학습배경
MySQL 의 Master/Slave 레플리케이션(Replication) 아키텍처와 토폴로지 구성 방식 에서도 다루었듯이, 데이터베이스 레플리케이션(Replication) 에 대해 학습한 바가 있습니다. 레플리케이션과 함께 자주 언급되는 개념에는 클러스터링, 파티셔닝, 샤딩 등의 다양한 기법이 존재하는 것으로 보입니다. 이번에는 클러스터링과 샤딩에 대해 호기심이 생겨서 학습해보고자 합니다.
데이터베이스 클러스터링(Clustering)
데이터베이스 서버와 스토리지
사전에 알아야 할점이 있습니다. 바로 데이터베이스 저장소(스토리지) 와 데이터베이스 서버 는 다른 개념이라는 것입니다. 데이터베이스 서버는 SQL 을 실행하고, 스토리지는 실제로 데이터를 보존하는 저장소입니다. 가령 MySQL 을 서비스에서 사용하고 있다면, MySQL 이라는 것은 데이터베이스 서버이며, 실제로 데이터가 저장되는 곳은 따로 저장소가 존재합니다. 즉, MySQL 서버는 스토리지에 쿼리문을 날려서 저장소의 데이터에 대해 읽기-쓰기 작업을 수행하는 것입니다.
