문제 발생배경
현재 진행중인 사이드 프로젝트에서 개발을 진행하다가 Entity N+1 문제 를 발견했습니다. 이를 해결하기 위해, 통상적으로 알려진 Fetch Join 쿼리를 여럿 날렸습니다. 하지만, 깊게 이해하지 못한체 쿼리를 남용하며 날리다보니 MultipleBagFetchException 이슈를 직면하게 되었습니다. 이를 해결하기까지의 어떤 개선 과정이 있었으며, 왜 Fetch Join 을 남용하여 쿼리를 날리면 안되는지에 대해 다루어보고자 합니다.
- N+1 문제, 지연로딩(Lazy Loading), 패치 조인(Fetch Join) 에 대한 이론적인 지식은 추후 포스팅에서 깊게 다루도록 한다.
- 실제 프로젝트 코드는 정책 및 로직 구현 내용이 꽤 복잡하므로, 기본 구현 코드로만 다루도록 한다.
엔티티 매핑관계 소개
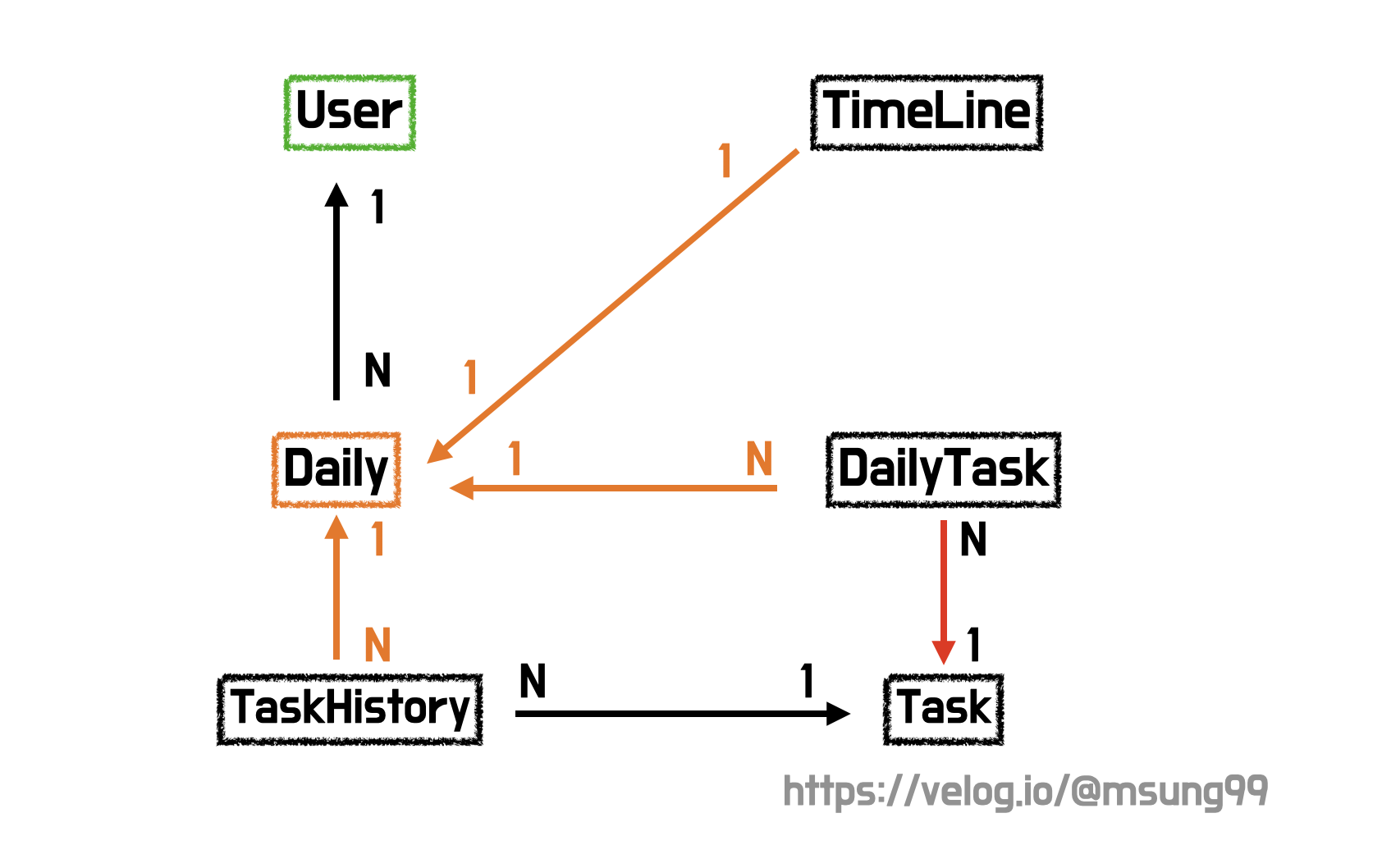
이해를 돕기위해, 각 엔티티 클래스와 매핑 관계를 간략히 소개해보겠습니다. 현재 유저의 모든 Daily 데이터를 조회하는 것이 로직인데, 이를위해 Daily 와 매핑되어있는 TimeLine, DailyTask, TaskHistory 를 조회해야합니다. 또한 Task 엔티티에서 taskName 필드 값 리스트를 추출하기위해, Task 또한 조회해야하는 상황입니다.
