Jenkins, Nginx 배포 환경에서 발생하는 다운타임을 온전히 제거할 수 있을까?
학습배경
[CI/CD & Nginx] Worker Process 튜닝으로 다운타임을 0.015초로 줄이기 까지의 개선과정 에서 다루었듯이, Nginx 는 reload 시 아주 짧은 다운타임이 발생합니다. 그러나 Nginx 공식문서에서는 gracefully shutdown 을 지원함으로써, 제로타임(zero-downtime) 이 가능케한다고 주장하고 있습니다. 하지만, 실제로는 reload 시 다운타임이 발생하고 있으며, 이는 graceful 하지 못합니다.
이번에는 Nginx 의 문제점을 분석하고, 제가 어떻게 제로타임을 구현할 수 있을지에 대해 고민한 흔적에 대해 다루고자 합니다.
문제 발생상황 : 급한 불은 껐는데.. 🔥
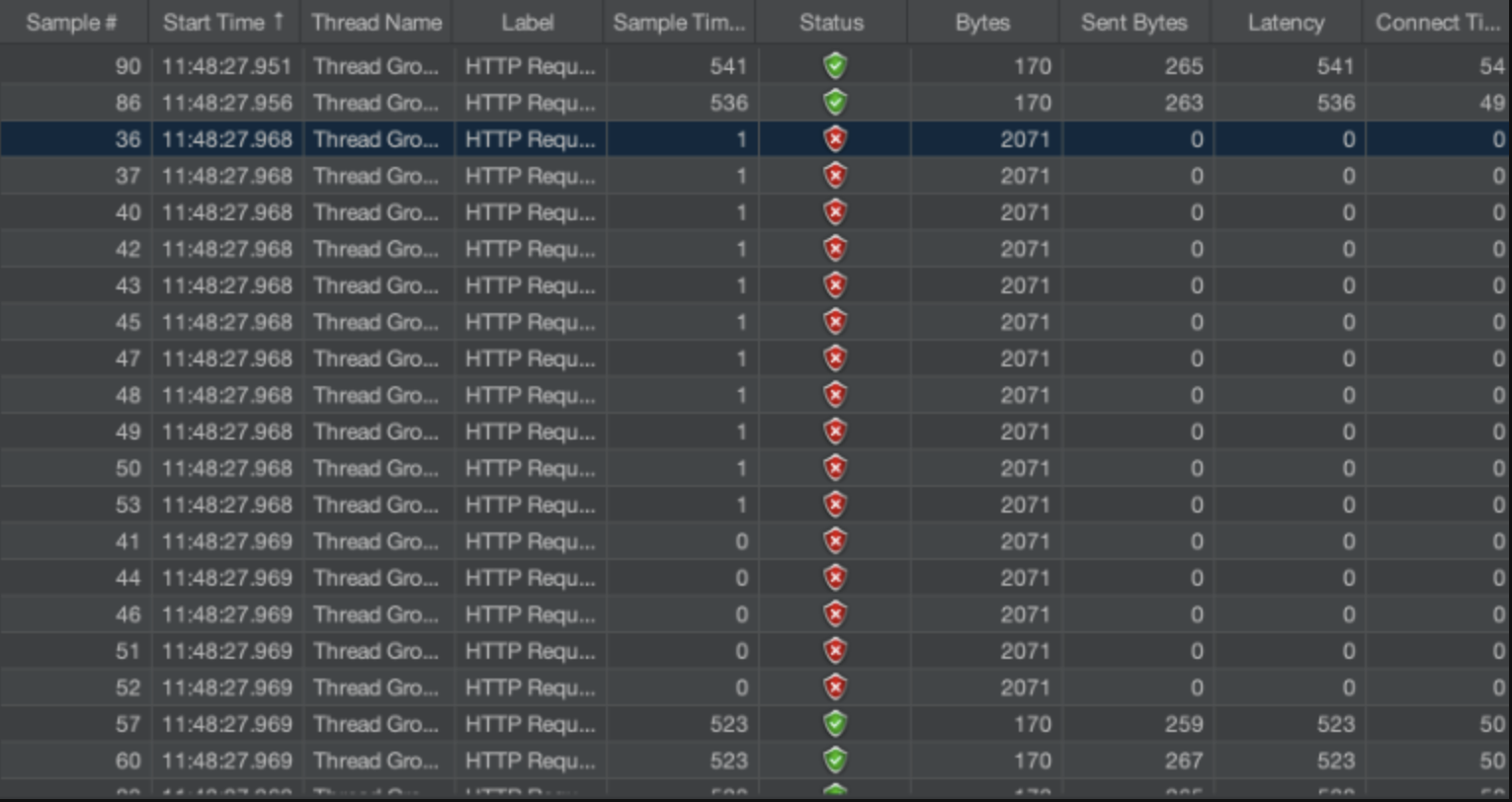
[CI/CD & Nginx] Worker Process 튜닝으로 다운타임을 0.015초로 줄이기 까지의 개선과정 에서도 계속 봤던 문제 상황이지만, Blue/Green 배포 아키텍처 에서 다운타임을 개선하는데 까지 많은 개선사항이 있었고, 결국 다운타임을 0.3초에서 시작해서 0.015초까지 감소시키는것은 성공했습니다. 그러나, 아직 다운타임이 발생한다는 그 근본적인 문제는 해결되지 않았으며, 이를 해결하고자 Nginx 의 공식문서에서 주장하는 Nginx Graceful Shutdown 의 특징에 대해 깊게 파해쳐 봤습니다.
