Jenkins, Nginx 기반 배포 환경에서 발생하는 다운타임을 개선해보자!
학습배경
SpringBoot Graceful Shutdown & SIGTERM 시그널 : 구버전 프로세스를 안전하게 종료시켜보자! 에서 봤듯이, Graceful Shutdown 과 SIGTERM 시그널을 통해 다운타임을 0.3초 에서 0.2초 감소시키도록 개선이 이루어졌으며, SIGKILL 을 통해 구버전 프로세스가 강제로 kill 되는 상황을 방지했습니다.
그러나 "무중단 배포" 라는 컨셉에 있어서는, 아직도 0.2초란 다운타임을 줄이고 싶다는 욕심은 여전합니다. 0.2초도 몰론 매우 짧은시간이지만, 애플리케이션이 신버전으로 배포될때 "무중단" 되는 상태는 엄밀히 따졌을때 아닐겁니다.
이번에는 제가 Nginx 을 성능을 개선 진행해서 "다운타임을 0.2초에서 0.015초 까지 크게 감소"시킨 과정에 대해서 소개해볼까합니다. 또 그 과정에서, Nginx 의 내부 메커니즘을 자세히 뜯어볼겁니다.
0.2초의 다운타임 발생 환경

[CI/CD] Jenkins 와 Nginx 를 활용한 Blue/Green 자동화 배포 아키텍처를 수동으로 구축하기 (feat. SpringBoot) 에서 다룬 내용은 다운타임이 무려 0.3초가 발생하는 문제가 발생했습니다.
이를 방지하기 위해, 스프링부트 구버전 프로세스를 안전하게 종료시킬 수 있는 graceful shutdown 과 리눅스의 SIGETERM 시그널에 대해 SpringBoot Graceful Shutdown & SIGTERM 시그널 : 구버전 프로세스를 안전하게 종료시켜보자! 에서 다루었습니다.
Nginx 가 다운타임 발생의 원인인 이유
맨처음에는 스프링부트 애플리케이션에서 graceful shutdown 이 혹시 잘 적용이 안된건가 하는 의심에, 아래와 같이 sleep 을 5초를 걸어서 nginx 가 리버스프록시 방향이 변경되기 전까지의 충분한 여유를 주고, 구버전 프로세스를 kill 하는 방식을 시도했습니다.
ssh root@${nginx_ip} "echo 'set \\\$service_url http://${deployment_target_ip}:8080;' > /etc/nginx/conf.d/service-url.inc && service nginx reload"
echo "Switch the reverse proxy direction of nginx to ${deployment_target_ip} 🔄"
sleep 5
if [ "${deployment_target_ip}" == "${blue_ip}" ]
then
ssh root@${green_ip} "fuser -s -k 8080/tcp"
else
ssh root@${blue_ip} "fuser -s -k 8080/tcp"
fi
echo " ✅ 구버전 프로세스를 종료하고, 신버전 프로세스로 교체합니다."그러나, 여전히 다운타임은 0.2초라는 문제가 발생했고 더 이상 다운타임이 개선될 상황이 보이지 않았습니다. 이로보아 Nginx 가 리버스프록시 방향을 전환시, 즉 nginx -s reload 를 수행할떄가 가장 큰 원인임을 알 수 있었으며, Nginx 를 타킷으로 성능을 개선하고자 많은 노력이 있었습니다. 결론부터 말하자면, 다운타임을 0.2초에서 약 0.015초로 대폭 감소시킬 수 있었습니다.
결국, 이 다운타임을 대폭 감소시키고자 했던 Nginx 에 대한 성능을 개선시키는 방향을 생각하게 되었습니다. 그리고 그 과정을 이 포스팅에 녹여내고자합니다.