Daily
Daily 엔티티에 대한 클래스입니다. 앞서 설명한 매핑 관계가 그대로 담겨있으며, 특히 timeLine 의 경우 OneToOne 의 관계로 담겨있습니다. 또 ManyToOne 관계에 놓여있는 dailyTaskList 의 경우 지연로딩(Lazy Loading) 을 설정해주었는데, 기본값은 즉시로딩(Eager Loadin) 을 수행하므로, 필요한 경우에만 엔티티 조회를 수행할 수 있도록 지연로딩을 설정해줬습니다.
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Daily {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "daily_id")
private Long daily_id;
@Column(name = "max_time")
private Integer maxTime;
@Column(name = "day")
private LocalDateTime day;
@OneToMany(mappedBy = "daily")
private List<DailyTask> dailyTaskList = new ArrayList<>();
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user;
@OneToMany(mappedBy = "daily")
private List<TaskHistory> taskHistoryList = new ArrayList<>();
@OneToOne(mappedBy = "daily")
private TimeLine timeLine;
}DailyRepository (이슈 발생 쿼리)
이번의 핵심 코드라고 할 수 있는 JPQL 쿼리 코드입니다. Fetch join 이 무려 3개나 수행되는 모습을 볼 수 있는데, 여기서 문제가 발생했습니다. 실행 결과를 아래에서 확인해봅시다.
public interface DailyRepository extends JpaRepository<Daily, Long> {
@Query(value = "select m from Daily m join fetch m.timeLine join fetch m.taskHistoryList join fetch m.dailyTaskList d join fetch d.task where m.user = :user")
List<Daily> findDailyAllInfoByUser(User user); // join fetch m.taskHistoryList
}실행결과
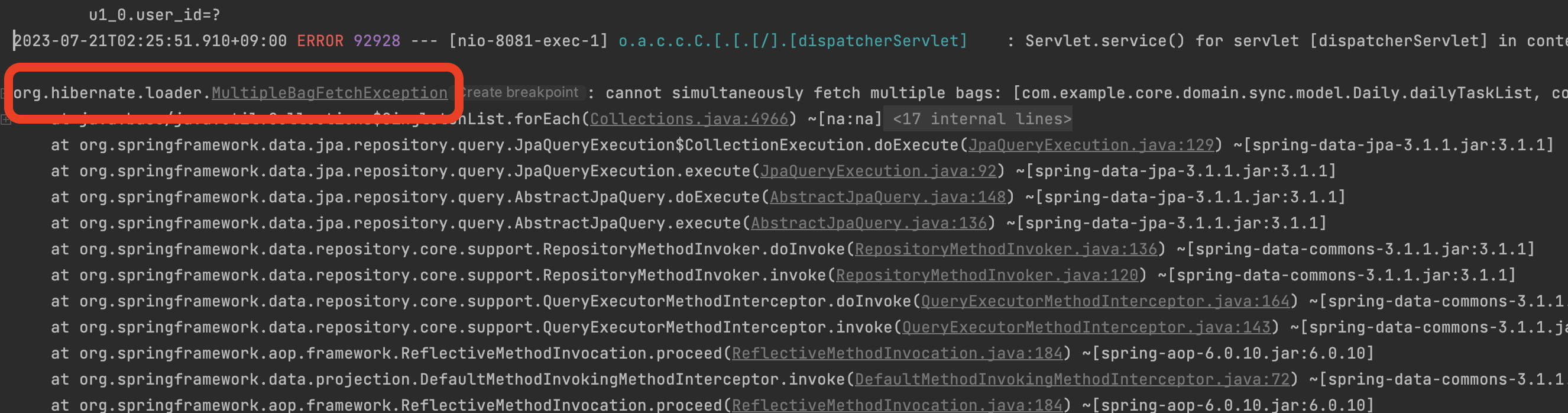
예상했듯이, MultipleBagException 이슈가 발생했습니다. fetch join 을 활용하여 N+1 문제를 해결하기는 커녕, 여러번 Fetch join 을 했더니 문제가 발생했는데, 왜 이렇게 fetch join 을 남발했다고 해서 문제가 발생하는걸까요?