Nginx 의 reload 의 모순
Nginx 공식문서 에서 말하기를, nginx -s reload 명령은 현재 실행중인 Nginx 프로세스에 reload 시그널을 보냅니다. Nginx 프로세는 nginx.conf 의 설정정보를 다시 읽어들여서 리버스프록시만 바꾸면서 Blue/Green 배포가 가능하다고 주장하고 있습니다. 하지만 앞서 계속 봤듯이, Nginx 는 reloading 시에 아주 짧은 다운타임이 발생하는 모순이 발생하고 있습니다. 이는 graceful 하지 못하다고 볼 수 있습니다.
클라이언트와 Nginx 서버간의 TCP 커넥션 처리 방식
Nginx 의 reload 시 내부 동작방식을 이해하고 왜 reload 시 다운타임이 발생하는지 이해하려면, 먼저 클라이언트와 nginx 서버 사이에서 어떻게 TCP 커넥션을 맺고 처리하는지를 이해해야합니다.
- 우선 클라이언트와 Nginx 서버의 IP 포트로 TCP 연결을 시도합니다.
- nginx 서버는 클라이언트의 요청을 수신하고, 해당 요청을 처리하기 위해 Worker Process 에서 사용 가능한 워커 프로세스를 할당합니다.
- 할당된 워커는 요청에 대한 처리작업을 수행하고, HTTP 응답을 클라이언트에 보냅니다.
- 클라이언트 또는 서버의 어느 한쪽에 연결을 종료하려는 경우, TCP 커넥션은 종료됩니다. 커넥션이 끊어지게 되면, 클라이언트와 서버는 종료된 커넥션으로 더 이상 데이터 교환을 할 수 없게 됩니다.
여기서 중점으로 봐야할 부분은 "종료된(끊어진) 커넥션으로 데이터 교환이 더 이상 불가능하다" 는점 입니다. 당연한 말이지만, 어떤 커넥션이 종료되었다면 해당 커넥션으로는 다시 요청이 불가능하므로 새로운 커넥션을 생성해서 재요청을 했을때만 서버에서 요청을 처리 가능합니다.
Connection : keep-value
또, HTTP Header 의 Connection 의 value 값으로 "keep-alive" 와 "close" 속성을 부여 가능합니다. 클라이언트로부터 온 패킷을 뜯어봤을때 keep-alive 속성이 부여된 패킷이라면, 해당 nginx 서버에 설정된 keep-alive 만큼 커넥션이 유지됩니다. 즉, keep-alive=60s;로 지정된 경우라면 클라이언트는 TCP 연결을 매번 재시도 할 필요없이 60초 동안 해당 커넥션으로 계속 요청을 시도하는 것입니다.
Nginx 의 reload 시 내부 동작방식
Nginx 의 실제 내부동작 방식을 알면, graceful 하지 못하다는 것을 알 수 있습니다. 결론부터 말하자면, HTTP Header 의 connection = keep-alive 으로 부여된경우, 문제가 발생하게됩니다.
- Nginx 가 reload 시그널을 받습니다.
- 워커 프로세스들은 현재 처리중인 http 요청까지만 응답하고, tcp 커넥션을 끊어버립니다.