정합성 이슈 해결
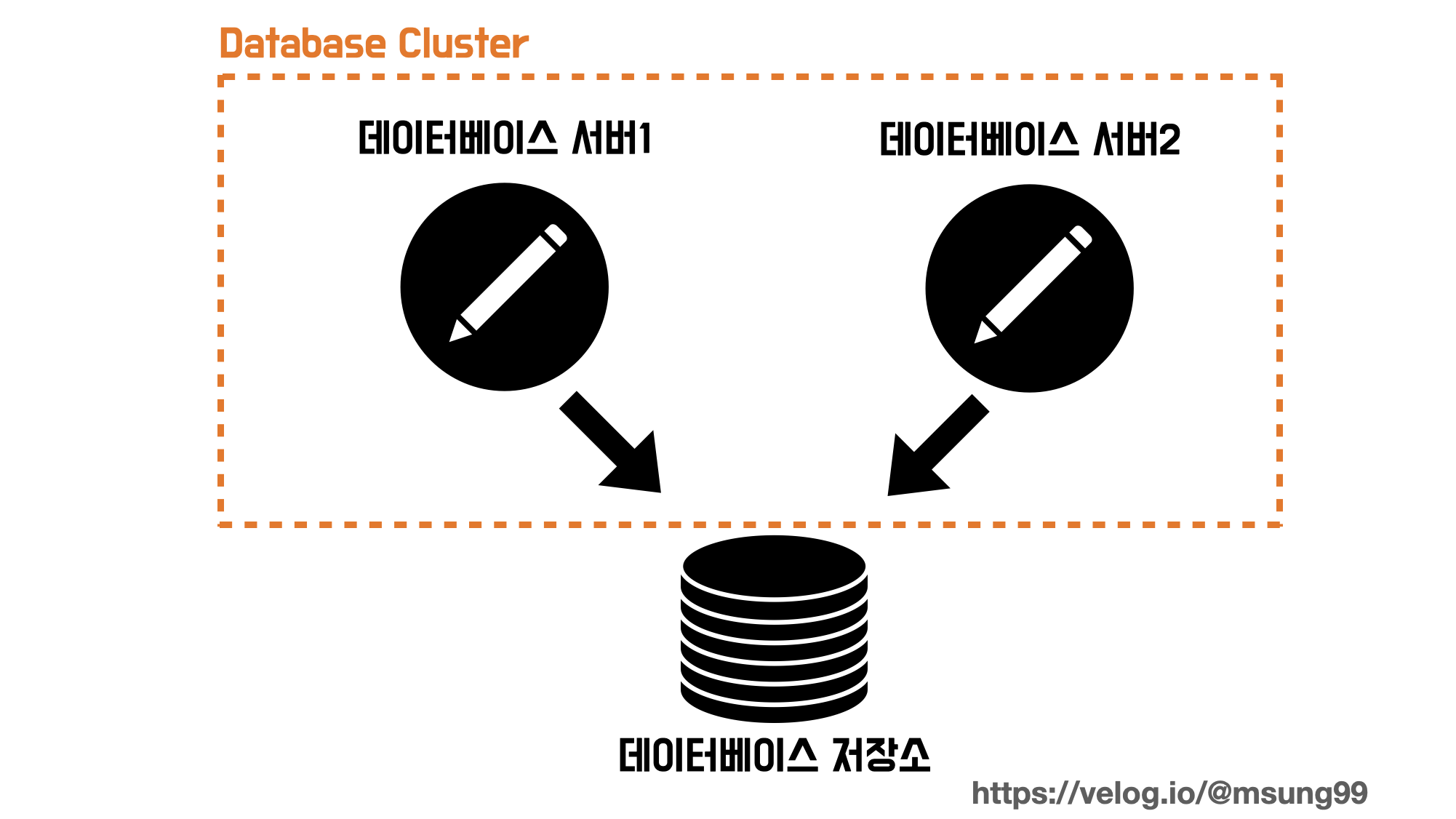
데이터베이스 스토리지를 다중화할 경우 정합성 문제는 절대 무시할 수 없을겁니다. 여러 저장소로 확장했을때 어떤 데이터가 어디에는 저장되고 어떤곳에는 저장이 안되는 현상이 발생한다면 서비스에 장애가 발생할 수 있기 때문에, 이를 사전에 방지하고 해결하는 것은 꽤나 번거롭습니다.
이 때문에 등장한것이 데이터베이스 클러스터링(Clustering) 입니다. 간단히 데이터베이스 스토리지는 한대만 두고, 여러 데이터베이스 서버가 공유하는 방식입니다. 모든 DB 서버가 하나의 저장소를 공유하기 때문에 정합성 문제를 걱정하지 않아도됩니다.
장점
특징을 정리해봅시다. 우선 장점으로는 DB 서버중 한대에 장애가 발생하더라도, 다른 서버가 역할을 대신할 수 있기 때문에 서비스가 중단되는 현상을 방지할 수 있습니다. 또한 스토리지 하나만 배치하고 서버 "여러대" 로 운영하기 때문에, 원활한 부하 분산 이 가능해집니다.
단점
