MySQL Master/Slave 레플리케이션 구조로 DB 라우팅을 구축해보자!
레플리케이션 도입배경
데이터베이스 클러스터링(Clustering) 과 샤딩(Sharding) 을 활용한 고가용성과 스케일아웃 에서도 다루었듯이, 어떤 방식으로 데이터베이스 분산 환경을 구축할지에 대해 학습 했었습니다. 결국 레플리케이션을 도입해야겠다는 결론을 내리게되었고, 지금부터 그 구축 환경에 대해 다루어보고자 합니다. 또한 어떻게 스프링부트 애플리케이션에서 DataSource 로 분기처리를 진행했는지는 곧 바로 다음 포스팅에서 다루어보고자 합니다.
레플리케이션에 대한 자세한 설명은 MySQL 의 Master/Slave 레플리케이션(Replication) 아키텍처와 토폴로지 구성 방식 에서 다루었으므로 생략한다. 이번에는 오로지 어떻게 구현했는지에 대해서만 다루겠다.
- 상세 도입배경 및 WAS 서버 구축은 곧 바로 이어질 다음 포스팅에서 다루겠다. 이번에는 MySQL 레플리케이션 환경 구축 그 자체에 대해서만 다룬다.
MySQL 환경
전반적인 개발 환경은 아래와 같습니다.
- Spring Data JPA
- 인프라에 EC2 로 MySQL 서버를 2대 띄웠다.
- Ubuntu 22.04 LTS 를 기준으로 진행했다.
MySQL 설치
우선 Ubuntu 서버에 아래와 같이 MySQL 을 설치해줍시다.
$ apt update
$ apt install mysql-server외부 접속허용
MySQL 은 기본적으로 localhost 에서만 접속이 가능한데, 당연히 외부에서도 접속이 가능해야 할것입니다. Master, Slave 서버 모두 외부에서 접속이 가능하도록 변경해줍시다.
vi /etc/mysql/mysql.conf.d/mysqld.cnf
# bind-address = 127.0.0.1
# mysqlx-bind-address = 127.0.0.1Master 서버
우선 마스터 서버부터 작업을 시작해봅시다. "replication" 이라는 데이터베이스를 MySQL 안에 하나 생성해주고, 해당 데이터베이스의 작업내용들이 Slave 서버에 복제되도록 할 것입니다.
$ sudo mysql -u root -p // 또는 "sudo mysql"
$ create database replication; // "replication" 데이베이스 생성
$ show databases; // "replication" 데이터베이스 잘 생성되었는지 확인또한, 마스터 서버에서 변경사항(이벤트) 가 발행했을때 슬레이브 서버가 마스터 서버에 접근하여 바이너리 로그 파일 의 변경사항을 읽어와야 하는데, 이렇게 마스터 서버에 접근하고 복제를 가능케하는 "레플리케이션 전용 계정" 을 하나 생성해줘야 합니다. 즉, 이 계정은 슬레이브 서버에서 마스터 서버에 접근할 때 사용합니다.
$ CREATE USER 'replication'@'%' IDENTIFIED WITH mysql_native_password BY 'password';
$ GRANT REPLICATION SLAVE ON *.* TO 'replication'@'%';Master 기능 비활성화 상태에서 더미데이터 삽입
생성한 "replication" 데이터베이스에 접속하여, "user" 라는 테이블을 하나 생성해주고 그 안에 더미데이터를 넣어줍시다.