- 만약 클라이언트의 http header 의 Connection 의 value 가 "keep-alive" 으로 설정되어있는 경우, 앞서 연결이 끊어진 tcp 커넥션으로 재요청을 시도해서 에러가 발생하게 됩니다.
keep-alive 로 지정된 경우
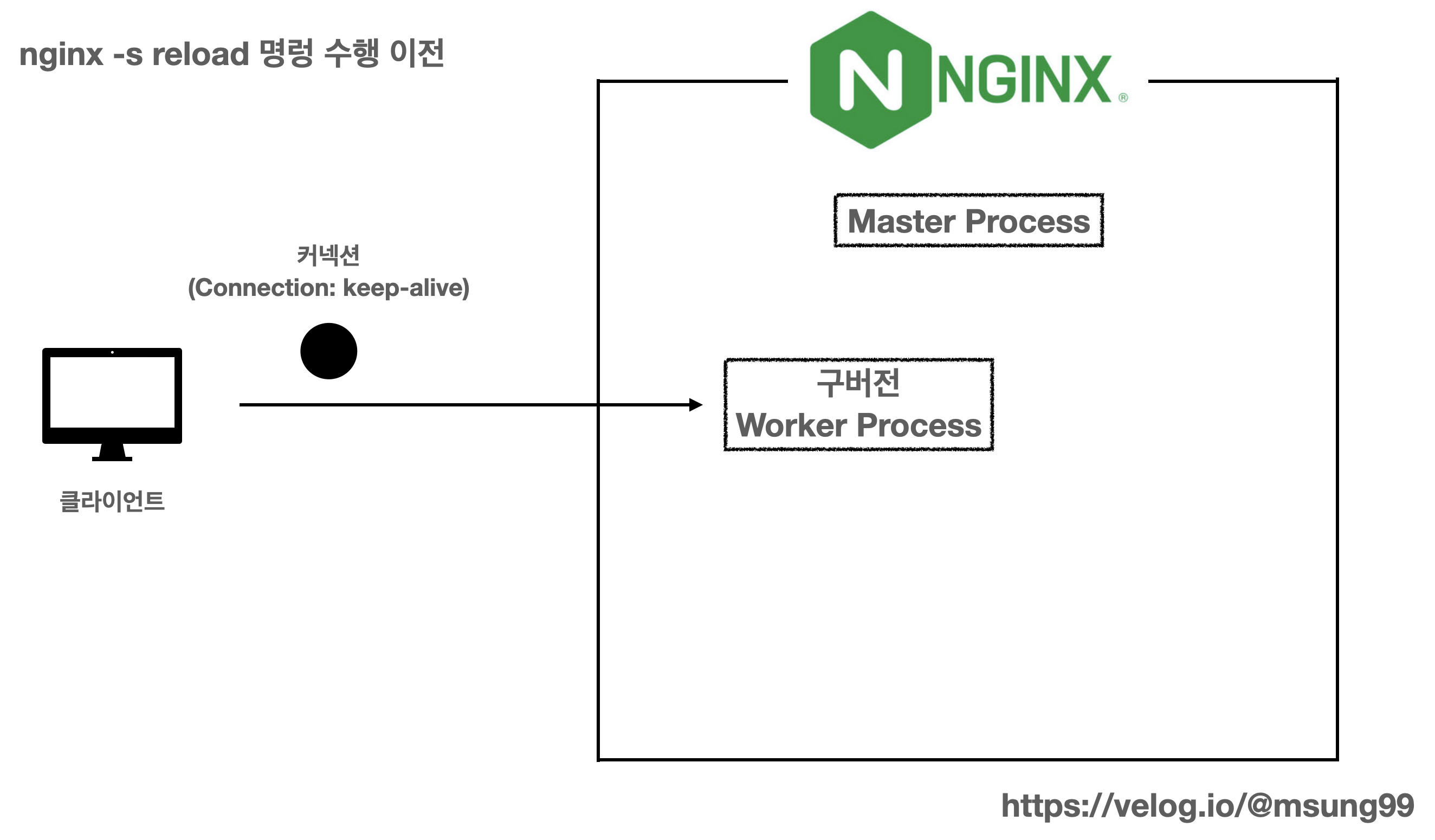
keep-alive 로 지정된 경우를 가정해봅시다. 기본적으로 HTTP/1.1 Connection 헤더 에서는 Connection: Keep-alive 헤더가 존재할 경우 tcp 커넥션을 재사용하도록 합니다. 위와 같이 클라이언트가 요청을 최초로 시도한다면 커넥션을 새롭게 생성합니다. 또 keep-alive 속성으로 인해, keep-alive = 60s; 인 경우를 가정한다면 60초 동안 해당 커넥션으로 요청을 재시도하게 됩니다.
