파드(Pod) 란 무엇이고, 왜 써야할까?
이전에 설명했듯이 파드는 쿠버네티스의 기본 빌딩 블록입니다. 일반적으로 파드는 하나의 컨테이너만 포함합니다. 또 파드가 여러 컨테이너를 가지고 있을 경우에, 모든 컨테이너는 항상 하나의 워커 노드에서 실행되며 여러 워커 노드에 걸쳐 실행되지 않습니다.
파드안에 있는 모든 컨테이너는 동일한 1개의 노드에서 실행된다. 절대로 두 노드에 걸쳐서 배포되지 않는다!
연관된 프로세스 묶음 단위
[Docker] 도커는 어떻게 동일한 호스트에서 여러 프로세스를 컨테이너 단위로 격리시킬 수 있는걸까? 에서 도커는 컨테이너 별로 격리된 프로세스를 보장합니다. 컨테이너 모음을 사용해서 밀접하게 연관된 프로세스를 함께 실행하면서 마치 단일 컨테이너 안에서 여러개의 프로세스가 함께 실행되는 것처럼 보이게 할 수 있습니다.
같은 파드안의 컨테이너들의 격리수준을 다소 완화한다
또 컨테이너 별로 서로 완벽히 격라된 환경이 구성된다고 했었으나, 쿠버네티스에서는 각 컨테이너 단위로 격리되는 것이 아닌 파드(Pod) 라는 컨테이너 그룹별로 격리된 환경을 구성합니다. 즉, 쿠버네티스에서는 파드 안에 있는 모든 컨테이너가 자체 네임스페이스가 아닌 동일한 리눅스 네임스페이스를 공유하도록 도커가 설정되는 것이죠.
그에 따라서 파드 안에있는 컨테이너들이 특정 리소스들을 함께 공유하기위해 각 컨테이너가 완벽히 격리되지 않도록 하고, 격리수준이 다소 완화되도록 하는 것입니다. 파드의 모든 컨테이너는 같은 호스트 이름과 네트워크 인터페이스를 공유하게 됩니다.
동일한 IP 와 포트 공간을 공유하는 방법
다시 한번 되짚고 넘어갈 사항은, 파드 안의 컨테이너들은 동일한 네트워크 네임스페이스에서 실행되기 때문에 동일한 IP 주소와 포트 공간을 공유한다는 것입니다.
따라서 동일한 파드 안의 컨테이너게서 실행중인 프로세스들은 같은 포트 번호를 사용하지 않도록 주의해야 합니다. 그렇지 않으면 포트 충돌 이 발생하겠죠. 해당 파드의 모든 컨테이너들은 동일한 루프백 네트워크 인터페이스를 갖기 때문에, 컨테이너들이 로컬호스트를 통해 통신할 수 있습니다.
파드 사이의 플랫 네트워크
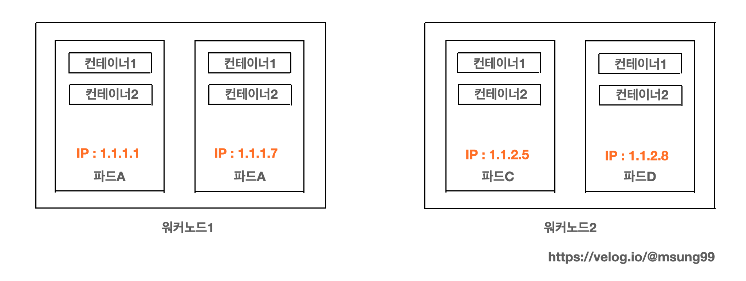
또 클러스터의 모든 파드는 하나의 플랫한 공유 네트워크 주소 공간에 상주하기 때문에, 모든 파드는 다른 파드의 IP 주소를 사용해서 접근하는 것이 가능합니다. 동일한 워커노드에 있는 파드 간에 통신이 가능하죠.
파드의 컨테이너들을 어떻게 구성해야하는가?
파드는 특정한 애플리케이션들을 호스팅합니다. 여러 종류의 애플리케이션들을 모두 파드 하나에 넣는 대신에 여러 파드로 구성 및 분배시키고, 각 파드에는 밀접하게 관련있는 구성요소나 프로세스만 포함해야합니다.
