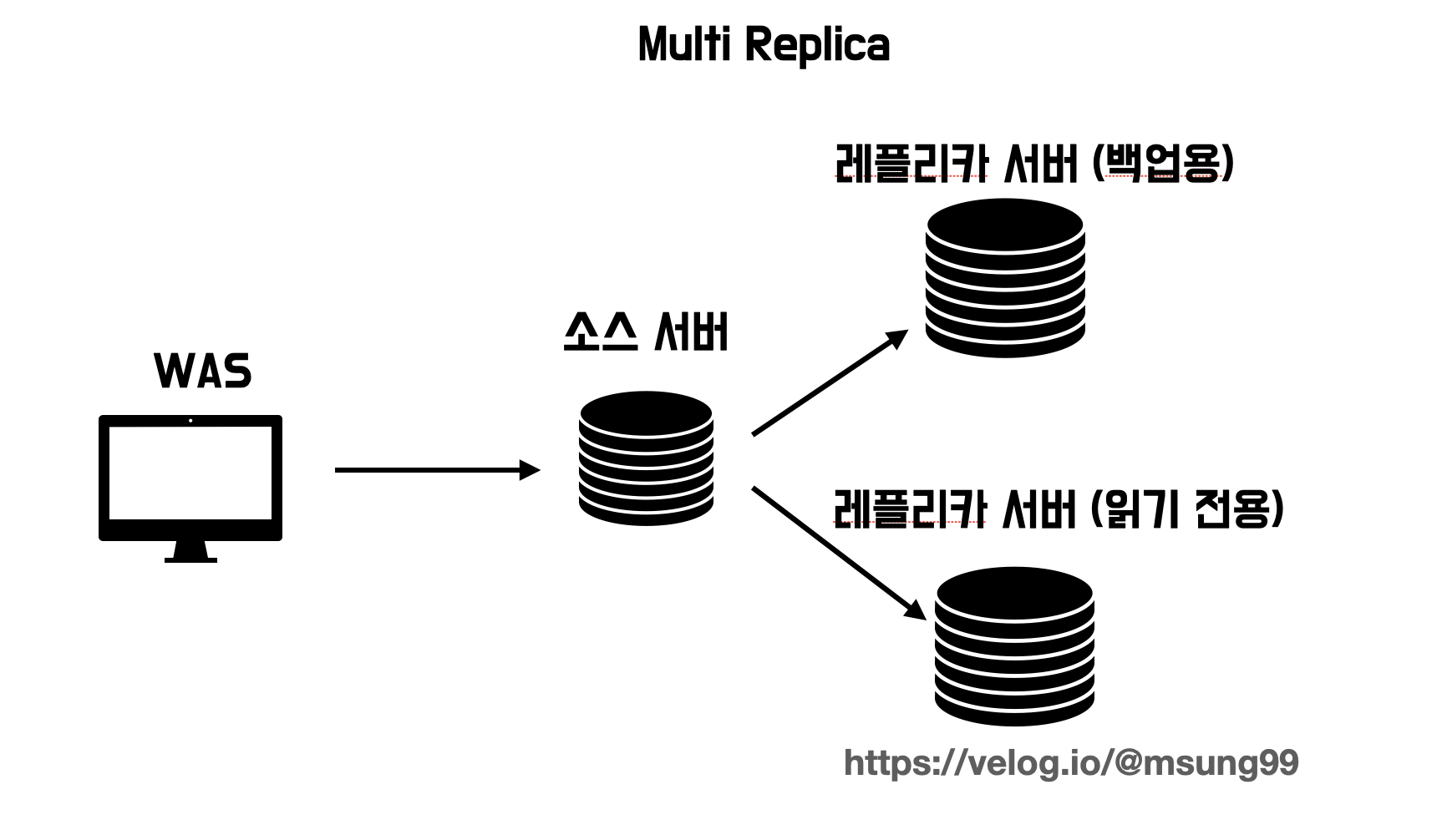
레플리카 서버를 여러대 배치한 방식인 멀티 레플리카 방식도 있습니다. 즉 소스서버 1대와 레플리카 여러대로 배치하는 방식이죠. 레플리카를 2대를 배치한다면, 한 서버는 부하 분산을 위한 용도로 사용하고, 다른 서버는 백업용을 위한 서버로 활용할 수 있습니다.