다운타임 발생원인
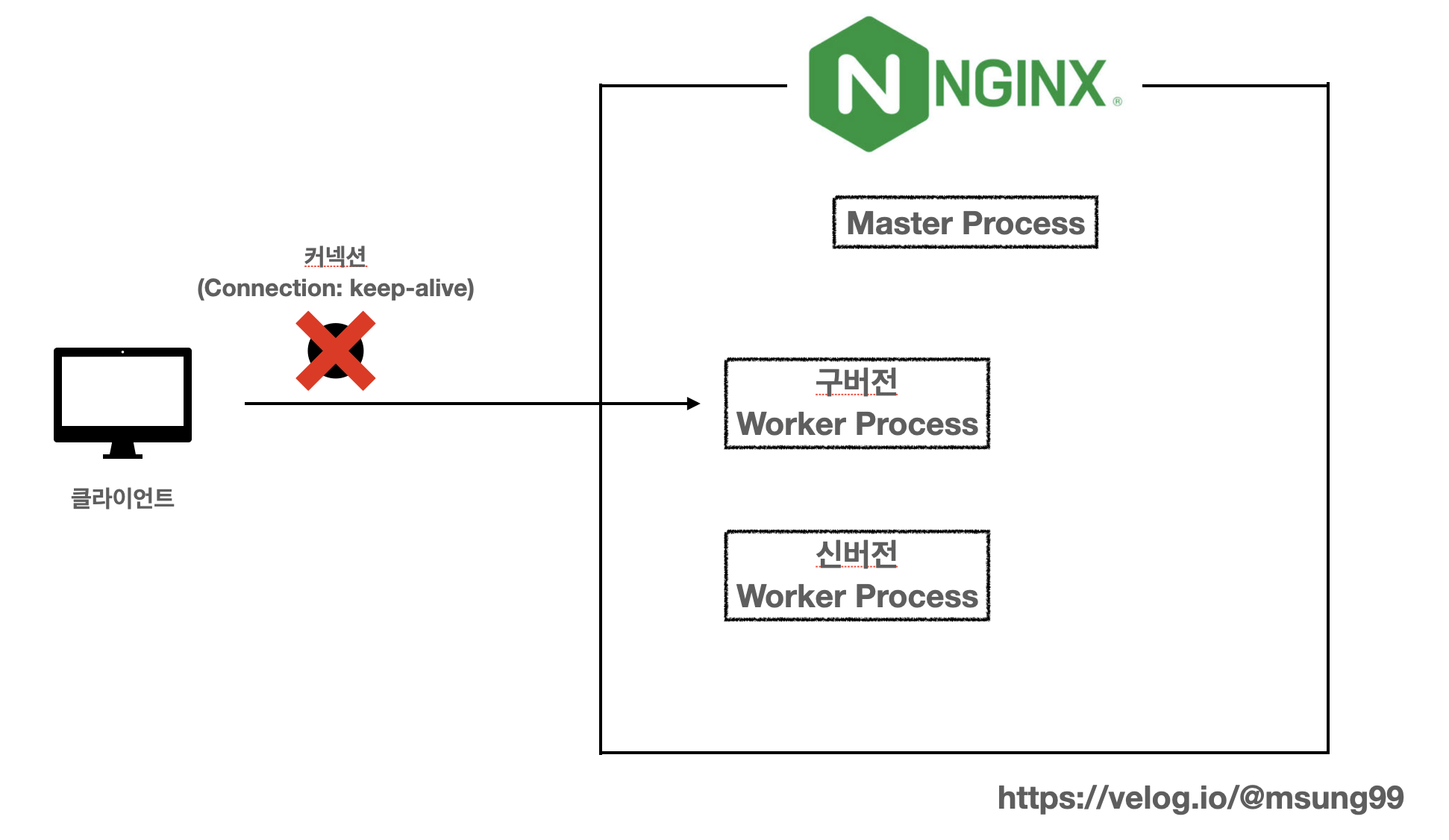
그런데 nginx -s reload 를 수행한 경우를 생각해봅시다. 그러면 새로운 worker process 가 생성되고 Nginx 에 의해 커넥션이 끊어지게(종료) 됩니다. 그러나, 기존에 커넥션을 생성한 클라이언트는 keep-alive 속성으로 인해 여전히 Nginx 에 의해 끊긴 TCP 커넥션을 통해 HTTP 요청을 재생성하고 해서 에러가 발생하게되고, 해당 요청은 실패하게 됩니다. 이때 바로 다운타임이 발생하게 되는 것이며, 클라이언트는 새로운 TCP 커넥션을 통해서 재요청을 시도해야합니다.