기능 및 서비스별로 애플리케이션들을 여러 파드에 분할하자
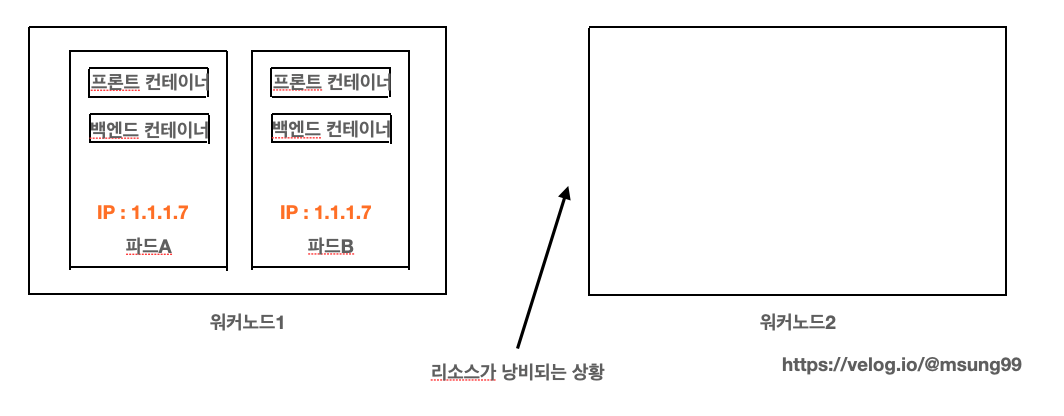
예를들어 위처럼 프론트, 백엔드 서버 컨테이너가 있을떄 이 둘을 한 파드에 놓는다면 다소 아쉬운 부분이 생깁니다. 백엔드 서버에서만 필요한 기능을 위해 파드를 건드릴때, 동일한 파드에 존재하는 프론트 서버 컨테이너도 함께 같은 워커노드에서 실행되어야 하기 때문이죠.
또 클러스터에 2개의 워커노드가 있다고해보죠. 그 중에 1번째 워커노드안의 단일 파드에서 모든 애플리케이션이 실행된다면 워커 노드 1개만 사용해버리고 2번째 노드에서는 가만히 놀고있는 상태라서 이용할 수 있는 컴퓨팅 리소스(CPU 와 메모리) 를 활용하지 못하고 낭비하게 됩니다.
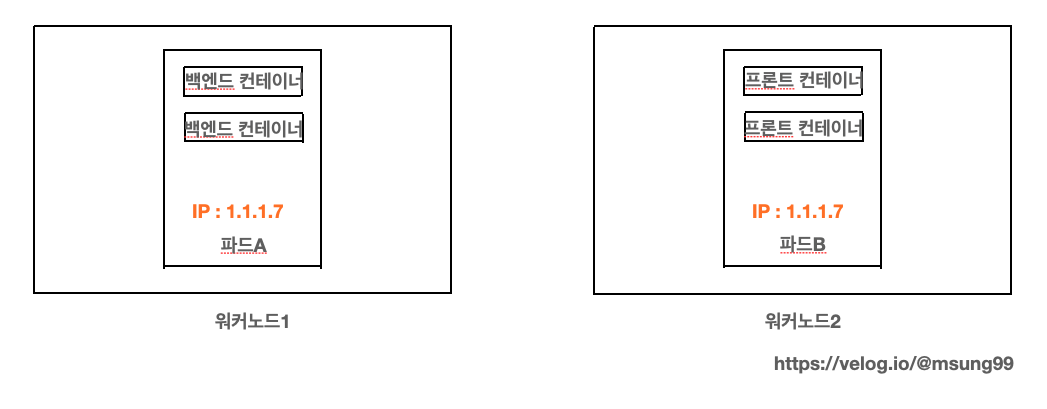
따라서 파드를 세분화해서 여러 에플리케이션 프로세스를 분산시킬경우, 각 애플리케이션은 각기 다른 노드 여러개에 스케줄링되어서 infra structure 의 활용도를 향상시킬 수 있게됩니다.
개별 확장이 가능하도록 여러 파드로 분할하자
또 여러 컨테이너를 단일 파드에 마구잡이로 넣으면 안되는 이뉴는 스케일링 때문입니다. 수평확장(Scale Out) 의 기본단위는 파드인데, 각 애플리케이션 특성별로 확장해야하는 정도가 다릅니다.
여러 컨테이너를 파드로 묶을때 고려해야할 요소들
따라서 컨테이너를 파드로 묶어서 그룹을 만들때는, 단일 파드로 넣을지 또는 2개이상의 여러 파드에 세분화해서 넣을지 결정하도록 아래와 같은 요소들을 고려해야합니다.