Nginx 의 Worker Process
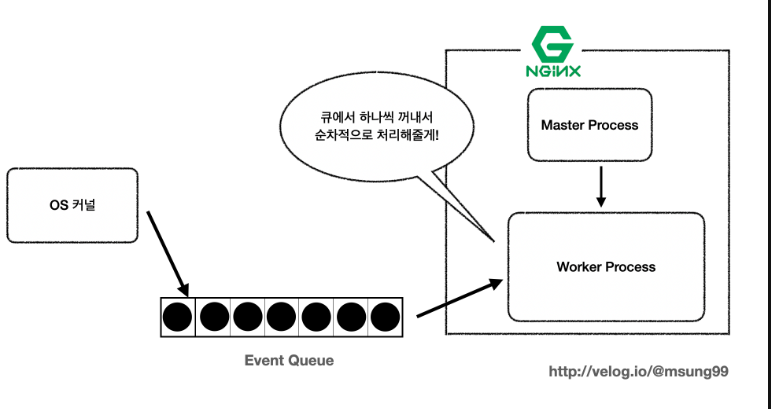
[Nginx] 1995년 역사부터 뜯어보는 Nginx : 등장배경부터 내부 메커니즘까지 에서도 정말 자세히 소개드린 내용이지만, Nginx 는 마스터 프로세스(Master Process) 에 의해 여러개의 워커 프로세스(Worker Process) 를 생산해냅니다. 또한 각 워커 프로세스는 지정된 Listen Socket 를 받고, 그 소켓에 새로운 클라이언트로부터 받은 요청에 대한 커넥션을 생성하고, 해당 요청을 처리하는 방식입니다.
또, 연결된 각 TCP 커넥션은 HTTP 프로토콜에 설정된 keep-alive 시간만큼 끊기지않고 유지됩니다. 이러한 커넥션을 워커 프로세스는 동시간대에 최대 1024개까지 연결 가능합니다. 또 이벤트 큐(Event Queue) 에 담긴 이벤트들은 비동기적(asychoronous) 으로 처리됩니다.
Nginx Gracefully Shutdown
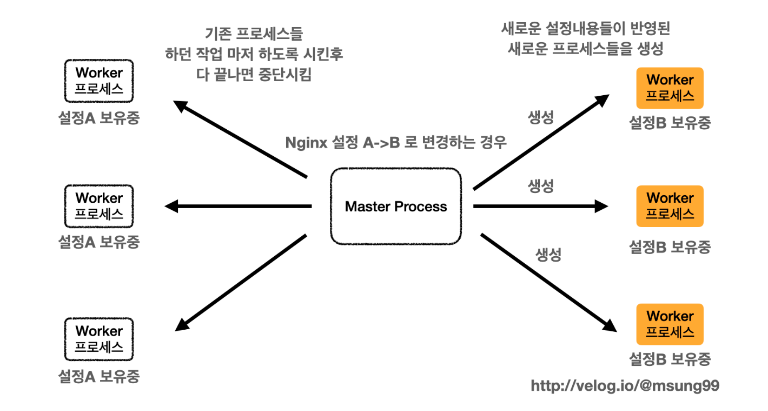
또 Nginx 는 gracefully shutdown 을 지원해줌으로써, nginx -s reload 와 같이 리로딩을 매끄럽게 지원해주도록 합니다. 리로딩을 시작한 타이밍은 다음과 같은 절차로 요청을 처리해줍니다.
-
- 기존 Worker Process 로 트래픽이 유입되고 있는 상황입니다.
-
- 리로딩이 시작되면, Master Process 는 새로운 설정파일 정보에 기반하여 새로운 Worker Process 가 생성합니다.
-
- 새로운 Worker Process 가 요청을 받을 준비가 되었다면, 커넥션과 요청을 받기 시작하게 되고, 이때부터 기존의 Worker Process 는 gracefully 하게 shutdown 됩니다.
-
- 즉, 구버전 Worker Process 는 바로 프로세스가 kill 되는 것이 아니라, Graceful Shutdown 을 수행하므로 기존 요청을 모두 처리한 후 안전하게 종료됩니다.
이러한 메커니즘에 따라서 Nginx 는 구버전 워커 프로세스가 안전하게 요청을 처리한 후 종료되는 것입니다.
Worker Process 분산처리
지금부터 성능을 개선해봅시다. 우선 Worker Process 의 개선입니다. nginx.conf 는 별도의 설정이 없다면 아래와 같이 auto 로 지정이 되어있을텐데, 이 auto 값에는 해당 서버의 CPU Core 개수만큼이 지정됩니다. 이를 명시적으로 지정해주기 위해, 1, 4 등의 숫자로 채워줍시다. 저는 CPU 4Core 를 사용하기 때문에 4로 채워줬습니다. 이렇게 Worker Process 가 여럿 생성되면, 라운드 로빈(Round Robin) 방식에 기반하여 여러 워커 프로세스가 골구로 커넥션 및 요청을 분산받고 빠른 처리를 할 수 있게 됩니다. 결국 테스크를 여러 워커 프로세스가 분할받는 분산처리 를 구현하게 된 것입니다.
user www-data;
worker_processes auto; // 4로 변경
pid /run/nginx.pid;
include /etc/nginx/modules-enabled/*.conf;
events {
worker_connections 768;
# multi_accept on;
}
http {
// ...