HTTP/1.1 Connecion 헤더
앞서 말씀드렸듯이, HTTP/1.1 스팩은 클라이언트와 서버는 응답에 Connection: Keep-alive 헤더가 존재할 경우 TCP 커넥션을 재사용해야 합니다. HTTP/1.1 은 Connection 헤더의 디폴트 값이 Keep-alive 이고, 이는 Connection 헤더를 따로 설정하지 않는 이상 항상 TCP 커넥션을 재사용해야 하는 것입니다.
Connection: close
그렇다면 단순하게 keep-alive 대신에 Connecion: close 헤더를 통해 매번 요청을 보낼때마다 TCP 연결을 맺고나서 작업내용을 처리후 재활용없이 바로 종료되게 만들 수 있습니다. 즉, 클라이언트는 매번 요청을 보낼떄 Connection: close 를 명시해서 매번 요청을 수행한 후에는 즉시 커넥션을 재활용하지 않고 종료시키게 할 수 있습니다.
하지만, 이 방식을 활용시 다음과 같은 문제점을 지닐 수 있습니다.
-
- 매 요청마다 TCP 커넥션을 맺어야하니, 오버해드가 발생할 수 있다.
-
- 클라이언트와 서버 사이에 Connection: close 이용을 하겠다는 규약을 맺어야합니다.
HTTP1.1 스팩상, Connection: close 이용을 강제하고 있지 않습니다. 특히 위 2번의 경우 Connection: close 를 이용하겠다는 규약을 특별히 맺어야한다는 번거로움이 발생하기도 하죠. 이 단순한 방법보다는, keep-alive 속성을 계속 유지하면서도 reload 가 되는 타이밍에 유의해서 커넥션을 처리해주는 더 효율적인 방법이 필요할겁니다.
close 라면 제로타임 구현이 가능하다
만약 HTTP/1.1 의 권장 스팩을 벗어나서 keep-alive 가 아니라 close 를 사용하게 된다면 제로 다운타임(zero-downtime) 구현이 가능해집니다.
add_header
만약 위 방법을 적용하고 싶다면, 설정방법은 아래와 같이 "close" 는 지정해주면 됩니다. Nginx 가 Connecion: close 헤더를 응답에 추가되도록 설정하는 것입니다. 이러면 매번 커넥션을 새롭게 keep-alive 으로 생성하고, 해당 패킷들을 항상 close 로 변환하여 응답해주게 됩니다.
server{
listen 80;
include /etc/nginx/conf.d/service-url.inc;
location / {
add_header Connection "close";
proxy_pass $service_url;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
}
}다운타임 테스트
실제로 요청을 보내봤을때, 단 한건의 요청도 실패하는 것없이 제로 다운타임이 구현되는 모습을 확인 가능했습니다. 테스트를 10번 넘게 돌렸을때, 모든 테스트가 성공적으로 다운타임 이슈를 해결할 수 있었습니다.
keep-alive 가 살아있는한 완벽한 제로타임을 만드는 것은 불가능하다
이상적인 방향 : reload 타이밍에만 TCP 커넥션을 재생성하기
커넥션 이슈를 해결하기 위해 며칠동안 많은 생각과 고민이 있었습니다. 아쉽게도 그 과정에서 떠올려봤던 아래와 같은 방법이 있었는데, 이는 구현이 불가능에 가깝다고 판단되어서 최선의 해결책으로만 남게 되었습니다.
