현 데이터베이스 파티셔닝과 샤딩 기법은 MySQL 8.0 을 기준으로 한다.
학습배경
이전에 데이터베이스에 관해 최대한 열심히 깊게 공부해보고, "파티셔닝" 에 대해 공부해볼 키워드를 발견 했었지만 이에대해 학습한 경험이 없어서 제대로 이해하지 못한체 넘어가게 되었습니다. 따라서, 추후 데이터베이스 적재 방식을 원활히 고려할 수 있도록 파티셔닝에 대해 학습하고자 합니다.
이번 포스팅에서는 파티셔닝에 대한 이론만 오로지 다루도록 하고, 구현방법은 다루지 않도록 합니다. 또한, 이전에 학습했던 샤딩(Sharding) 이 파시셔닝과 함께 묶이는 학습 키워드로 판단되므로, 샤딩을 복습 차원에서 아주 간단히만 언급하도록 합니다.
샤딩에 대한 자세한 설명은 데이터베이스 클러스터링(Clustering) 과 샤딩(Sharding) 을 활용한 고가용성과 스케일아웃 을 참고하자.
파티셔닝(Partitioning)
데이터베이스의 고가용성
서비스의 크기가 점점 거대해지고 데이터베이스에 저장하는 데이터 수가 매우 커지면서, DB 시스템상 저장용량의 한계에 도달할 수 있게됩니다. 즉, 하나의 DB 에 너무 큰 테이블이 들어가면서 용량과 성능의 큰 저하가 발생할 수 있게됩니다. 이를 해결하도록 테이블을 "파티션(Partition)" 이라는 작은 단위로 분할하여 관리하는 파티셔닝 기법이 등장하게 되었습니다. 즉, 데이터베이스를 분산 처리하여 성능이 저하되는 것을 방지하고 관리를 보다 수월하게 할 수 있습니다.