하지만 단점은, 여러 DB 서버가 하나의 저장소를 공유하기 때문에 병목현상이 발생할 수 있습니다. 클러스터 서버를 여럿 늘리면 서버 개수에 정비례해서 처리 성능이 증가할 것 같지만, 막상 데이터베이스 저장소는 하나이기 때문에 저장소에서 병목이 발생할 수 있는것입니다. 이는 곧 성능저하의 원인이 될것입니다. 또한 여러 서버를 돌리다보면 비용 문제 도 무시못합니다.
클러스터링 종류
Active - Active
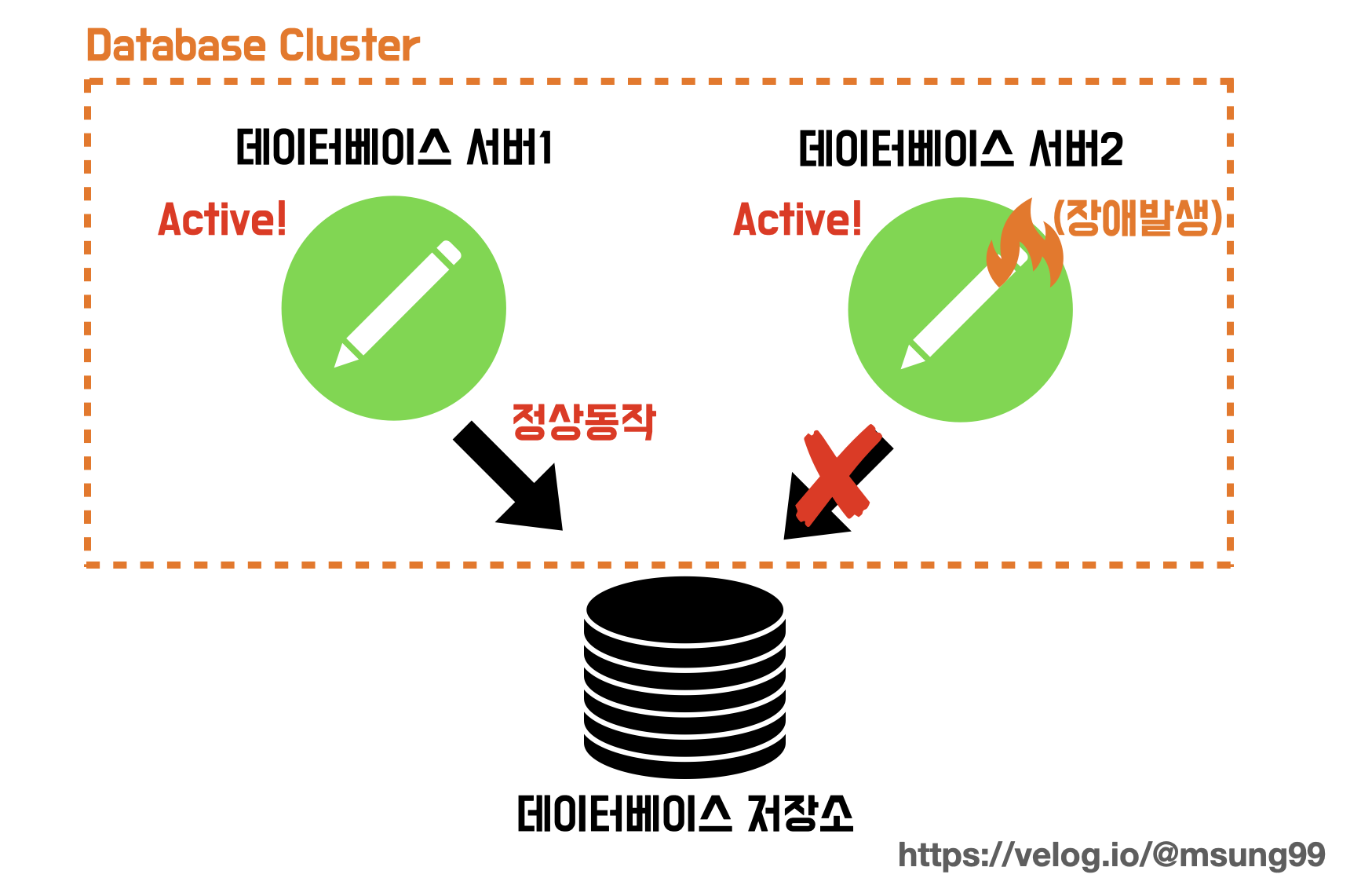
클러스터 내부의 모든 DB 서버를 Active(활성화) 상태로 만들어서, 모든 DB 서버가 실제로 동작하는 상태로 만드는 것 입니다. 이렇게 되면 한 서버에 장애가 발생해도 나머지 서버가 작업을 그대로 진행할 수 있게되서 다운타임 이 발생하지 않습니다. 또한 부하가 골구로 분산되므로 성능 측면에서도 기대해볼 수 있을겁니다.
하지만 여러 데이터베이스 서버가 하나의 스토리지를 공유하기 때문에, 저장소에서 병목 현상 이 발생하고 성능 저하의 원인이 될 수 있습니다.