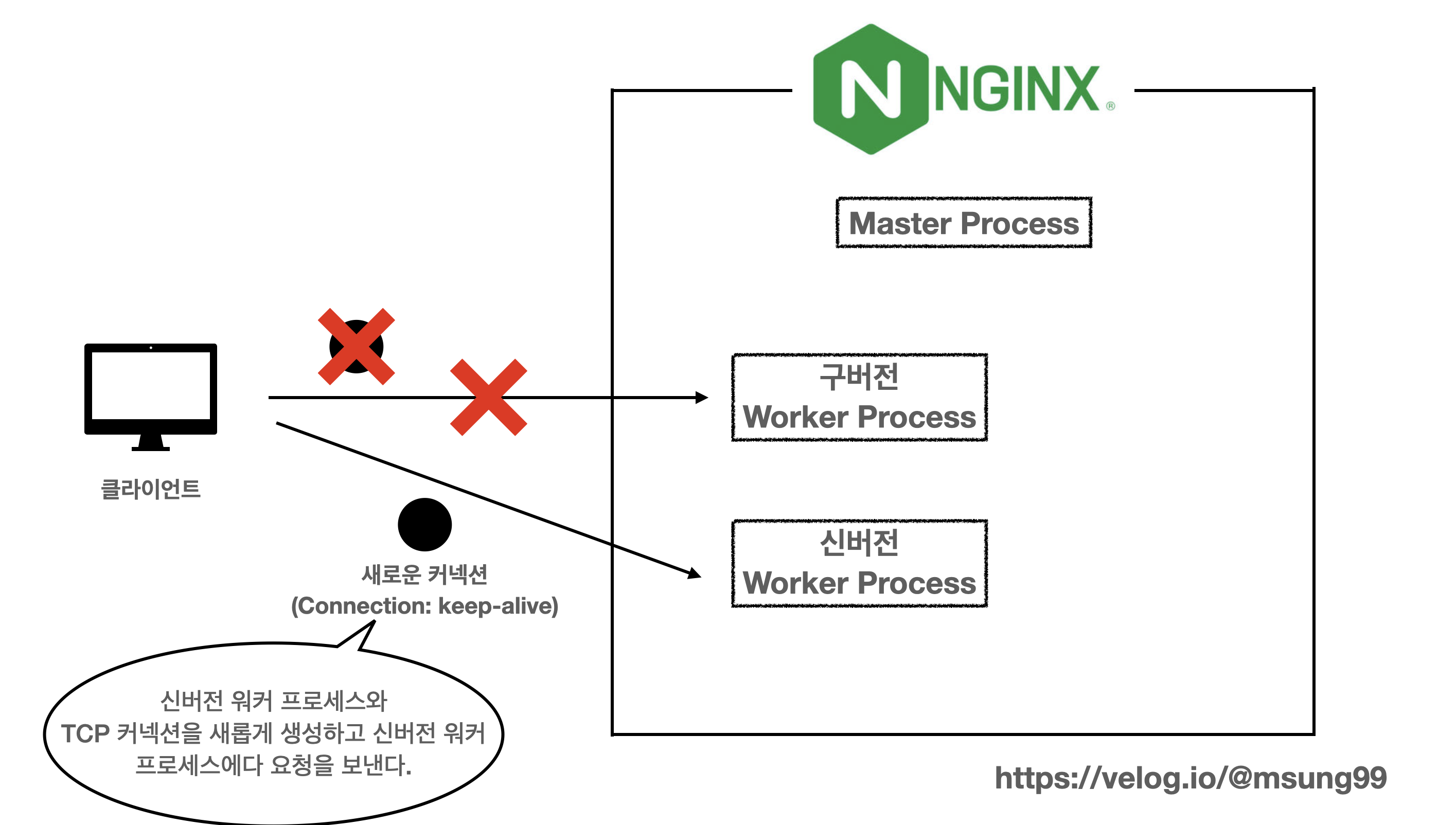
이 방식은 구현이 매우 복잡하기 떄문에 제공되지 않는 기능이라고 합니다.
해결책으로 생각했던 최선의 방법은 위와같이 바로 평소에 들어온 keep-alive 를 계속 유지하다가, reload 시점에만 커넥션을 끊어버리고 클라이언트가 새로운 커넥션을 생성하도록 유도하는 방식입니다. 즉, 워커 프로세스는 reload 시점에만 Connection: close 헤더를 응답으로 전송해서 클라이언트가 새로운 커넥션을 설정하도록 유도하는 것입니다. 이렇게하면 기존에 끊어진 TCP 커넥션을 재활용하려는 시도를 방지하면서, 다운타임을 방지할 수 있게 될겁니다.