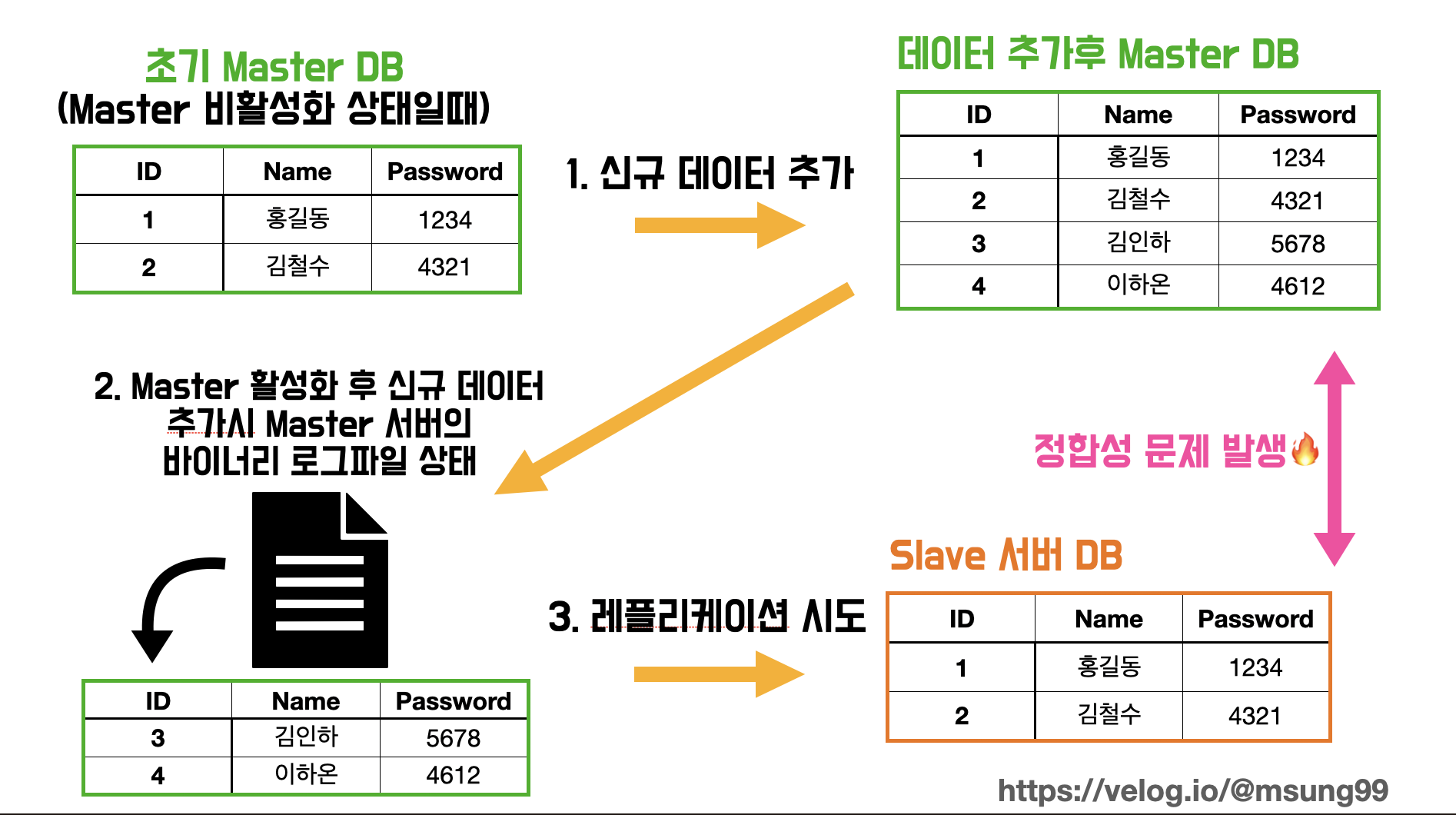
이전에 설명했듯이, 모든 변경사항(이벤트) 는 마스터 서버의 바이너리 로그 파일 에 기록됩니다. 마스터 서버의 바이너리 로깅 기능이 활성화되고나서 모든 이벤트는 파일에 기록된다는 것입니다. 즉, 아래와 같이 user 테이블을 생성하고 더미데이터를 넣는다고 한들, 아직 바이너리 로깅이 비활성화 상태이기 때문에 (아직 애초에 마스터 서버로 활성화된 상태가 아니기 때문에) 파일에는 아직 아무런 이벤트가 기록되지 않을겁니다.