JPA 의 Fetch Join 특징
JPA 에서 Fetch Join 은 N+1 문제를 해결하기 위해서 가장 보편적으로 사용되는 방법입니다. 하지만 이 방식에는 몇가지 사용 조건사항이 따릅니다.
- OneToOne, ManyToOne ("ToOne") 관계에 대해선 몇개든 사용 가능하다.
- ManyToMany, OneToMany ("ToMany") 는 단 1개만 사용 가능하다.
즉, MultipleBagException 은 2개 이상의 자식 엔티티에 대해 fetch join 을 수행했을때 발생하는 이슈입니다. 다시말해서, 본인의 부모 엔티티에 대해선 얼마든지 fetch join 을 마음껏 여러개를 수행해도 상관없습니다.
MultipleBagException 이 왜 발생한거지? 🔥
정리하면, 이 문제는 2개이상의 컬렉션을 Fetch Join으로 로드하려고 하는 경우에 발생합니다. JPA 에서는 여러 개의 컬렉션을 동시에 fetchJoin으로 가져오는 것을 지원하지 않기 때문입니다. 그 이유는 컬렉션 자체가 JPA 에서는 별도의 테이블로 구현되기 때문입니다.
컬렉션 중에서 List 같은 경우는 원소의 순서가 중요하고 중복된 원소를 허용합니다. 이러한 특징 때문에 JPA는 이러한 컬렉션을 여러개를 Fetch Join 하는 경우에 문제가 발생 할 수 있습니다. 이렇게 되면 중복된 데이터가 많이 조회될 수 있기 때문에 이러한 경우에 사전에 방지하고자 MultipleBagFetchException가 발생하는 것입니다.
원인 분석
다시 코드를 살펴봅시다. Daily 의 자식 엔티티인 TimeLine 에 대해선 얼마든지 fetch join 을 수행해도 상관없습니다. 그러나, 부모 엔티티인 TaskHistory 와 DailyTask 에 대해서 동시에 fetch join 을 수행하고 있기 때문에 문제가 당연히 발생할 수 밖에 없었던 것입니다.
public interface DailyRepository extends JpaRepository<Daily, Long> {
@Query(value = "select m from Daily m join fetch m.timeLine join fetch m.taskHistoryList join fetch m.dailyTaskList d join fetch d.task where m.user = :user")
List<Daily> findDailyAllInfoByUser(User user); // join fetch m.taskHistoryList
}대안1 : N+1 문제 일부개선
이슈를 해결하기 위해 여러 접근 방법이 있었습니다. 그나마 괜찮은 해결법으로는, fetch join 을 한 하나의 자식 엔티티에 대해서만 적용하고, 나머지 모든 자식 엔티티에 대해선 지연로딩(Lazy Loading) 하는 방식입니다. 하지만 이는 자식 데이터가 매우 많다면 성능 이슈가 발생할것이 뻔했습니다. 무엇보다 아직 N+1 문제가 해결된 것이 아닙니다.
대안2: Set 컬렉션 활용하기
컬렉션 List 의 중복 문제를 피하기위해, Set 을 활용하여 중복 이슈를 해결할 수 있습니다. 단, Set은 자료구조 특성상 중복허용과 순서 보장이 되지 않는 문제를 잘 생각하고 사용해야 합니다. 또한 성능 이슈가 있다고하니, 이 방법은 여러 문제를 초래할 것으로 판단되어 사용하지 않았습니다.