}CPU Core 개수만큼 생성하는게 맞을까?
그런데 과연 CPU Core 개수만큼 워커 프로세스가 생성되는게 좋을까요?
CPU 4코어 환경에서 4개의 worker process가 CPU 4코어를 공유하여 처리하면, 각 worker process는 CPU 자원을 공평하게 나눠서 사용할 수 있게 됩니다. 이 경우, 각 worker process는 실제 CPU 코어 하나를 독점적으로 사용하는 것이 아니라, 여러 worker process가 동시에 CPU 코어를 사용하게 됩니다.
여러 worker process가 CPU 자원을 공유하면, 각 worker process는 상대적으로 적은 처리 능력을 가지게 됩니다. 이는 동시에 실행되는 worker process들이 CPU 자원을 경쟁적으로 사용하며, 서로의 처리 속도에 영향을 미치기 때문입니다. CPU 자원이 공유되기 때문에 각 worker process는 처리량이 일정하게 나눠지지 않고, 상황에 따라 다른 worker process보다 더 많은 작업을 처리해야 할 수도 있습니다.
따라서 CPU 4코어 환경에서 4개의 worker process를 사용하는 경우, 각 worker process는 상대적으로 적은 처리 능력을 가지게 되며, 이로 인해 성능 저하나 다운타임이 발생할 수 있습니다. 이를 해결하기 위해서는 적절한 worker_processes 값과 worker_connections 값 조정, CPU 코어의 활용 등을 고려하여 최적의 설정을 찾아야 합니다.
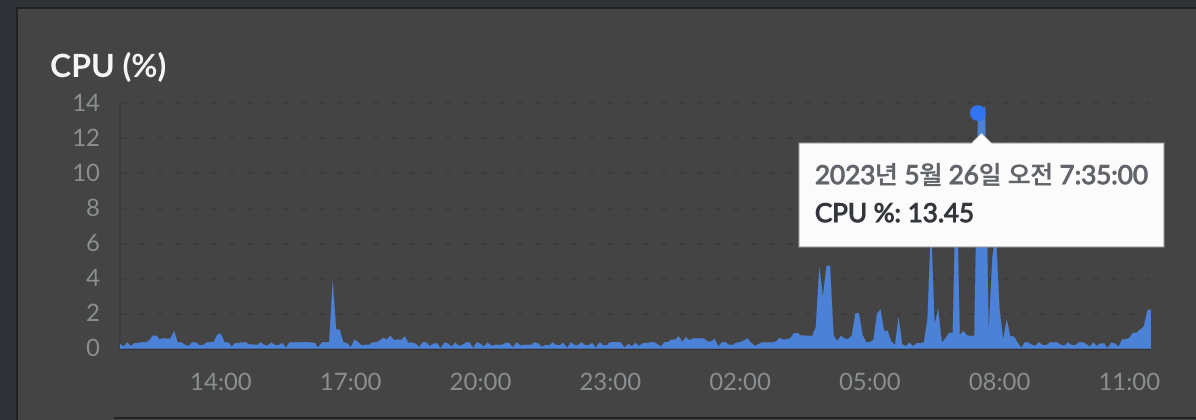
하지만 저는 CPU Utilization 을 모니터링 해보니, 많이봤자 약 13% 의 사용률을 보였기 때문에, 자원 경쟁률이 미흡하다는 것을 인지하고 워커 프로세스를 4개 할당해주었습니다. 혹시 하는 마음에 worker process 를 3개로 지정해보고 테스트를 진행해봤으나, 역시나 CPU utilization 수치가 낮기 때문에 다운타임이 오히려 증가하는 것을 보고, 다시 4개로 설정해주었습니다.
Worker Connections 개선
다음으로 각 워커 프로세스의 최대 커넥션 허용개수도 지정해줄 수 있습니다. 앞서 말씀드렸듯이, 워커 프로세스는 동시간대에 TCP 커넥션을 최대 1024개를 유지 가능합니다. 또 Nginx 의 Graceful Shutdown 특성에 따라서, 새로운 Worker Process 가 생성되고 난 뒤에 아직 처리할게 남아있는 요청들은 gracefully 하게 처리된 후 구버전 워커 프로세스가 종료되는 방식입니다.