- 여러 컨테이너를 함께 실행해야 하는가, 또는 서로 다른 호스트에서 실행할 수 있는가?
- 여러 컨테이너가 모여서 하나의 구성 요소를 나타내는가, 또는 개별적인 구성 요소인가?
- 컨테이너가 함께, 혹은 개별적으로 스케일링돼야 하는가?
YAML 디스크립터로 파드 생성
이제부터 YAML 매니페스트를 작성해서 파드를 생성해봅시다. 파드를 포함한 쿠버네티스의 리소스들은 일반적으로 쿠버네티스 Rest API 엔드포인트에 JSON 또는 YAML 매니페시트를 전송하여 생성합니다.
kubectl run 명령어로도 리소스 생성은 가능하지만, 제한된 속성 집합만 설정할 수 있어서 자세한 속성 정보를 가진 리소스 생성을 위해선 디스크립터 작성이 필수입니다.
기본적인 파드의 YAML 디스크립터 조회
우선 지금까지 간편히 구축했던 (YAML 을 사용하지 않고 구축했던) 모든 파드를 조회해봅시다.
kubectl get pods -o wide
기본적인 명령어로 생성한 파드중에 하나를 택해서, YAML 정의가 어떻게 이루어지는지 살펴봅시다.
kubectl get po "파드이름" -o yaml
ex) kubectl get po kubia-59c9558478-4bfgf -o yaml그러면 아래와 같이 파드의 전체 YAML 정의를 조회할 수 있게됩니다.
apiVersion: v1
kind: Pod
metadata:
annotations:
kubernetes.io/created_by: ...
labels:
run: kubia
name: kubia-59c9558478-4bfgf
namespace: default
// ... (중간 생략)
spec:
containers:
- image: msung99/redis-lock:0.1.3
imagePullPolicy: IfNotPresent
name: kubia
ports:
- containerPort: 8080
protocol: TCP
// ... (중간 생략)
status:
conditions:
- lastProbeTime: null
lastTransitionTime: null
statis: "True"
type: Ready
containerStatuses:
- containerID: docker://f028123901203ba...
image: msung99/redis-lock:0.1.3
// ... (이하 생략)복잡해보이지만 핵심적인 구조 틀만 알아보고 넘어갑시다. 우선 위와같이 배포된 파드의 YAML 의 구성요소는 아래와 같은 키워드를 중점으로 알고계셔야합니다.
- apiVersion : 현재 YAML 디스크립터에서 사용한 쿠버네티스 API 버전
- kind : 쿠버네티스 오브젝트(리소스) 유형
- metadata: 파드 메타데이터(이름, 레이블, 어노테이션 등등) 에 관한 정보
- spec: 파드 정의내용 (파드 컨테이너 목록, 볼륨 등등)
- status: 파드와 그 안의 여러 컨테이너들의 상태 정보
그런데 위와 같은 YAML 디스크립터는 기본적으로 생성될 때 자동으로 만들어지는 디스크립터이며, 위안을 삼아보자면 저희가 새로운 파드를 만들때 직접 작성해야하는 YAML 내용은 훨씬 적으니 큰 걱정안하셔도 됩니다. YAML 파일을 간단히 정의해놓고 그에 기반해 파드를 생성하는 명령어를 사용하면, 상세정보가 자동으로 YAML 파일에 채워지고 파드가 생성됩니다. 따라서 위의 핵심 키워드들만 잘 숙지하고 넘어갑시다.
새로운 파드를 정의할 YAML 작성하기
저희는 위에서 알게된 키워드들로 YAML 을 작성하면 새로운 파드를 생성할 수 있습니다. vim 편집기를 열어서 YAML 파일을 새롭게 생성하시고, 그 파일 안에다 아래와 같이 작성해줍시다. 이떄 YAML 파일명은 kubia-manual.yaml 로 하겠습니다.
apiVersion: v1 // 디스크립터는 쿠버네티스 API 버전 v1 를 준수한다.
kind: Pod // 오브젝트 종류를 파드(Pod)로 명시
metadata:
name: kubia-manual // 파드 이름
spec:
containers:
- image: msung99/redis-lock:0.1.3 // 컨테이너를 만드는 컨테이너 이미지
name: kubia // 파드에 생성된 컨테이너의 이름을 kubia 로 지정
ports:
- containerPort: 8080 // 애플리케이션이 수신하는 포트
protocol: TCP보시듯이 앞서 살펴봤던 기본 YAML 파일보다 훨씬 간단하게 작성해도 새로운 파드를 생성할 수 있게됩니다. 위 파일을 해석해봅시다. 우선 이 정의에서는 쿠버테니스 API v1 버전을 중시하며, 리소스 유형은 파드이고, 파드이름은 kubia-manual 입니ㅏ다. 또 msung99/redis-lock:0.1.3 이라는 임지에 기반해 컨테이너가 생성되며 8080포트에서 연결을 기다리는 상태가됩니다.