파티셔닝이란?
파티셔닝이란 논리적인 데이터 원소들을 다수의 Entity 로 쪼개는 행위를 뜻삽니다. 즉, 큰 테이블이나 인덱스(index) 를 관리하기 쉬운 파티션(Partition) 이라는 작은 단위로 물리적으로 분할하는 것입니다. 물리적인 데이터 분할이 발생하더라도 데이터베이스에 접근하는 애플리케이션이 이를 인식하지 못합니다. 즉, 사용자는 마치 하나의 테이블에 접근하는 것과 같이 사용할 수 있다는 것이 특징입니다.
파티셔닝의 종류
수직(horizontal) 파티셔닝
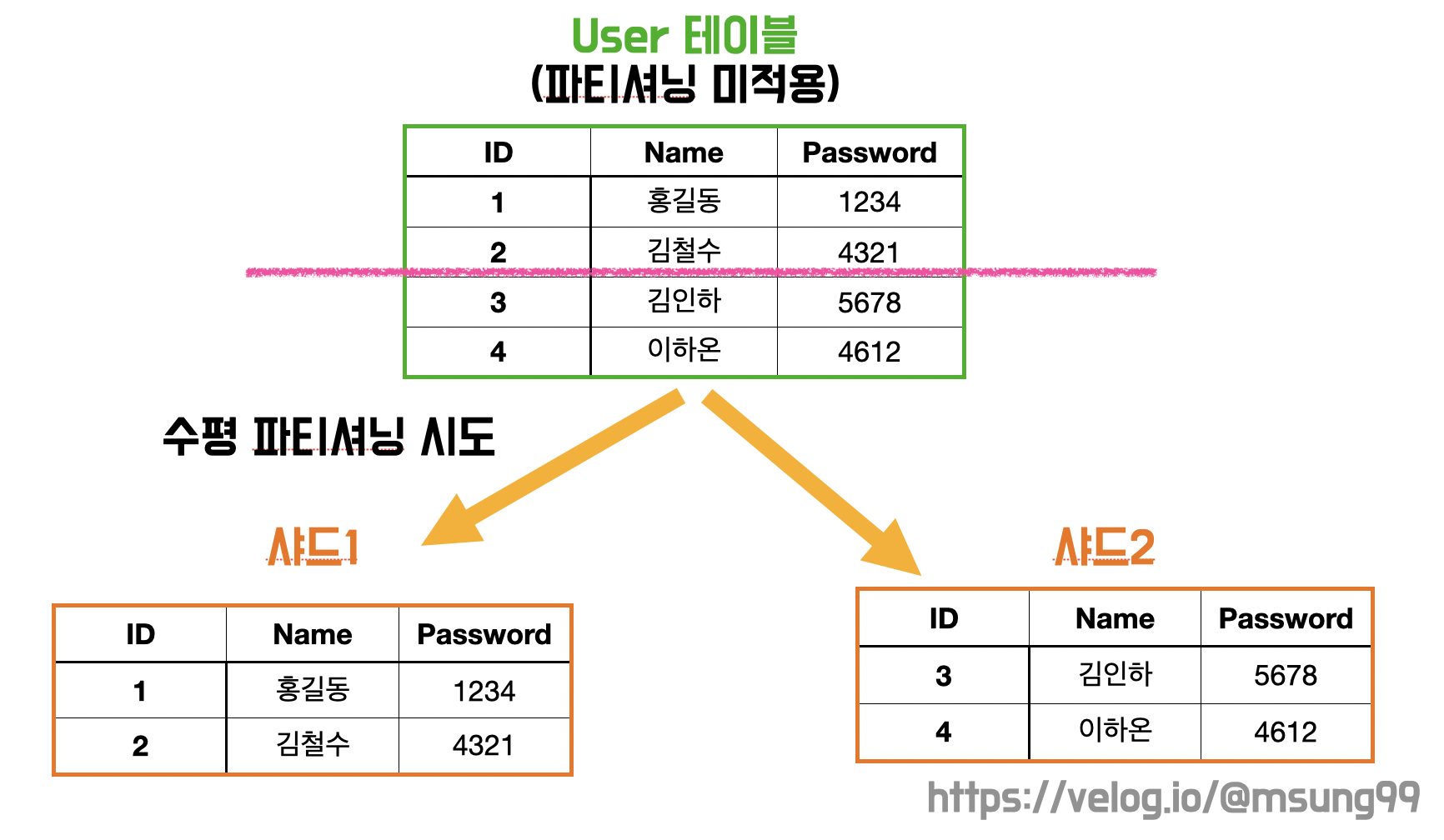
하나의 테이블의 각 행을 다른 테이블에 분산시키는 방법입니다. 샤딩(Sharding) 과 동일한 개념으로, 스키마를 복제한 후 샤드키를 기준으로 데이터를 분할하는 방식입니다. 즉**, 스키마가 같은 두 데이터를 2개 이상의 테이블에 나누어 저장하는 것입니다.** 예를들어 User 테이블에서 userID 를 사드키로 활용하여 샤딩하기로 한다면, 01000 번 유저의 정보는 샤드1 에 저장하고, 10012000 번 유저의 정보는 샤드2 에 저장합니다.
장점
한 테이블의 데이터들을 "개수" 를 기준으로 나누어 분할하므로 데이터의 개수가 작아지게 됩니다. 따라서 인덱스(index) 의 개수도 작아지게 되고, 자연스래 성능을 향상됩니다.