Active - Standby
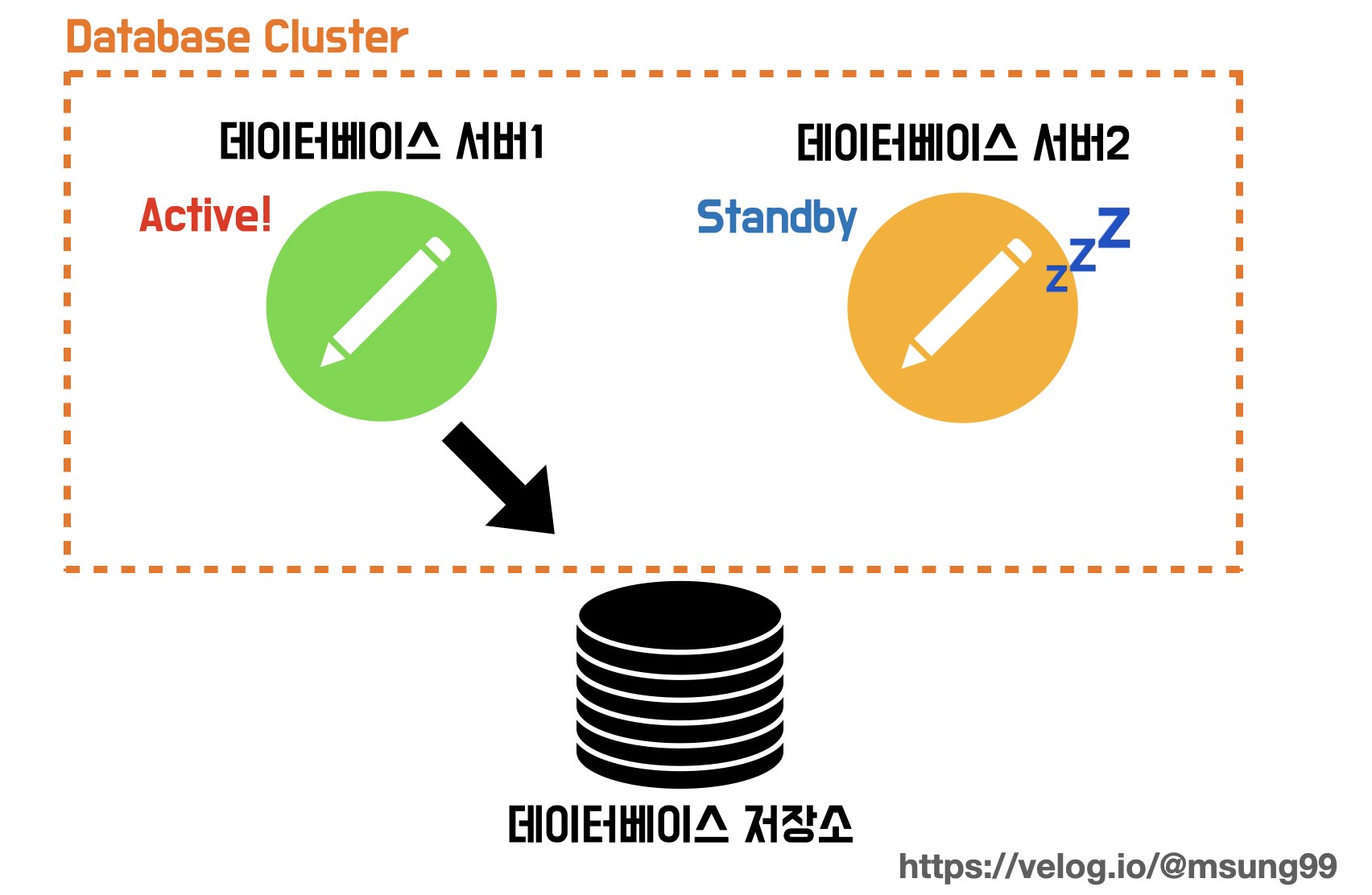
Active - Standby 방식은 일부 서버는 Active(활성화) 상태로 두고, 나머지 일부 서버들은 Standby(대기상태) 로 두는 방식입니다. Standby 서버는 평소에는 일을하지 않고, Active 서버에 장애가 발생했을때 본인이 Active 상태로 전환되어서 일을 대신하도록 주기적으로 기존 Active 서버를 모니터링 하는 방식으로 동작합니다.
장점은, Active-Active 구성 방식보다는 비용 절감이 될것입니다. 하지만 Standby 서버가 Active 서버로 전환되아야 할때 시간이 좀 오래걸려서다운타임이 발생 하게 되고, 결국 가용성이 떨어진다는 단점이 있습니다.