이때 컨테이너 포트를 지정하지 않아도 (생략해도) 클라이언트에서 포트를 통해 파드에 연결할 수 있는 여부에 영향을 미치지 않습니다. 컨테이너가 0.0.0.0 주소에 열어둔 포트를 통해 접속을 허용할 경우, 파드 스펙에 포트를 명시적으로 나열하지 않아도 다른 파드에서 항상 해당 파드에 접근 가능합니다.
파드 생성 및 조회
앞서 만든 YAML 파일에 기반해 새로운 파드를 생성해봅시다. 또 생성한 파드의 정의 내용도 조회해봅시다. YAML 을 조회해보면, 저희는 분명히 YAML 의 정의문을 간단히 작성했음에도 불구하고 자동으로 상세 정보들이 알아서 채워진 모습을 확인할 수 있을 겁니다.
$ kubectl create -f kubia-manual.yaml // 파드 생성
$ kubectl get po kubia-manual -o yaml // 파드 정의내용 YAML 파일 조회
// 또는 kubectl get po kubia-manual -o json
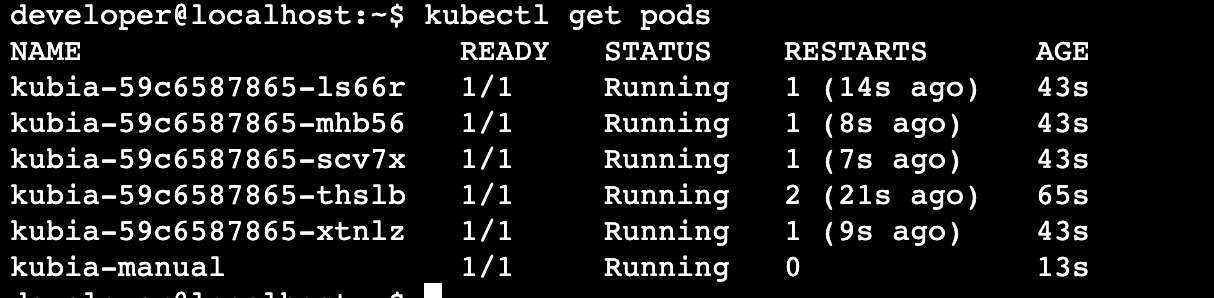
// => YAML 말고 JSON 파일 포맷으로 파드 정의내용 조회하는 것또 파드 목록을 조회해보면, 아래와 같이 kubia-manual 이라는 새로운 파드가 생성된 것을 볼 수 있습니다.
파드에 요청 보내기
위와 같이 여러개의 파드가 실행중일때 어떻게해야 파드의 실제 동작을 볼 수 있을까요? 이전에는 kubectl expose 로 외부에 로드밸런서 IP 를 유출시켜서, 외부에서 파드에 접속할 수 있는 서비스 오브젝트를 만들었습니다.
이번에는 간단한 테스트를 진행하기위해 포트 포워딩 을 구성해서, 서비스를 거치지 않고 특정 파드와 통신해보겠습니다.
$ kubectl port-forward kubia-manual 8888:8080
위와 같이 머신의 로컬포트 8888을 kubia-manual 파드의 8080포트로 향하게 설정해줍시다. 그러면 포트 포워딩이 실행돼 이제 로컬 포트로 파드에 연결할 수 있게됩니다. 앞으로 다른 터미널에서 localhost:8888 에서 실행되고 있는 kubectl port-forward 프록시를 통해 HTTP 요청을 해당 파드에 보낼 수 있습니다.
마치며
지금까지 파드를 어떻게 배치하고 관리하며, YAML 디스크립터를 직접 작성해서 새로운 파드를 작성하는 방법에 대해 다루어봤습니다. 이어지는 포스팅에서는 레이블, 네임스페이스를 통해 파드를 구성하는 기법에 대해 자세히 다루어볼까합니다.