단점
데이터를 찾는 과정이 기본 방식보다 복잡하므로 레이턴시(latency) 가 증가하게 됨, 여러 데이터베이스 서버들중에 하나의 서버에 장애가 발생하게 되면 데이터 무결성이 깨질 수 있습니다.
수직(vertical) 파시셔닝
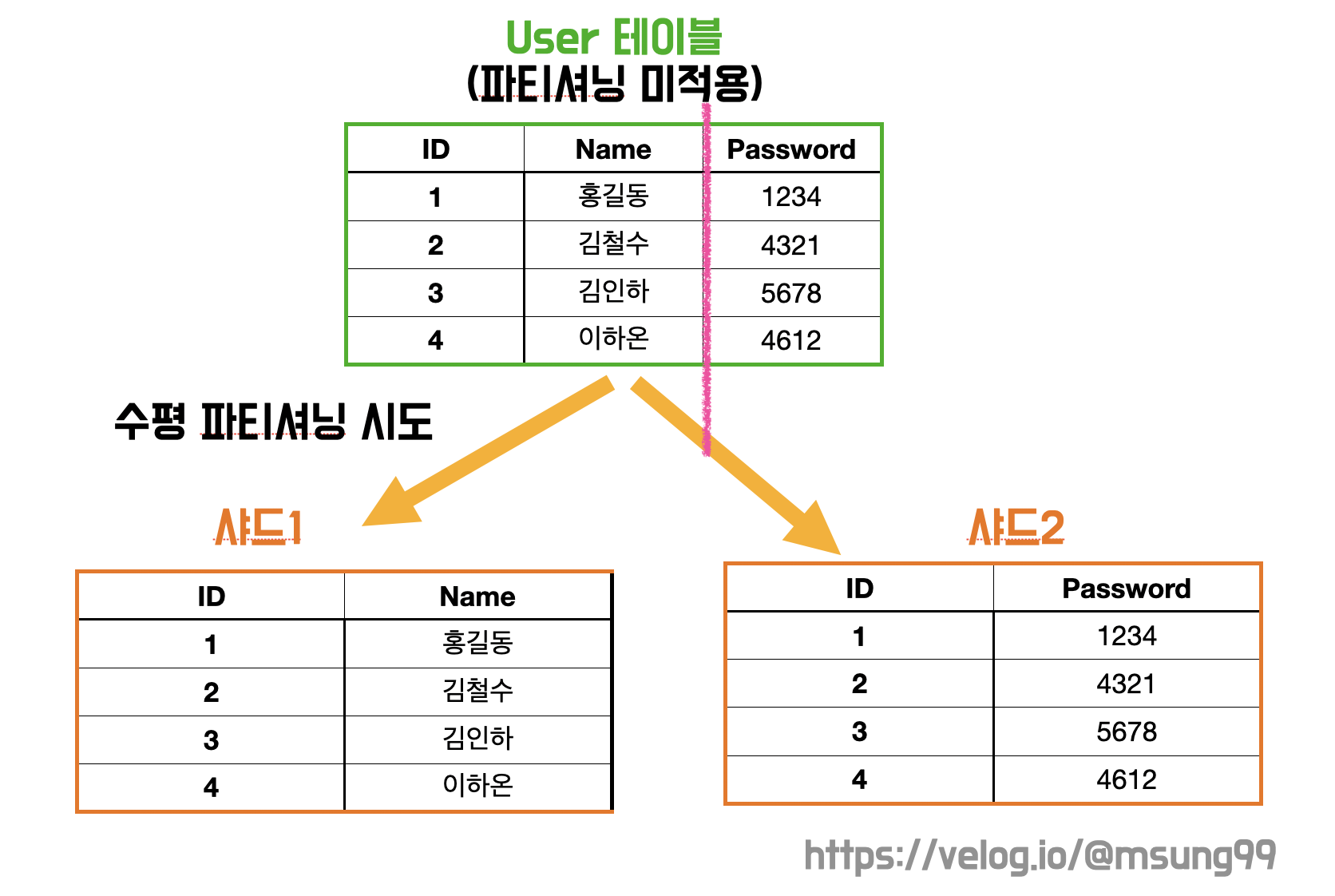
테이블 일부 컬럼(Column) 을 빼내는 형태로 분할합니다. 모든 컬럼들 중 특정 컬럼들을 쪼개서 따로 저장하는 형태로, 하나의 엔티티(스키마) 를 2개 이상으로 분할하는 작업입니다.
장점
자주 사용하는 컬럼들을 분리시켜서 성능을 향상 시킬 수 있으며, 한 테이블을 select 하면 모든 컬럼들을 메모리에 올리게 되므로, 필요없는 컬럼까지 올라가서 한번에 읽을 수 있는 ROW 수가 증가하게 됩니다. 이는 I/O 측면에서 봤을때 필요한 컬럼만 올리면 훨씬 많은 수의 ROW 를 메모리에 올릴 수 있으니 성능상의 장점이 됩니다. 또한 같은 타입의 데이터가 저장되기 때문에 그룹화가 되어서, 데이터의 응집성을 높일 수 있게됩니다.
단점
마찬가지로 데이터를 찾는 과정이 복잡해지므로 레이턴시(Latency) 가 증가합니다.
파티셔닝의 분할기준(범위)
DBMS 는 파티셔닝에 대해 각종 기준(분할 기법) 을 제공하고 있습니다. 분할은 "분할 키(partitioning key)" 를 활용합니다.
