MySQL 레플리케이션과 스프링부트 DataSource 라우팅을 통한 쿼리 성능개선
데이터베이스 레플리케이션 관련 이론적인 내용은 MySQL 의 Master/Slave 레플리케이션(Replication) 아키텍처와 토폴로지 구성 방식 을 참고하자.
레플리케이션 구성
지난 [MySQL 8.0] Master/Slave 레플리케이션 구조로 데이터베이스 분산 환경을 구축해보자! 에서는 MySQL 서버 2대를 띄워놓고, 각 서버의 데이터베이스 2대를 Master-Slave 구조로 구축해서 실시간으로 동기화가 이루어지도록 환경 구축을 마쳤습니다. 이번에는 스프링부트에서도 이 환경에 알맞게 DataSource 를 분기할 수 있도록 개발을 진행했는데, 이를 다루어보고자 합니다.
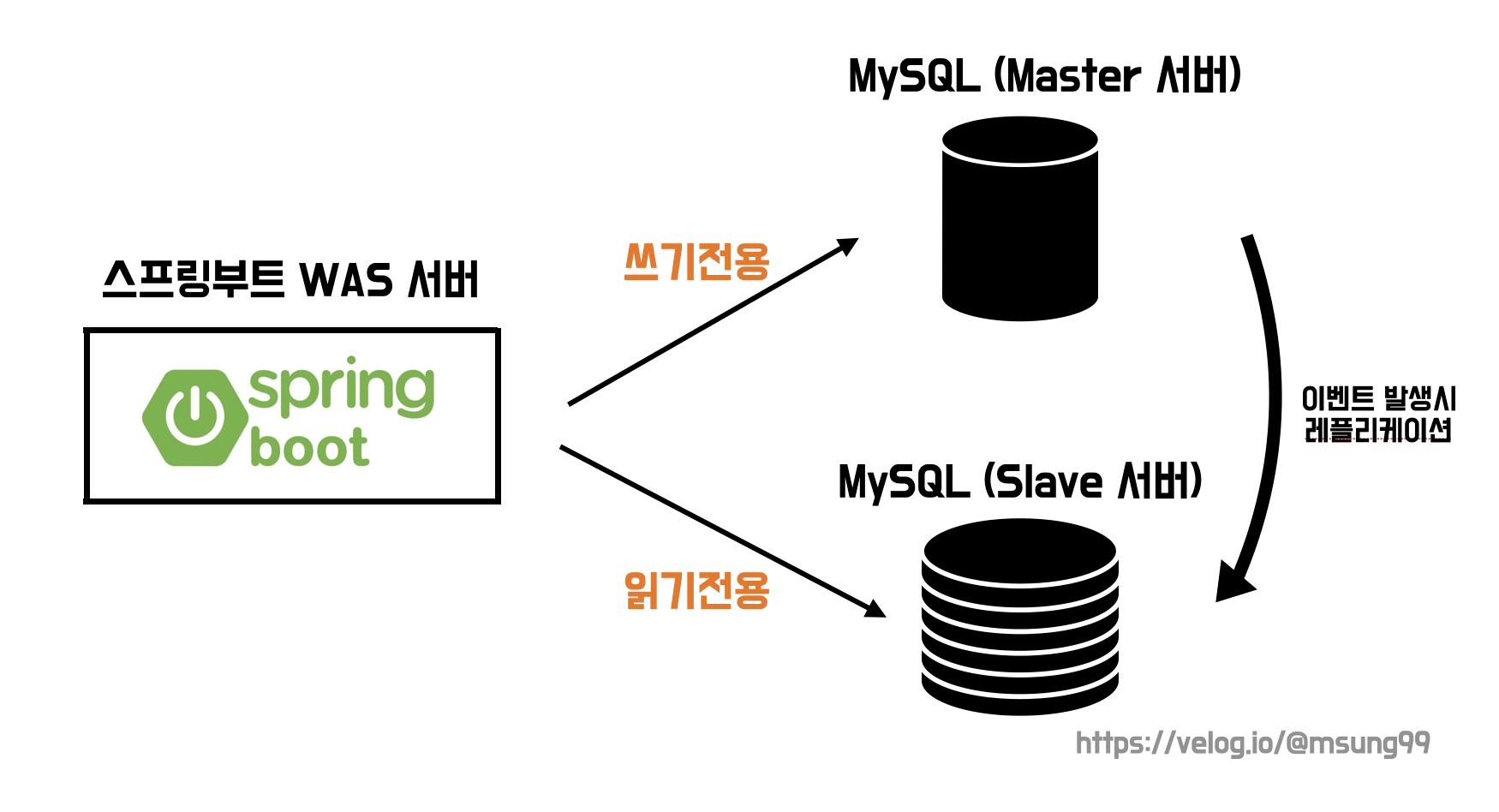
레플리케이션 환경에 대한 구성은 위와 같습니다. MySQL 서버를 2대 띄운것은 지난번과 동일하며, 트랜잭션의 readOnly 설정값에 따라서 Master/Slave 중에 요청이 분산됩니다. Master 서버는 쓰기전용 서버로 배치했기 떄문에 쓰기 요청은 모두 마스터 서버로 분기되며, Slave 서버는 읽기전용 서버로 배치했기 때문에 읽기 연산은 슬레이브 서버로 분기됩니다.