Batch Size 활성화하기
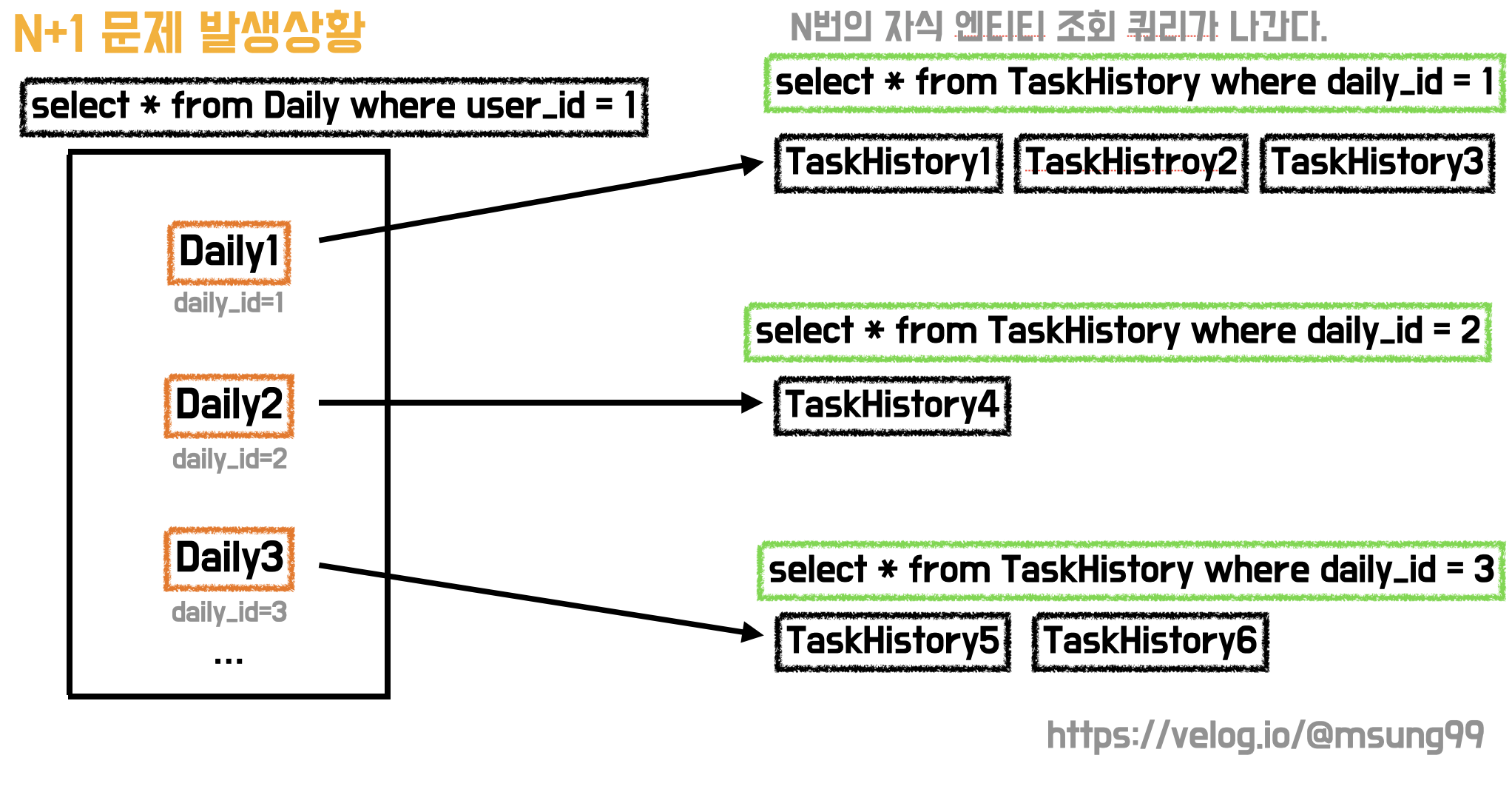
해결첵은 default_batch_fetch_size 옵션을 활성화 및 조절에 있었습니다. 그 전에 N+1 문제가 왜 발생하는지를 생각해보면, 결국 부모 엔티티와 연관있는 여러 자식 엔티티들에 대한 조회 쿼리가 문제인 것 입니다. 부모 엔티티를 조회하며 그의 자식 엔티티들을 fetch join시, 부모 엔티티 Key 값 하나하나를 자식 엔티티를 조회해오는데 활용하기 떄문입니다.