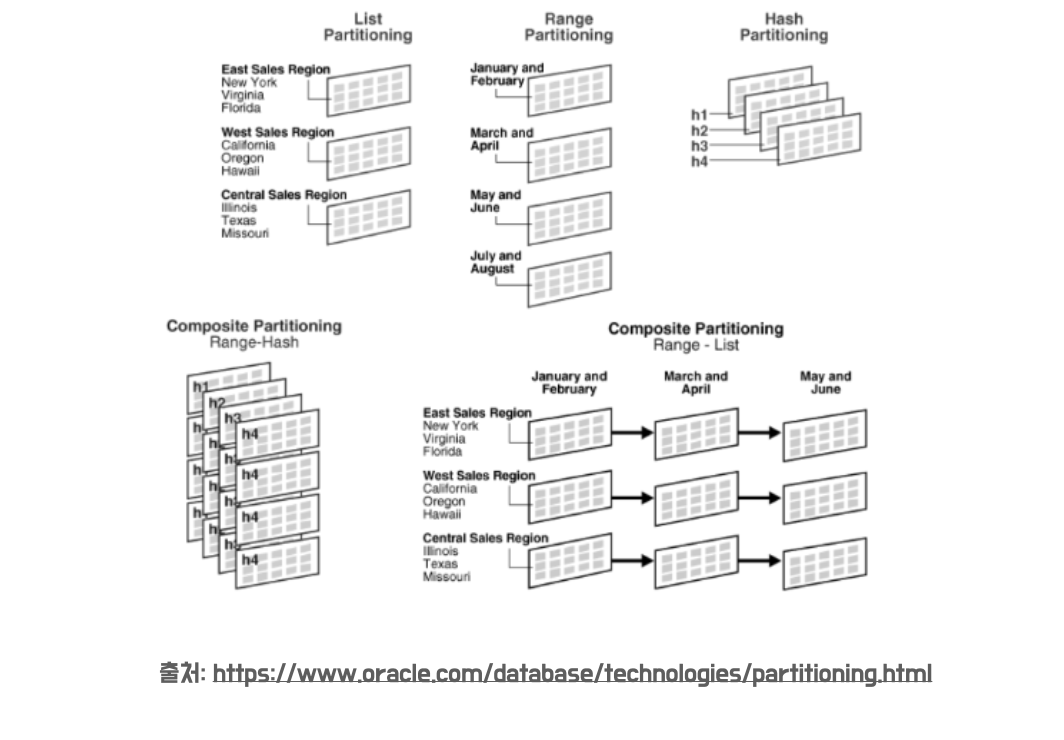
범위 분할(Range Partitioning)
데이터를 특정 범위를 기준으로 분할할 때 사용하는 방식으로, 연속적인 숫자나 날짜를 기준으로 파시셔닝 하는 방식입니다. 위처럼 12월, 34월, 5~6월, ... 으로 데이터를 분리할 때 사용할 수 있습니다.
목록 분할(List Partitioning)
데이터 값이 특정 목록에 포함된 경우 데이터를 분리합니다. 분포도가 비슷하며, 많은 SQL 에서 해당 컬럼에 조건이 많이 들어오는 경우에 유용합니다. 예를들어 위처럼 특정 지역별로 데이터를 분할할 때 사용할 수 있습니다.
해시 분할(Hash Partitioning)
해시 함수를 사용하여 데이터를 분할하는 방식으로, 특정 컬럼의 값을 해싱하여 저장할 파티션을 선택합니다. 데이터의 균등 분할을 통해 성능을 향상하고자 하는 경우에 효율적입니다.
공식문서에 따르면 여러 컬럼으로 해싱하는것은 크게 권장하지 않는 방법이라고 합니다. 만약 활용한다면, 유저 ID 처럼 변별력이 좋고 데이터 분포가 고른 컬럼을 파티션 키 컬럼으로 선정해야 효과적입니다.
합성 분할(Composite Partitioning)
위 파티셔닝 종류들 중에 2개 이상의 방식을 혼합하여 사용하는 방식입니다. 단, 파티션을 나누는 기준이 너무 많아지면 파티션 개수가 너무 많아지게 될것이고, 인덱스의 경합이 너무 심해져서 잘 사용하지 않는 방법이라고 합니다.
샤딩(Sharding)
이전에 언급했듯이, 샤딩은 이전에 다룬 내용이므로 아주 간단히만 복습 차원에서 키워드를 언급하도록 하겠습니다.
Hash Sharding
해시 샤딩은 해시함수를 활용하여 PK 값을 나머지 연산한 결과값으로 어떤 샤드에 들어갈지 결정하는 방식입니다. 샤드의 수만큼 해싱을 하면 되기 떄문에 간단한 방식입니다.
대신 데이터베이스 개수가 줄어들거나 늘어나면 해시 함수도 변경해야하므로, 데이터의 정합성이 깨질 수 있다는 위험때문에 데이터의 재정렬 작업이 필요해집니다.
Range Sharding
PK 값을 범위로 지정하여 샤드를 결정하는 방식입니다. 예를들어 PK 가 11000번인 데이터는 1번 샤드에, 10012000번 데이터는 2번 샤드에 저장합니다.
해시 샤딩에 비해 데이터베이스 증설 작업에 용이하므로, 떄문에 급증할 수 있는 데이터는 Range Sharding 을 사용하는것이 좋을겁니다. 다만 기껏 분산을 시켰는데 특정 데이터베이스에만 부하가 몰릴 수 있다는점을 유의해야합니다.
참고
- https://dev.mysql.com/doc/refman/8.0/en/partitioning.html
- https://docs.oracle.com/en/database/oracle/oracle-database/19/vldbg/partition-concepts.html#GUID-5AE7BBD6-02C1-4DB4-BB5B-B4E5B4C96FAD
- https://gmlwjd9405.github.io/2018/09/24/db-partitioning.html
- https://code-lab1.tistory.com/202
- https://coding-factory.tistory.com/840
- https://hudi.blog/db-partitioning-and-sharding/