데이터베이스 샤딩(Sharding)
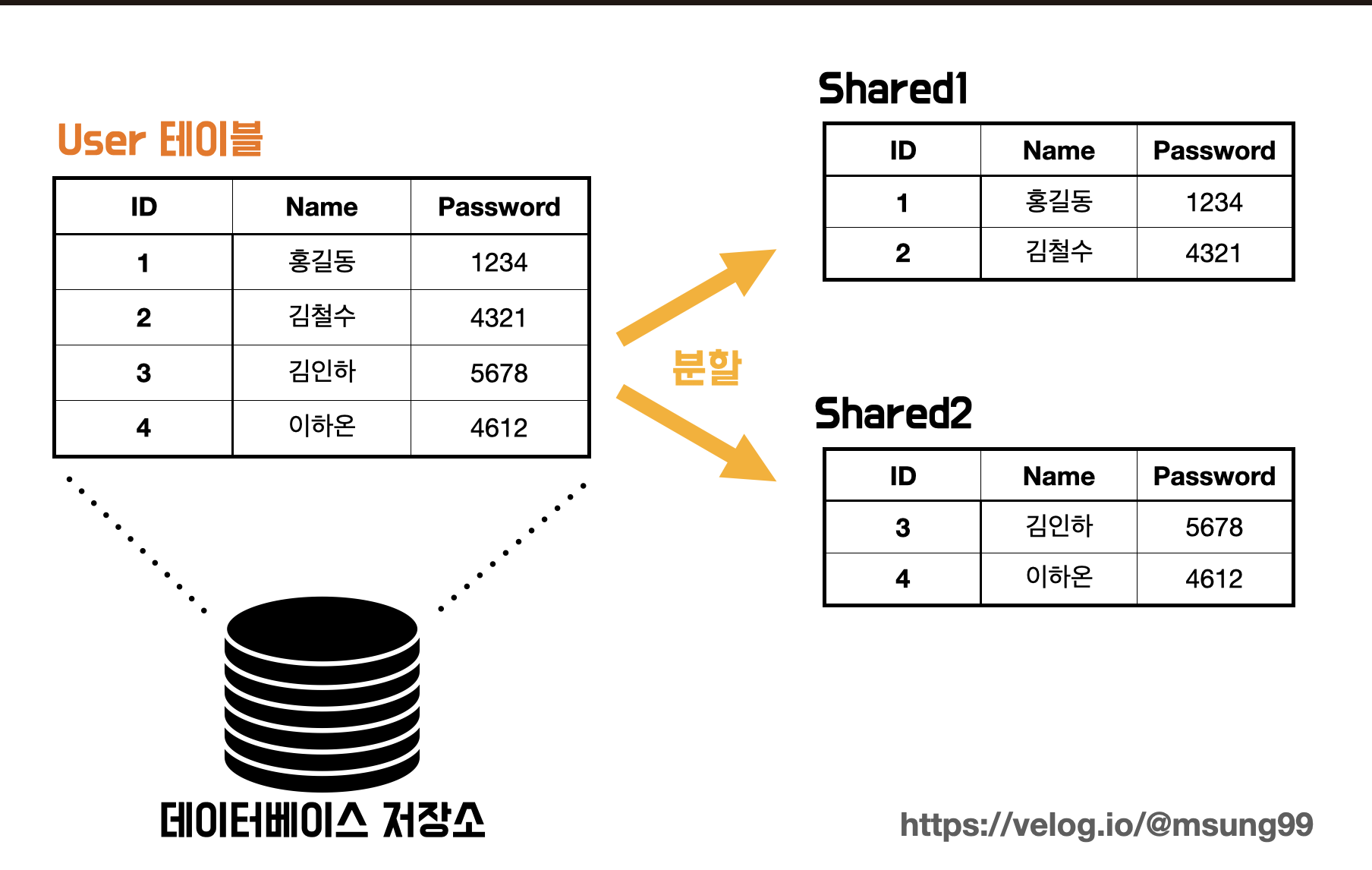
데이터가 쌓이고 개수가 많아지면 연산이 느려질겁니다. 어떻게 더 빠른 연산을 제공할지에 대한 고민에서 탄생한 방식이 샤딩(Sharding) 으로, "테이블을 나눠서 빠르게 연산을 진행하는 방식" 입니다. 정리하면, 샤딩은 동일한 스키마(테이블) 을 가지고 있는 데이터들에 대해 여러대의 데이터베이스 서버에 여러 작은 단위로 끊어서 분산 저장하는 기법입니다. 이때 작은 단위를 샤드(Shared) 라고 합니다.