왜 이런 과정을 넣었냐면, 실제로 운영중인 서비스의 DB 에 대해 레플리케이션을 도입하려는 상황을 가정한것입니다. Master 서버 기능을 활성화 한다면 기존 데이터들은 새롭게 발생한 "변경사항" 이 아니므로 바이너리 로그 파일에 기록된 상태가 아닐것이고, 결국 레플리케이션 대상에서 제외될 것입니다. 이런 상황에서 기존 DB 의 데이터들을 어떻게 복제할지가 관건인데, 이는 "dump(백업)" 을 통해 해결 가능합니다. 이에 대한건 아래에서 자세히 다루겠습니다.
$ use replication;
CREATE TABLE user(
id BIGINT NOT NULL AUTO_INCREMENT,
name VARCHAR(255),
PRIMARY KEY(id)
);
insert into user (name)
values ('name1');
insert into user (name)
values ('name2');
insert into user (name)
values ('name3');mysqld.cnf
앞서 수정했던 mysqld.cnf 를 다시 열고, 그 안에 아래와 같이 작성해줍시다. 마스터 서버의 복제가 발생할때 어떻게 어떤 방식으로 처리할지에 대한 옵션을 부여한다고 보면 됩니다.
$ vi /etc/mysql/mysql.conf.d/mysqld.cnf
[mysqld]
max_allowed_packet=1000M
server-id = 1
log-bin = mysql-bin
binlog_format = ROW
max_binlog_size = 500M
sync_binlog = 1
expire-logs-days = 7
binlog_do_db = replication-
[mysqld]: MySQL 서버의 전역설정 정보를 나타내는 것입니다. -
max_allowed_packet: 클라이언트와 서버 간에 교환되는 최대 네트워크 패킷 크기로, 여기서는 패킷의 최대 크기가 1000MB 로 설정된 것입니다. -
server-id: 레플리케이션을 위해 서버에 할당된 고유한 식별자입니다. 이전에 다루었듯이, 레플리케이션 토폴리지 내의 서버는 각각 고유한 서버 ID 값을 가져아하므로, 이 값은슬레이브 서버와 달라야합니다. -
log-bin: 바이너리 로그 파일의 위치(경로) -
binlog_format: 바이너리 로그 파일에 저장되는 데이터의 저장 형식을 지정하는 것입니다.STATEMENT,ROW,MIXED이 3가지 중 하나를 선택할 수 있습니다. -
max_binlog_size: 바이너리 로그 파일의 최대 크기로, 지정된 크기에 도달하면 새로운파일이 생성됩니다. -
sync_binlog: 바이너리 로그 파일이 디스크에 동기적으로 기록되도록 지정하는 것으로, 1은 가장 안정적으로 기록되지만, 가장 느린 설정입니다. -
expire-logs-days: 바이너리 로그 파일의 만료기간으로, 위처럼 7일을 설정하면 이 이후로는 파일이 삭제됩니다. -
binlog_do_db: 레플리케이션을 적용할 데이터베이스의 이름을 지정하는 것으로, 앞서 만든 "replication" 데이터베이스의 이름을 지정해줬습니다. 별도의 설정이 없다면, 모든 데이터베이스를 대상으로 복제가 진행됩니다.
Master 서버 상태값 조회
모든 작성이 끝났다면, MySQL 서버를 다시 재가동해봅시다.
$ service mysql restart그러고 해당 Master 서버의 상태를 조회해봅시다. 레플리케이션을 실행시 File 과 Position 값을 기반으로 동기화 진행되니, 이 값을 기억해둡시다.
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 157 | replication | | |
+------------------+----------+--------------+------------------+---------------Position
이때 Postition 값을 무엇을 의미할까요?