public interface DailyRepository extends JpaRepository<Daily, Long> {
@Query(value = "select m from Daily m join fetch m.timeLine join fetch m.dailyTaskList d join fetch d.task where m.user = :user")
List<Daily> findDailyAllInfoByUser(User user); // join fetch m.taskHistoryList
}MultipleBagException 를 해결하기 위해 기존 코드를 수정했습니다. TaskHistory 에 대한 Fetch Join 을 제거함으로써 에러가 발생하지 않게했죠. 다만, 이러면 TaskHistory 자식 엔티티에 대한 N+1 문제는 여전히 발생합니다. 이때 바로 해결할 수 있는것이 바로 default_batch_fetch_size 인 것입니다.
default_batch_fetch_size
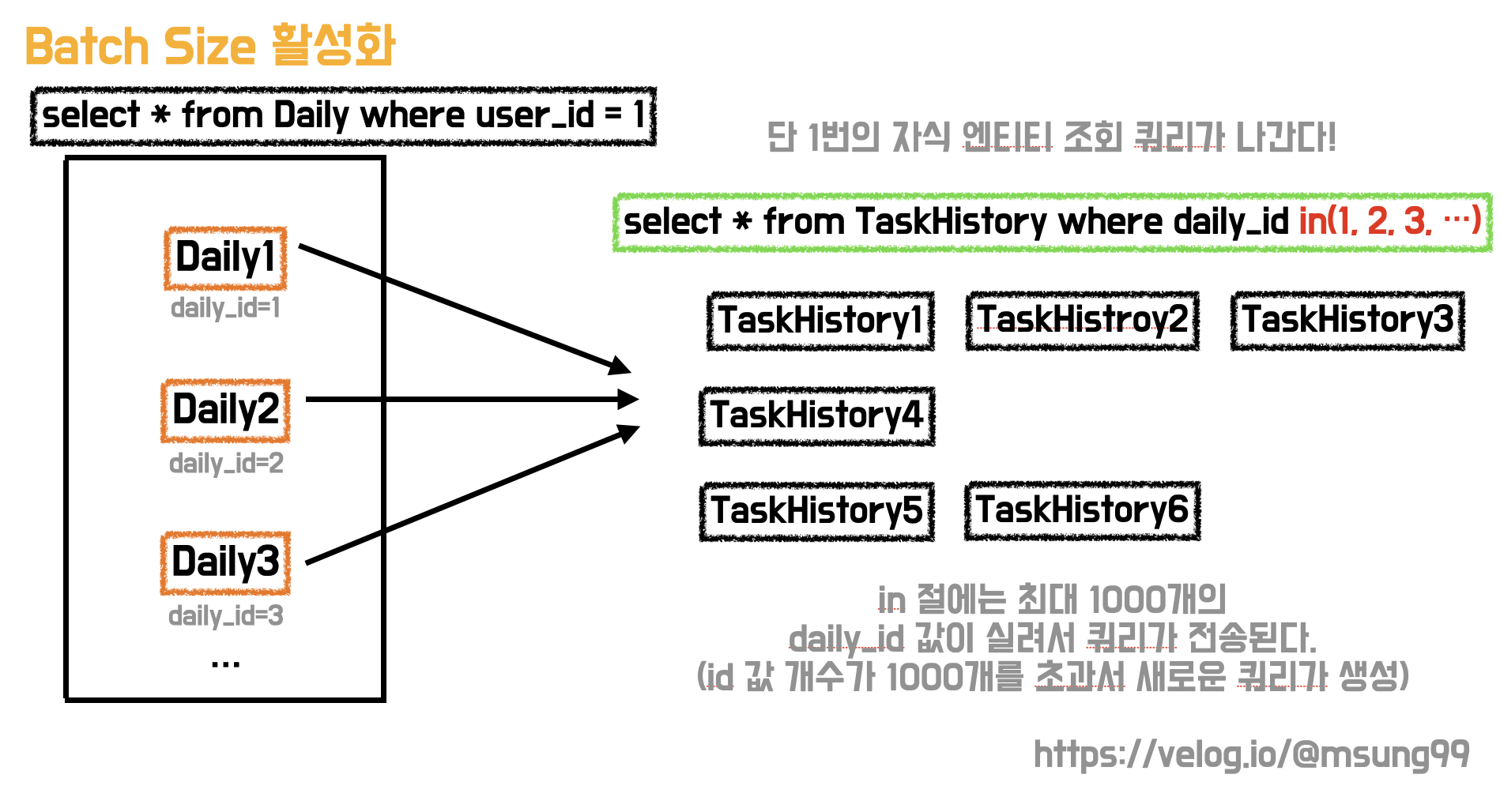
hibernate.default_batch_fetch_size 옵션은, 지정된 수만큼 in절 에 부모 key 를 사용하게 됩니다. 예를들어 옵션값으로 1000을 지정했다면, 한 쿼리에 최대 1000개 만큼의 부모 Key 값이 in 절에 실려서 넘어가서 최대 1000개의 자식 엔티티를 조회해오는 방식입니다.