Chain Replication (체인 복제)
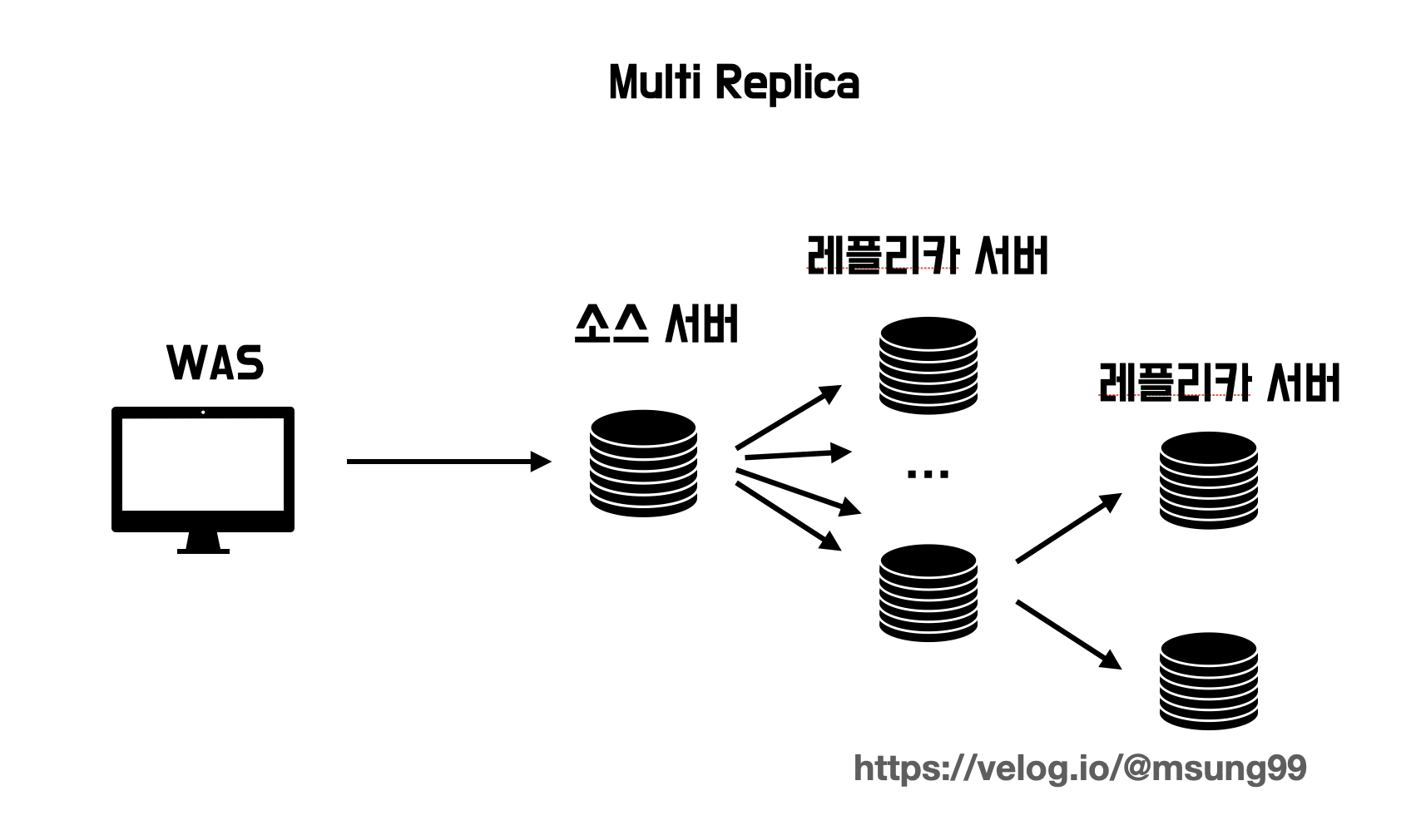
소스서버에 연결된 레플리카 서버가 많은 경우, 소스 서버에 복제로 인한 부하가 커지게 됩니다. 이런 경우 다른 레플리카 서버를 소스 서버로 활용해서 복제 부하를 분산시키는 사용할 수도 있습니다. 이 방식은 MySQL 서버를 업데이트하거나 장비 교채 하는 시기에도 이런 구성방식을 활용할 수 있을겁니다.
Dual Source Replication (듀얼 소스 복제)
또한 듀얼 소스 복제방식도 있는데, 두 서버가 모두 읽기와 쓰기가 모두 가능한 형태입니다. 두 서버 모두 서로 동일한 형태의 데이터를 가지고있고, 트랜잭션 충돌이 일어날 경우 롤백, 즉 복제 멈춤 현상이 일어나기 때문에 잘 사용되지 않는 토폴리지입니다.
Multi Source Replication (멀티 소스 복제)
마지막으로 멀티 소스 복제 방식이 있습니다. 레플리카 서버 한대에 소스 서버가 여러대 연결된 형태로, 소스서버에 흩어져 있는 데이터들은 한대 모아서 데이터를 분석할 때 사용할 수 있습니다.
참고
- Real MySQL 8.0 (백은빈, 이성욱 지음)
- https://www.youtube.com/watch?v=NPVJQz_YF2A