데이터베이스에 요청되는 대부분의 요청은 조회 쿼리문(Select) 이므로, 이렇게 조회 전용 데이터베이스 서버를 따로 배치해둔다면 조회 쿼리 성능이 꽤나 향상될것을 기대해볼 수 있습니다.
application.yml
이번에 구축할 환경이 Multi DataSource 임을 감안하여, 스프링부트 application.yml 에 DataSource 에 대한 설정을 여러개로 구분하여 구성해줬습니다. spring.datasource.master 와 spring.datasource.slave 로 이중 구성을 진행해줬으며, 추후 아래에서 살펴볼 Config 파일들에서 readOnly 옵션값에 따라서 각 DataSource 에 대한 분기 요청을 설정해 줄 것입니다.
spring:
datasource:
master:
username: haon
password: password
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://111.111.111:.11:3306/replication
slave:
username: haon
password: password
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://222.222.222.22:3306/replication
mvc:
pathmatch:
matching-strategy: ant_path_matcher
jpa:
database-platform: org.hibernate.dialect.MySQLDialect
open:
open-in-view: false
show-sql: true
sql:
init:
platform: mysqlDataSourceConfig
가장 먼저 DataSource 에 대한 Config 파일인데, 설정정보 구성 전체 코드는 아래와 같습니다. 한 단위씩 끊어서 자세히 설명해보겠습니다.
@Configuration
public class DataSourceConfig {
private static final String master = "master";
private static final String slave = "slave";
@Bean @Qualifier(master)
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource masterDataSource(){
return DataSourceBuilder.create().build();
}
@Bean @Qualifier(slave)
@ConfigurationProperties(prefix = "spring.datasource.slave")
public DataSource slaveDataSource(){
return DataSourceBuilder.create().build();
}
@Bean
public DataSource routingDataSource(
@Qualifier(master) DataSource masterDataSource,
@Qualifier(slave) DataSource slaveDataSource){
RoutingDataSource routingDataSource = new RoutingDataSource(); // 쿼리 요청을 적절한 서버로 분기할 때 활용됨
HashMap<Object, Object> targetDataSourceMap = new HashMap<>();
// targetDataSourceMap 객체에 분기할 서버들의 DataSource 빈을 저장
targetDataSourceMap.put("master", masterDataSource);
targetDataSourceMap.put("slave", slaveDataSource);
routingDataSource.setTargetDataSources(targetDataSourceMap); // DataSource 타깃을 설정한다.
routingDataSource.setDefaultTargetDataSource(masterDataSource);
return routingDataSource;
}
@Bean
@Primary
public DataSource dataSource(){
DataSource determinedDataSource = routingDataSource(masterDataSource(), slaveDataSource());
return new LazyConnectionDataSourceProxy(determinedDataSource);
}
}masterSource, slaveDataSource 빈 등록
우선 DataSourceConfig 에 새롭게 추가한 MySQL 서버에 대한 DataSource 빈 을 등록해야합니다. 이를위해 아래와 같이 Master 와 Slave 에 대한 두개의 DataSource 타입 빈을 등록해줬습니다.