샤드 키(Shared Key)
샤드 키(Shared Key) 란 분할된 여러 샤드중 어떤 샤드를 선택할지 결정할때 사용되는 Key 값입니다. 또한 이 샤드키를 어떤 방식으로 생성할지에 따라서 샤딩의 방법이 나뉩니다. 샤딩의 방법으론 해시 샤딩(Hash Sharding) , 동적 샤딩(Dynamic Sharding), 엔티티 그룹(Entity Group) 이 있습니다.
Hash Sharding
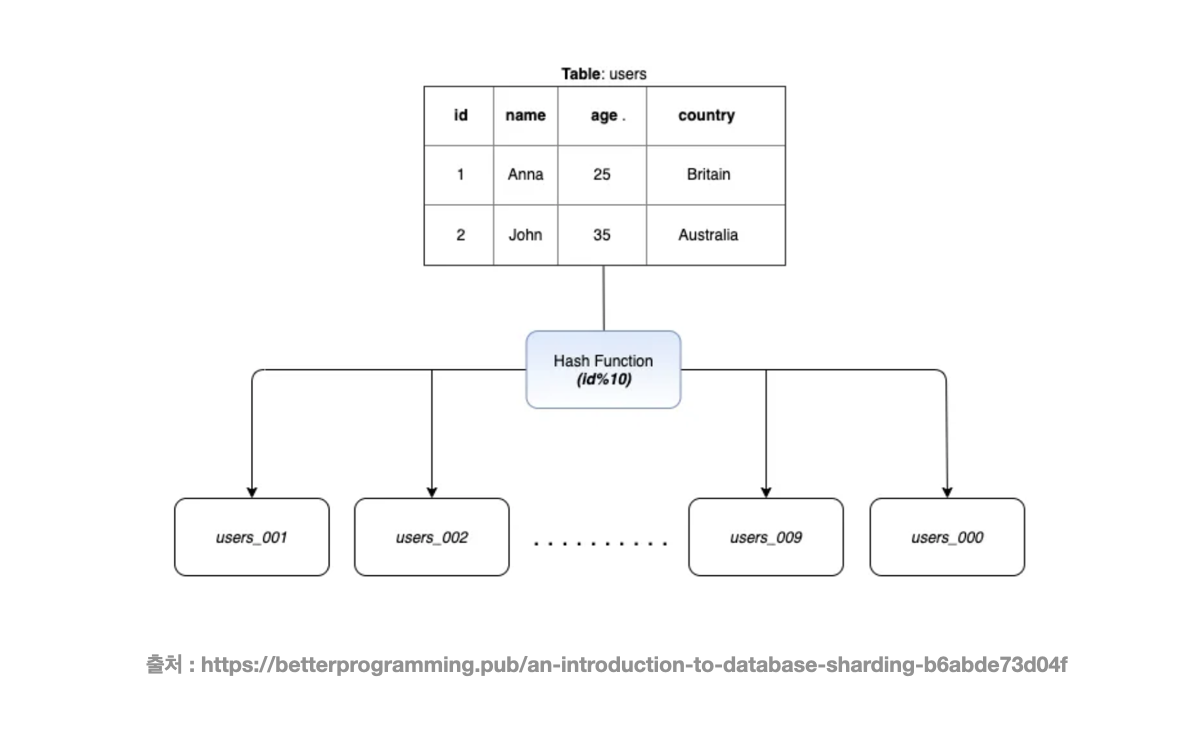
해시 샤딩은 해시함수 를 활용한 방식으로, PK 값을 나머지 연산 을 진행한 결과값으로 어떤 샤드에 들어갈지 결정하는 방식입니다. 이 방식은 구현자체가 샤드의 수만큼 해싱을 하면 되기 때문에 간단합니다.