워커 프로세스의 커넥션 허용수는 별도의 설정이 없다면 기본적으로 768 로 설정이 되어있습니다. 커넥션을 최대한 맺도록 1024로 수정해줍시다.
user www-data;
worker_processes 4;
pid /run/nginx.pid;
include /etc/nginx/modules-enabled/*.conf;
events {
worker_connections 1024;
# multi_accept on;
}
http {
// ...
}성능 테스트 결과 : 평균 0.015초의 다운타임
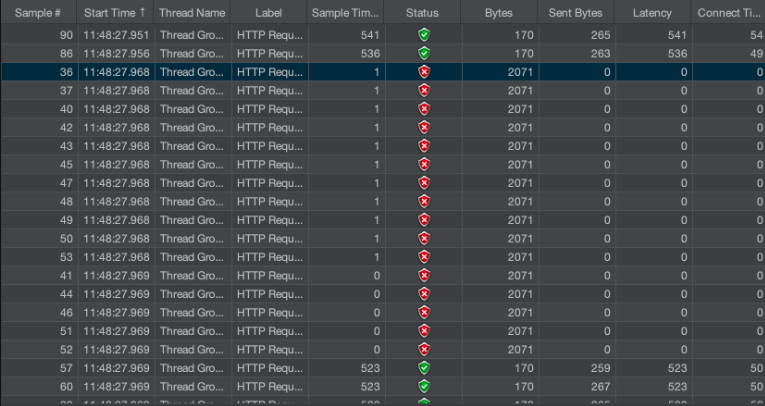
jmeter 를 통해 성능 테스트를 진행한 결과, 튜닝후의 다운타임은 가장 짧았을때가 0.001초라는 결과가 나왔으며, 평균적으로 약 0.015초의 결과가 나온만큼 다운타임이 대폭 감소한 모습을 확인할 수 있습니다. 또한, 이것도 다운타임이 발생한 것이라고 볼 수 있는데, 이 다운타임은 nginx -s reload 로 새로운 설정정보를 리로딩시에 발생하게 되는 것입니다.
과연 Nginx 는 Graceful Shutdown 을 원활히 지원하는게 맞을까?
Nginx 공식문서 에서도 설명하기를, Nginx 는 graceful shutdown 을 통해서 다운타임이 절대 발생하지 않는, 즉 제로 다운타임(zero-downtime) 을 지원한다고 주장하고 있습니다. 하지만, Nginx 가 gracefully 한 shutdown 을 지원해준다는 말은 완전히 맞는말은 아닙니다. 솔직히 저는 graceful 하다는 느낌도 들지 않습니다.
Nginx 는 다운타임이 발생하는데?
만약 공식 문서말처럼 Nginx 가 graceful 해서 제로타임을 지원해준다면, 위와 같이 nginx -s reload 를 수행시 아주 짧은 0.015초의 다운타임도 발생하지 않았어야합니다. 이는 맞는말이라고 보기엔 무리가 있습니다.
사실 Nginx 에서 왜 다운타임이 발생하는지 최근에 알아냈습니다. 이에 관해서 조만간 다운타임이 왜 발생하고, 어떻게해야 이렇게 정말 짧은 다운타임 마저도 제거할 수 있는지 해결책도 자세하게 따로 다루어보고자 합니다. 사실 이번 주제는 이 해결첵을 알아내는데까지 고민했던 흔적과, 그로인해 Nginx 의 내부 메커니즘을 깊게 학습한 경험을 기록하고 공유하고자 작성한 것이라고 보는게 맞을것같습니다.
추가 개선사항
[Nginx] 1995년 역사부터 뜯어보는 Nginx : 등장배경부터 내부 메커니즘까지 에서 언급했듯이, Nginx 는 1.7.11 이상부터 Thread Pool 을 지원해주며, 현재 안정화된 오픈 버전인 1.1 버전 이상부터 http2 를 지원해준다. 그러나 Thread Pool 은 OS 호환이 잘 안되며, 아직 안정성이 잘 검토되지 않아서 불안정 한것으로 판단되어서 제외했습니다.
http2 도 추가적으로 성능을 개선할 수 있는 고려사항입니다. 만일 적용이 가능하다면 아래와 같이 80번 listen socket 에 http2 를 명시해주면 됩니다. 이 또한 고려사항에 있으나, 충분히 다운타임이 개선된 것으로 판단되어 이 내용은 튜닝 리스트에서 제외했습니다.
listen 80 http2;