하지만, 아쉽게도 이 기능을 구현할 방법은 현재 존재하지 않습니다. 결국 Nginx 로 완벽한 제로 다운타임(zero-downtime) 을 만드는것은 사실상 불가능에 가깝다고 보는게 맞는 것 같습니다.
이벤트 훅(Evevt Hook)
이에 대한 해결책으론, 이벤트 훅(Hook) 을 사용하는 방법이 있긴합니다. 이벤트 훅은 Nginx의 특정 이벤트가 발생했을 때 실행되는 사용자 정의 함수입니다. 이를 활용하여 nginx -s reload 명령 실행 시점에서 원하는 동작을 수행할 수 있긴 합니다. 예를 들어, ngx_lua 모듈을 사용하여 Lua 스크립트를 작성하고, 해당 스크립트를 이벤트 훅으로 등록하여 실행하는 방법이 있습니다. 하지만, 이를 구현하는 것은 정말 어렵기때문에 거의 사용되지 않습니다.
제로타임에 더 가까워지기 위한 성능개선
하지만 제로타임에 더 가까워 지기위해, 더 효율적인 설정을 충분히 고민해보았습니다. 이는 불안정한 처리를 더 안정적으로 처리하기 위함이기도 합니다. 그 방법은 아래와 같습니다.
1) worker_shutdown_timeout
worker_shutdown_timeout 1s;worker_shutdown_timeout 값은 graceful shutdown이 이루어지는 동안에도 각 워커 프로세스가 추가 요청을 받을 수 있는 시간을 지정합니다.
이를 사용해야 하는 이유는 우선 keep-alive 때문입니다. 클라이언트와의 Keep-Alive 연결을 통해 여러 요청을 처리하는 경우, 워커 프로세스가 종료되기 전에 아직 완료되지 않은 요청이 남을 수 있습니다. 이는 클라이언트가 동일한 연결을 재사용하여 추가 요청을 보낼 수 있기 때문이죠.
2) keepalive_timeout
다음으로 keep-alive 도 타임아웃 지정이 가능합니다. 아래처럼 작성시 클라이언트와 Nginx 간의 keep-alive 연결이 3초간 유지되는 것이죠. 이 시간은 애플리케이션 특성을 고려하여 적절히 처리해주면 됩니다.
keepalive_timeout 3s;위 방법 설정값들은 제 부하테스트 API 특성상 자원 낭비가 거의 없고, 응답속도가 빠른 편이기 때문에 매우 짧게 설정해줬습니다. 이 설정값은 애플리케이션 및 API 의 특성에 따라서 적절히 설정해주시면 됩니다.
기타 성능 개선요소
추가적으로 [CI/CD & Nginx] Worker Process 튜닝으로 다운타임을 0.015초로 줄이기 까지의 개선과정 에서 다룬 내용이지만, http2 프로토콜을 적용하거나, 애플리케이션의 특성에 따라 Worker Process 의 개수와 커넥션 허용수를 적절히 조절함으로써 처리속도 및 성능 개선을 진행할 수도 있습니다.
성능 테스트
성능이 크게 증가하진 않았지만, 평균 약 0.009 초의 다운타임을 보이는 것으로 보아 위 기능들을 도입한 결과가 없지않아 성능 개선에 있어 미약하게나마 도움은 된듯합니다.
결론
결론을 내리자면, 완벽한 zero-downtime 을 만들어내는 것은 keep-alive 를 활용하지 않겠다면 "가능" 하고, 그게 아니라면 아쉽게도 "불가능" 에 매우 가깝다라고 보는게 맞습니다. 몰론 저도 모르는 모니터링 도구가 있어서 제가 생각했던 위 아이디어가 실제로 구현된다면 제로타임이 구현될 수는 있다고봅니다. 하지만 Nginx 에서 제공되는 기능 자체만으로는 불가능하다고 볼 수 있습니다.
TCP 커넥션의 연결을 맺고 끊는 타이밍을 위처럼 조절한다면, 즉 keep-alive 특성을 활용하지 않겠다면 응답으로 connection = close 를 무조건 리턴하게 하는 위 방식도 활용할 수는 있겠습니다. 이 방법을 활용시에는 앞서 언급드렸듯이, 제로 다운타임이 구현은 가능해집니다.
또한, 무엇보다 다운타임의 주원인은 Connection: keep-alive 일때 TCP 커넥션 처리 문제로 인해 발생한다는 것을 증명해냈습니다 !