이때 @ConfigurationProperties 을 사용하면 application.yml 에서 특정 prefix 에 해당하는 설정 값만을 자바 Bean 에다 매핑할 수 있습니다. 즉 2개의 DataSource 타입의 빈에 대해 서로 다른 prefix 설정정보 값을 기반으로 빈이 구성되도록 해줬습니다.
또한 @Quaifier 를 사용한 것을 볼 수 있습니다. [ loc/DI ] 컴포넌트 스캔의 다양한 대상들과 DI 에 대한 해결방법 에서도 다루었듯이, 기본적으로 의존관계 주입은 타입 을 기준으로 빈을 등록하고 매핑되기 떄문에 동일한 타입이 있을때 별도의 처리가 없다면 NoUniqueBeanDefinitionException 이 발생한다고 했었습니다. 이를 해결하도록 동일한 DataSource 타입을 가지는 2개의 빈에 대해 @Quaifier 로 추가 구분자명을 부여해서 2개의 빈이 구분되어 등록되도록 해줬습니다.
private static final String master = "master";
private static final String slave = "slave";
@Bean @Qualifier(master)
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource masterDataSource(){
return DataSourceBuilder.create().build();
}
@Bean @Qualifier(slave)
@ConfigurationProperties(prefix = "spring.datasource.slave")
public DataSource slaveDataSource(){
return DataSourceBuilder.create().build();
}AbstractRoutingDataSource 상속
DataSourceConfig 의 나머지 메소드들은 잠깐 제치고, RoutingDataSource() 클래스를 봅시다. 스프링에서는 여러개의 DataSource 를 하나로 묶고 자동으로 분기해주는 AbstractRoutingDataSource 클래스를 제공합니다.
determineCurrentLookupKey() 를 오버라이드 했는데, 여러개의 DataSource 중에서 실제로 사용될 DataSource 를 결정하는 역할을 합니다. 즉, Master 와 Slave 서버중에서 어떤것을 사용할지를 결정하는데, TransactionSynchronizationManager 로 현재 요청에 대한 트랜잭션 속성이 읽기전용 인지, 아니면 쓰기전용 인지에 따라서 마스터 또는 슬레이브 서버중에 어떤것을 사용할지를 결정하는 것입니다.
// AbstractRoutingDataSource : Multi DataSource 환경에서 여러 DataSource 를 묶고 분기해줄 때 사용한다.
public class RoutingDataSource extends AbstractRoutingDataSource {
// determineCurrentLookupKey 메소드 : 여러 datasource 중에서 실제로 사용될 DataSource 를 결정하는 역할
// 현재 트랜잭션의 속성에 따라 targetDataSourceMap 의 조회 Key 를 결정하기위해 AbstractRoutingDataSource 를 상속받아서 determineCurrentLookupKey 를 구현했다.
@Override
protected Object determineCurrentLookupKey() {
boolean isReadOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
logger.info("현재 트랜잭션 속성이 ReadOnly인가?:" + isReadOnly);
return isReadOnly ? "slave" : "master";
}
}routingDataSource
다시 DataSourceConfig 로 돌아와서, routingDataSource() 에 대해 봅시다. 앞서 정의한 RoutingDataSource 객체를 사용해서, 트랜잭션 요청을 적절한 DataSource 서버로 분기하기 위해 선언해줬습니다.
또한 HashMap 을 생성하고, 앞서 정의한 masterDataSource 와 sourceDataSource 에 대한 스프링 빈을 각각 "master" 와 "slave" 로라는 Key 값과 매핑시켰습니다.
HashMap 에 저장된 이 2개의 DataSource 를 RoutingDataSource (정확히는 AbstractRoutingDataSource) 의 setTargetDataSources() 로 현 스프링부트 서버의 DataSource 타깃을 설정해줬으며, setDefaultTargetDataSource() 로 기본 데이터 소스를 마스터 서버로 지정해줬습니다.