대신에 샤드가 늘어나면 해시함수 자체가 달라져야 하기 때문에, 기존에 저장되면 데이터들에 대한 정합성이 깨지게됩니다. 따라서 확장성이 안좋다는 단점이 있습니다. 또한 단순히 key 값을 기준으로해서 해시 데이터를 나누기 때문에, **공간에 대한 효율성은 고려하지않고 단순 해시로만 처리한다는 단점이 있습니다. **
Range Sharding (Dynamic Sharding)
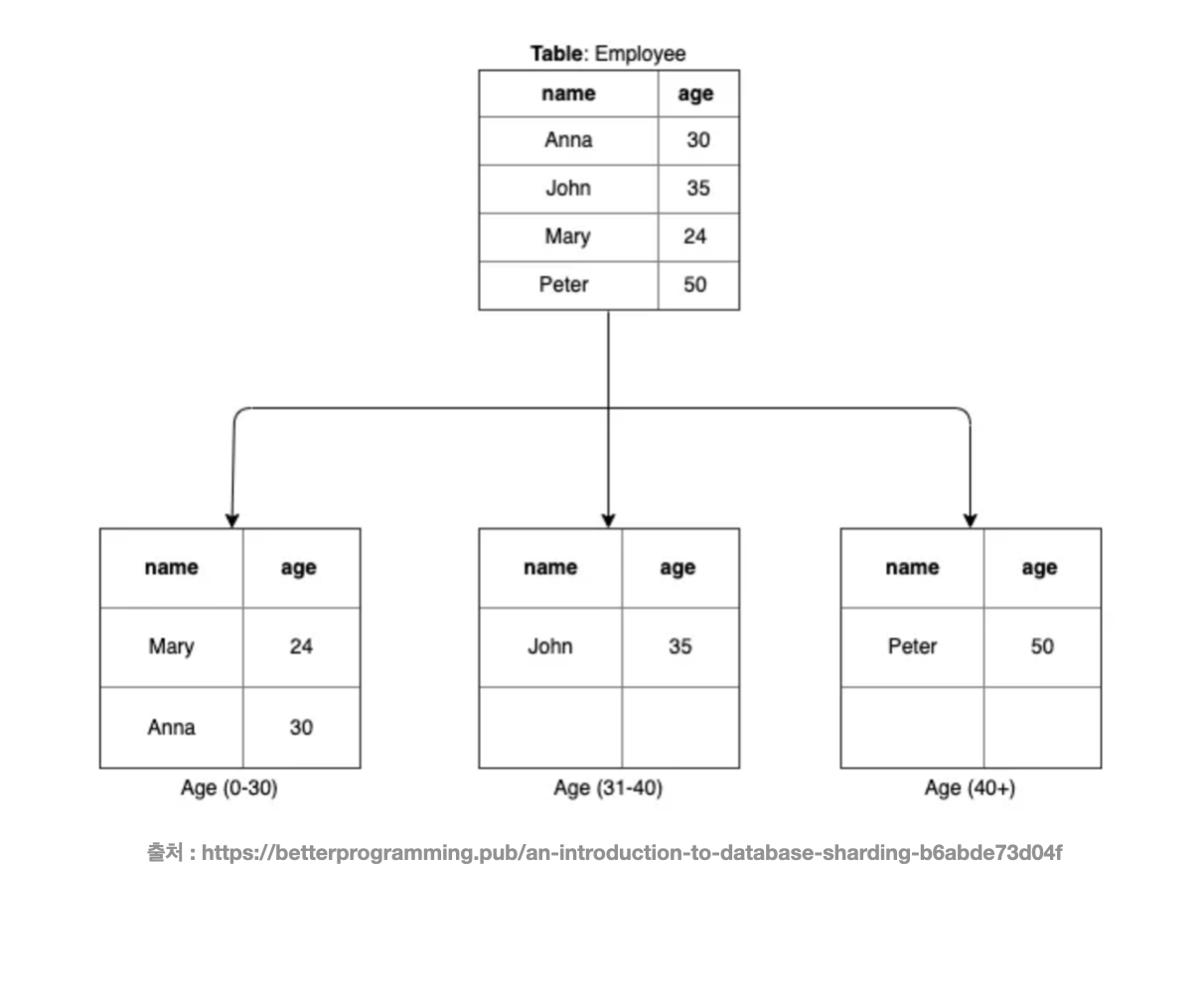
다이나믹 샤딩(Dynamic Sharding) 이라고도 불리는 레인지 샤딩(Range Sharding) 은 확장성을 해결한 방식입니다. PK 값을 범위로 지정하여 샤드를 결정하는 방식이죠. 예를들어 PK 가 1100번인 데이터에 대해서는 1번 샤드에, 101200번 데이터에 대해서는 2번 샤드에 저장하는 방식입니다.