즉, 조회 결과가 N개일 때 N개에 대해 각각 1번씩 조회 쿼리를 날리는 것이 아니라 위와 같이 batch size만큼씩 한꺼번에 날리는 것입니다.
예를들어 조회해야할 부모 엔티티인 daily 가 1500개 있다고 해봅시다. 이 옵션을 미적용하여 N+1 문제가 그대로 발생한다면, 1500개의 조회 쿼리문이 날라라기게 되는것입니다. 반면 옵션을 활성화하면, 단 2번만의 쿼리 (1000개, 500개로 daily_id 값이 분할되어 전송) 가 날라가므로, 성능이 대폭 향상됩니다. 즉, 쿼리가 전송수가 2/1500 으로 대폭 감소 및 향상된것입니다.
application.yml
적용 방법은 간단합니다. 아래처럼 jpa.properties.hibernate.default_batch_fetch_size 에서 글로벌 옵션을 적용해주면 됩니다. 자식 엔티티 중에 "ToMany" 관계에 있는 엔티티 하나만 fetch join 을 걸고, 나머지는 fetch join 없이 지연로딩(Lazy Loading) 을 수행하면 in 절 쿼리가 실행됩니다.
spring:
datasource:
url: jdbc:mysql://111.111.11.111:3306/mydb
driver-class-name: com.mysql.cj.jdbc.Driver
username: haon
password: password
jpa:
properties:
hibernate:
default_batch_fetch_size: 1000
format_sql: true
show_sql: true참고로 보통 옵션값을 1000 이상 주지는 않습니다. in절에 파라미터로 1000개 이상의 값을 실어서 쿼리를 보냈을떄, 너무 많은 in절 파라미터로 인해 문제가 발생할 수도 있기 때문입니다. 또 지금의 경우 Daily 가 1000개를 넘지 않으면 단일 쿼리 1개로 수행되기 떄문에, 옵션을 이 이상의 값으로 설정하지 않았습니다.
결론
Batch Size 를 언제 활성화할까?
이렇게까지 Batch Size 를 전역으로 설정한다면, fetch join 이 필요없을 수도 있다 생각이 들 수 있지만, 절대 그렇지 않습니다. default_batch_fetch_size 을 적용시 최소한의 성능이 보장되는 것이지, 최적화된 것이 아닙니다. 따라서 자식 엔티티가 개수가 많은 엔티티에 대해 fetch join 을 통해 성능을 최대한 보장하며, 나머지의 자식 엔티티에 대해선 옵션을 통해 최소한의 성능 개선을 보장받는다고 생각합시다.
- "ToMany" 자식 엔티티중에, 가장 데이터가 많은 자식 엔티티에 fetch join 을 수행하자.
- 나머지 자식 엔티티들은 default_batch_fetch_size 으로 최소한의 성능을 보장받자.
쿼리 성능개선
300개의 Daily 로 테스트를 진행했을때, N+1 문제를 미고려시 약 7초정도의 쿼리 수행시간이 걸렸습니다. 그런데 위와 같이 N+1 문제를 해결하도록 fetch join 과 batch size 를 적절히 조절하니, 약 2초정도로 쿼리 성능이 3.5배 나 개선된 것을 확인할 수 있었습니다 🙂
더 학습해볼 키워드
- Batch insert 쿼리 성능 개선방법
- EntityGraph, Query Builder
- 지연로딩(Lazy Loading) 과 즉시로딩(Eager Loading)
- JPA 프록시 객체의 특징
- Cascade