@Bean
public DataSource routingDataSource(
@Qualifier(master) DataSource masterDataSource,
@Qualifier(slave) DataSource slaveDataSource) {
RoutingDataSource routingDataSource = new RoutingDataSource(); // 쿼리 요청을 적절한 서버로 분기할 때 활용됨
HashMap<Object, Object> targetDataSourceMap = new HashMap<>();
// targetDataSourceMap 객체에 분기할 서버들의 DataSource 빈을 저장
targetDataSourceMap.put("master", masterDataSource);
targetDataSourceMap.put("slave", slaveDataSource);
routingDataSource.setTargetDataSources(targetDataSourceMap); // DataSource 타깃을 설정한다.
routingDataSource.setDefaultTargetDataSource(masterDataSource);
return routingDataSource;
}dataSource( )
마지막으로 DataSourceConfig 에 대한 마지막 스프링 빈입니다. 현 스프링부트 전반에서 사용될 최종적인 DataSource 빈을 등록해주는 것입니다.
이때 LazyConnectionDataSourceProxy 를 사용하는 모습을 볼 수 있습니다. 스프링부트는 트랜잭션에 진입하는 순간부터 설정된 DataSource 의 커넥션을 가져옵니다. 이것이 Multi Source 환경에서 문제가 될 수 있습니다. 트랜잭션에 진입한 이후에 DataSource 를 결정해야하는데, 예전에 이미 트랜잭션 진입시점에 DataSource 를 결정하고 커넥션을 획득했기 때문에 분기가 불가능합니다. 이를 해결가능하게 하는 것이 바로 LazyConnectionDataSourceProxy 입니다.
LazyConnectionDataSourceProxy 를 사용하면 실제로 커넥션이 필요한 경우가 아니라면, 데이터베이스 풀에서 커넥션을 점유하지 않고 필요한 시점에만 커넥션을 점유할 수 있게 됩니다. 즉, 실제로 쿼리가 시작되고 Repository 계층을 활용하게 될때 DataSource 가 결정되고 커넥션을 맺는 방식으로 동작합니다. 요약하자면, Datasource 를 결정하고 커넥션을 획득하는 시점을 지연(Lazy) 시켜서 정상적으로 DataSource 를 결정하도록 하는 것입니다.
@Bean
@Primary
public DataSource dataSource(){
DataSource determinedDataSource = routingDataSource(masterDataSource(), slaveDataSource());
return new LazyConnectionDataSourceProxy(determinedDataSource);
}LazyConnectionDataSourceProxy 와 관련된 더욱이 깊은 내용은 추후 별도의 포스팅으로 자세히 다루도록 하겠습니다. 이와 관련해 더 깊은 학습해봐야겠다고 느껴지네요!
OSIV 이슈 🔥 (아직 완전히 해결된게 아니라고?)
사실 이렇게만 진행했다면 OSIV 문제 가 발생합니다. 실제로 제가 이렇게 까지만 DataSource 환경을 구축했을떄, DataSource 분기가 이루어지지 않는 문제가 발생했었습니다. 이와 관련해서는 조만간 매우 깊은 내용과 함께 새로운 포스팅에서 다루어보고자 합니다.
따라서 지금으로써는, OSIV 이슈를 해결했음을 가정하고 쿼리 성능 측정을 진행했다고 보시면 될 것 같습니다.
실제 쿼리성능 측정
실제로 분기가 잘 되는지를 직접 확인해보기 위해, 간단히 스키마를 하나 정의하고 API 를 정의했습니다.
성능 측정환경
(몰론 제가 현재 운영하는 실제 프로젝트와는 환경이 많이 다릅니다. 레플리케이션 학습 차원에서 확인하도록 이렇게 구축한 것입니다 🙂)
- MySQL 데이터베이스를 2대 띄웠다. (지난번과 동일)
- 데이터베이스에
약 16300개의 더미데이터를 삽입했다. - 스프링부트 API 서버를 한대 띄웠다.
- API 를 간단히 정의하고, Jmeter 를 활용하여 200개의 쓰레드를 생성하고 읽기/쓰기 동시 요청을 보낸다.
- 레플리케이션을 미적용했을때의 API 서버로 따로 성능 측정을 진행했다. 적용과 미적용했을때의 성능을 비교해볼 것이다.
User
엔티티에 대한 간단히 클래스를 정의해줍시다.
@Entity
@AllArgsConstructor @NoArgsConstructor
@Getter @Setter
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private Long age;
public User(String name, Long age){
this.name = name;
this.age = age;
}
}UserController
API 2개를 정의했습니다. GET 요청의 경우는, 특정 나이에 해당하는 모든 유저를 데이터베이스에서 조회하는 로직입니다. POST 요청의 경우는, 간단히 유저를 생성하는 로직입니다.