대신 단점은, 특정 샤드에만 트래픽이 몰려서 부하 문제 가 충분히 발생할 수 있습니다. 예를들어 "최근 게시물" 조회 API 가 있고, 이 API 를 메인으로 사용하는 서비스가 있다고 해봅시다. 최근에 작성된 게시물은 마지막 샤딩에만 위치하게 될텐데, 최근 게시물들을 조회하기 위해 여러 트래픽에 마지막 샤딩에만 몰리게 될 것입니다. 결국 특정 샤딩에만 트래픽이 몰릴 가능성이 높고, 다른 샤딩에는 비교적 유입될 트래픽이 적게되는 현상이 발생합니다.
따라서 특정 상황에서는 레인지 샤딩보다 해시 샤딩이 더 좋을수도 있습니다.
Entity Group
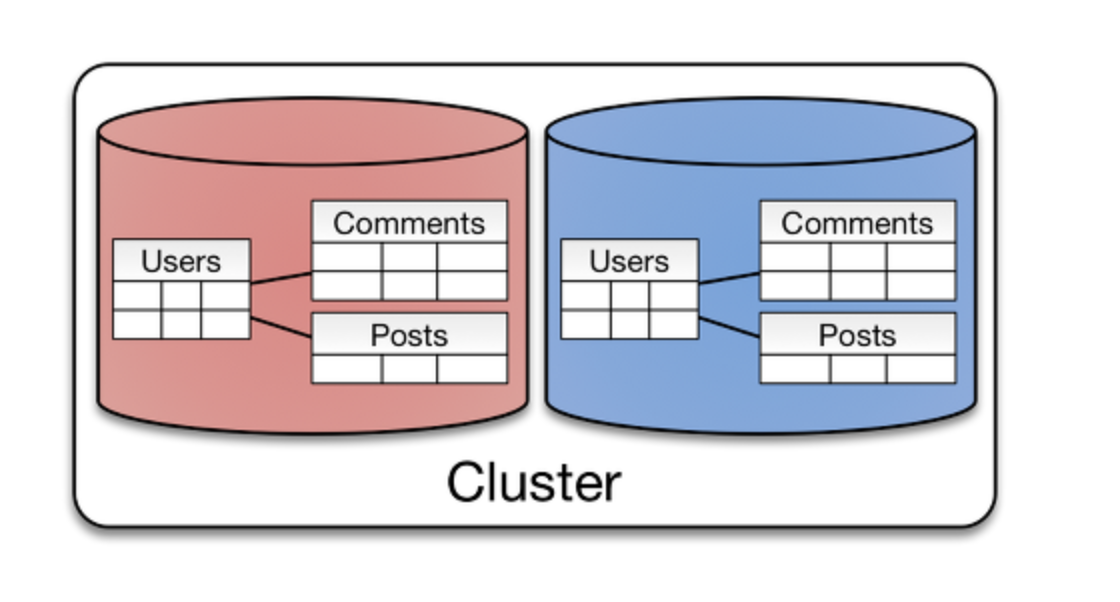
앞선 방식들이 key-value 형식의 NoSQL 에 더 작합한 샤딩 방식이라면, 이 방식은 RDBMS 에서 더 유리한 방식입니다. 관계가 매핑되어 있는 엔티티끼리를 같은 샤드내에 위치하도록 만든 방식입니다. 그래서 유저가 작성한 게시글이나 댓글등을 같은 샤드 내에서 가지고 있도록 작성한 방식입니다.
즉, 이 방식은 단일 샤드 내에서 강한 응집도를 가지고, 동일한 그룹에 대한 SQL 문에 대해선 매우 빠른 응답속도를 받을 수 있을겁니다. 하지만 다른 그룹에 대한 SQL 문에 대해선 매우 비효율적인 방식이 되겠죠.
더 학습해볼 키워드
- 데이터베이스 파티셔닝
- 스프링부트에서 레플리케이션 구현방법