이전에 다루었듯이, 마스터 서버는 Binary Logging 이 활성화되면 마스터의 모든 데이터 구문이 바이너리 로그 파일 에 저장되며, 이 로그 내용들을 슬레이브 서버가 읽어오는 방식으로 복제가 된다고 했었습니다. 따라서 slave는 log 파일내의 position을 유지할 필요가 있습니다. 그래야 로그파일 전체를 처음부터 읽지 않고 효과적으로 로그 파일을 운영할 수 있기 때문입니다. 여기서 position 은 바이너리 로그 파일 내의 위치를 의미하며, 어느 부분부터 읽겠다는 것을 의미합니다.
이어서 슬레이브 서버를 셋팅할때, 이 Position 값을 부여해주면 Slave 서버는 해당 위치값에서 부터 계속 변경 위치값을 계속 추적해가면서 최근에 변경사항이 기록된 필요한 위치에서부터 레플리케이션을 수행하는 방식입니다. 그래야 변경사항이 생긴 부분만 읽을것이며, 불필요하게 바이너리 로그 파일의 맨 처음부터 읽을 필요없이 변경사항의 기록된 필요한 부분만 읽어오면 되기 때문입니다.
Slave 서버
마스터 서버와 마찬가지로 "replication" 이라는 데이터베이스를 생성해줍시다.
$ CREATE DATABASE replication; // 슬레이브 서버도 동일한 명으로 DB 를 생성해준다
$ show databases; // 잘 생성되었는지 확인백업파일 생성 및 동기화
앞서 언급했듯이, 마스터와 슬레이브 서버간의 정합성 문제 가 발생할 수 있으므로 "백업" 을 진행해야 한다고 했었습니다. 아래와 같이 진행해줍시다.
우선 마스터 서버에서 백업 파일을 생성해줍시다.
// 1. 마스터 서버에서의 작업내용
mysql> FLUSH TABLES WITH READ LOCK; // 테이블 락
mysql> exit
mysqldump -u root -p -B replication > backup.sql;
// 마스터 서버의 "replcation" 데이터베이스에 기반한 백업 파일생성
UNLOCK TABLES; // 테이블 락 해제그러고 scp 와 같은 다양한 방법으로 마스터 서버의 백업 파일을 슬레이브 서버에 전송해줍시다.
// 2. scp 전송
scp dump_file.sql root@[슬레이브 서버 IP 또는 호스트명]:/home/ubuntu/dump_file.sql마지막으로 전달받은 백업 파일을 슬레이브 서버의 "replication" 데이터베이스에다 내용을 복원해줍시다.
// 3. 슬레이브 서버에서의 작업내용
mysql -u -p replication < dump_file.sql;이렇게 진행했다면, 마스터 서버의 "replication" DB 의 내용이 슬레이브 서버에서 새롭게 생성한 "replication" DB 에 동기화 됩니다.
mysqld.cnf
mysqld.cnf 에 접속하여 마스터 서버와 마찬가지로 속성을 부여해줍시다. 동일한 레플리케이션 토폴로지 내에서는 각 서버가 유일한 id 값을 지녀야한다고 했기 때문에 server-id = 2 로 별도의 값을 부여했습니다. 또한 슬레이브 서버를 읽기전용 으로 구축하기 위해 read_only=1 을 부여했습니다. 추후에 다룰 포스팅에서 자세히 설명하겠지만, @Transactional(readOnly = true) 가 부여된 API, 즉 읽기전용 API 에 대한 요청들은 슬레이브 서버로 유입되게 할 것입니다.
replicate-do-db 로 마스터 서버의 어떤 데이버베이스를 복제할 것인지 지정할 수 있는데, 앞서 마스터 서버에서 생성한 "replication" 데이터베이스를 지정했습니다. 결과적으로 방금전에 슬레이브 서버에서 만든 replication 데이터베이스에 원활히 복제가 수행됩니다.