@RestController
public class UserController {
private final UserService userService;
@Autowired
public UserController(UserService userService){
this.userService = userService;
}
@GetMapping("/user/{age}")
public ResponseEntity<List<User>> getUserInfo(@PathVariable("age") Long age){
return ResponseEntity.ok(userService.getUserInfo(age));
}
@PostMapping("/user")
public ResponseEntity<String> createUser() {
userService.createUser();
return ResponseEntity.ok("회원가입에 성공했습니다.");
}
}UserService
getUserInfo 와 createUser 메소드를 간단히 정의했습니다. 이때 createUser 의 경우는 유의미한 더미데이터 값을 삽입하기위해 UUID 와 random 값을 기반으로 컬럼값을 삽입하도록 구현했습니다. 이때 age 값의 경우 1~99 사이의 값이 되도록 해줬습니다.
@Service
public class UserService {
private final UserRepository userRepository;
@Autowired
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
@Transactional(readOnly = true)
List<User> getUserInfo(Long age){
List<User> user_list = userRepository.findAllByAge(age);
return user_list;
}
@Transactional
public void createUser(){
String random_name = UUID.randomUUID().toString();
Random random = new Random();
Long random_age = Math.abs(random.nextLong()) % 99 + 1;
User user = new User(random_name, random_age);
userRepository.save(user);
}
}UserRepository
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
List<User> findAllByAge(Long age);
}Response 성능 측정
이렇게 모든 작업이 끝난후, 실제로 성능 테스트를 진행했습니다. 앞서 말했듯이 약 16300 개 의 더미데이터를 삽입해줬습니다. 또한 Master/Slave 미적용 환경에서 동일한 API 를 개발했을때와 비교를 진행하고, 레플리케이션을 적용했을때 실제로 얼마나 쿼리 성능이 개선되었는지를 확인했습니다.
쿼리 성능 개선결과
Jmeter 를 활용하여 200개의 쓰레드를 POST 요청으로 보내고, 나머지 소수의 GET 요청들로 조회 쿼리를 실행하도록 진행했습니다.
레플리케이션을 미적용했을때는, 약 1400~1700ms 가량의 조회 응답시간을 확인할 수 있었으며, 반대로 레플리케이션 적용시에는 약 500~900ms 가량의 조회 응답시간이라는 결과를 얻어낼 수 있었습니다. 이렇듯 조회 쿼리의 경우 대략 2배 가량의 성능이 향상된 결과를 도출할 수 있게 되었습니다 🙂
쿼리 성능 향상원인
이미 이에 대한 정답은 알고있지만, 마무리하면서 다시 확실히 정리도 해볼겸 쿼리가 어떤 이유로 향상되었는지를 요약해보고자 합니다.
우선 레플리케이션의 주 목적은 부하 분산 과 고가용성 을 위해서라고 계속 얘기했었습니다. Master 데이터베이스의 읽기작업을 Slave 로 분산시킴으로써 당연히 읽기 부하가 분산되고 부하가 감소해서 응답속도가 향상될것입니다. 또한 이렇게 분산 환경을 구축함으로써 병렬 처리 가 가능해지는 것이므로 많은 트래픽이 유입되었을때 당연히 작업 속도가 전반적으로 향상될것입니다.
읽기(조회) 쿼리 성능만 향상되는 것처럼 언급했는데, 쓰기 쿼리 성능도 당연히 향상될것입니다. 몰론 읽기 요청만큼 가벼운 요청은 아니라서 엄청난 성능 향상의 기대는 힘들겠지만, 슬레이브 서버에게 읽기 요청을 분산시킨다는 점에서 부하가 줄어드는 것은 당연한 사실입니다.
더 학습해봐야할 키워드
- OSIV
- LazyConnectionDataSourceProxy
- DataSource
- 프록시 객체
- 트랜잭션 동기화
- TransactionSynchronizationManager
- 글로벌 트랜잭션
특히 초기에 LazyConnectionDataSourceProxy 를 미적용했을때 트랝개션 ReadOnly 속성값을 제대로 못 읽어오는 이슈가 발생했었는데, 이에 관련해 조만간 깊게 학습해보고자 한다.