$ vi /etc/mysql/mysql.conf.d/mysqld.cnf
[mysqld]
server-id = 2
replicate-do-db = replication
read_only = 1설정이 끝났다면 재실행시켜줍시다.
$ service mysql restartMaster 서버 접속설정 및 Slave 기능(레플리케이션) 활성화
MASTER_USER 와 MASTER_PASSWORD 에는 앞서 생성한 레플리케이션 전용 계정에 대한 정보를 넣어줍시다. 또 MASTER_LOG_FILE 와 MASTER_LOG_POS 에는 앞서 기억해둔 마스터 서버의 상태값들로 설정해줍시다.
RESET SLAVE;
CHANGE MASTER TO
MASTER_HOST='xx.xxx.xxx', # 마스터 서버 IP 주소
MASTER_USER='replication', # 레플리케이션 전용 계정 기입
MASTER_PASSWORD='password',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=157;
START REPLICA;레플리케이션 동작 확인
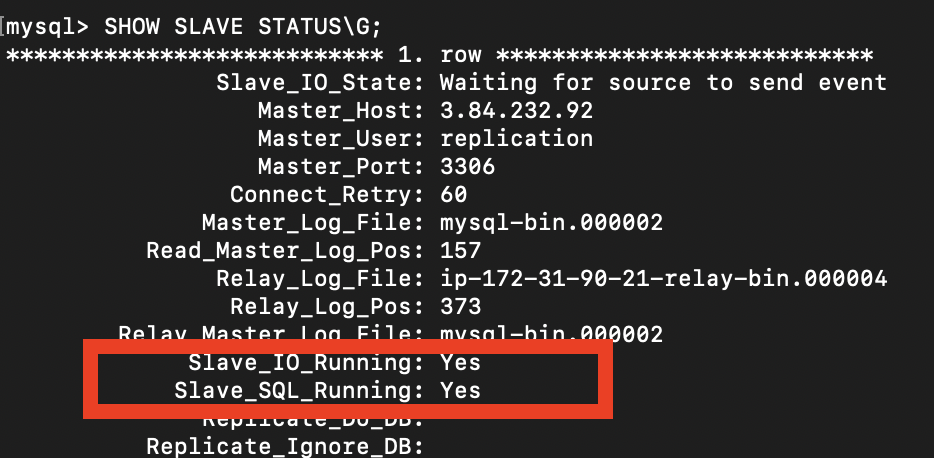
슬레이브 서버에서 레플리케이션이 잘 동작하는지 조회해봅시다. Slave_IO_Running 과 Slave_SQL_Running 이 둘다 "Yes" 가 되어야 정상 동작하는 것이며, 만약 하나라도 "No" 인 경우라면 에러 로그를 조회해보고 적절히 처리해줘야합니다.
SHOW SLAVE STATUS\G;
// 아래 명령어는 레플리케이션이 동작하지 않을때만 활용하면 됩니다.
// STOP REPLICA; // => 에러를 해결하고나서 "RESET SLAVE;" 부터 다시 활성화시킬때, 레플리케이션을 먼저 종료해야한다.실제로 조회했을때, 아래와 같이 YES 가 보이면 레플리케이션이 정상 동작하는 것입니다.
레플리케이션 직접 확인해보기
이렇게까지 잘 설정했다면, 실제로 레플리케이션이 동작하는지 직접 확인해봅시다. 마스터 서버에서 insert 로 새로운 데이터를 넣어도 좋고, create table 로 새로운 스키마를 생성해도 좋습니다. 어떤 내용이던 정상 반영될것입니다.
결론
이렇게 MySQL Replication 을 활용하여 Master-Slave 방식으로 분산 환경을 구축해봤습니다. 내용이 꽤 어려워서 꽤나 애먹고 삽집을 많이 했던것같네요 😓 다음 포스팅에서는 스프링부트 애플리케이션에서 DataSource 빈 등록을 통해, 현재 구축한 레플리케이션 환경과 연동하여 실제 API 서버를 구축해 볼 예정입니다.