현 포스팅은 MySQL 8.0 InnoDB 스토리지 엔진을 기반으로 작성했습니다.
차이는 리프노드(leaf node) 에 있다
InnoDB 스토리지 엔진은 B+ Tree 구조의 인덱스를 취하고 있습니다. 결론부터 말하면, 대부분 통상적으로 말하는 "인덱스" 라는 개념은 비 클러스터링 인덱스(Non-Clustering Index) 를 말하는듯 합니다.
먼저 요약해보자면, 클러스터형 인덱스란 레코드를 실제 레코드를 별도로 분리하지 않고, 인덱스가 레코드와 함께 군집화되어 저장되는 방식입니다. 반면 리프 노드에서 각 리프 페이지의 요소들이 포인터로 별도로 분리된 데이터 파일의 레코드를 조회해야 하는 방식이라면, 논 클러스터링 인덱스(Non-Clustering Index 라고 합니다.
클러스터링 인덱스의 기본 생성
MySQL 8.0 의 InnoDB 스토리지 엔진은 각 테이블당 기본적으로 하나 이상의 인덱스를 생성하는 것을 강제로 하고있으며, 이 때문에 기본적으로 클러스터링 인덱스를 생성합니다. 이에 대한 내용은 아래에서 자세히 설명하겠습니다.
또한 개발자가 직접 인덱스를 새롭게 추가하는 것은 논 클러스터링 인덱스 를 새롭게 추가하는 것임을 미리 알고 넘어갑시다. 즉, 기본적으로 존재하는 클러스터링 인덱스에 이어서 새로운 논 클러스터링 인덱스를 추가하는 행위라고 보면됩니다.
인덱스가 없었더라면?

조금 더 원초적인 질문으로 들어가봅시다. 만약에 인덱스가 없는 경우에 "민서" 라는 데이터를 스캔하는 조회문을 실행할 경우 어떻게 동작할까요?
위와같이 3개의 페이지가 있다고 해봅시다. 이는 클러스터나 논 클러스터 인덱스를 적용하지 않은 상태입니다. 그렇다면 디스크의 맨 첫번째 페이지부터 시작해서 순차적으로 모든 레코드를 스캔해오는 데이터 풀 스캔(Full Table Scan) 이 발생하기 떄문에 O(n) 의 시간이 소요될 것입니다. 이 때문에 인덱스가 등장한 것이죠. 특정 컬럼을 인덱스로 관리함으로써 O(logbN) 이라는 더 효율적인 조회문을 실행한다는 것입니다. 그래서 인덱싱의 종류로 등장한 것이 클러스터링 인덱스 와 논 클러스터링 인덱스입니다.
클러스터링 인덱스 (Clustering Index)
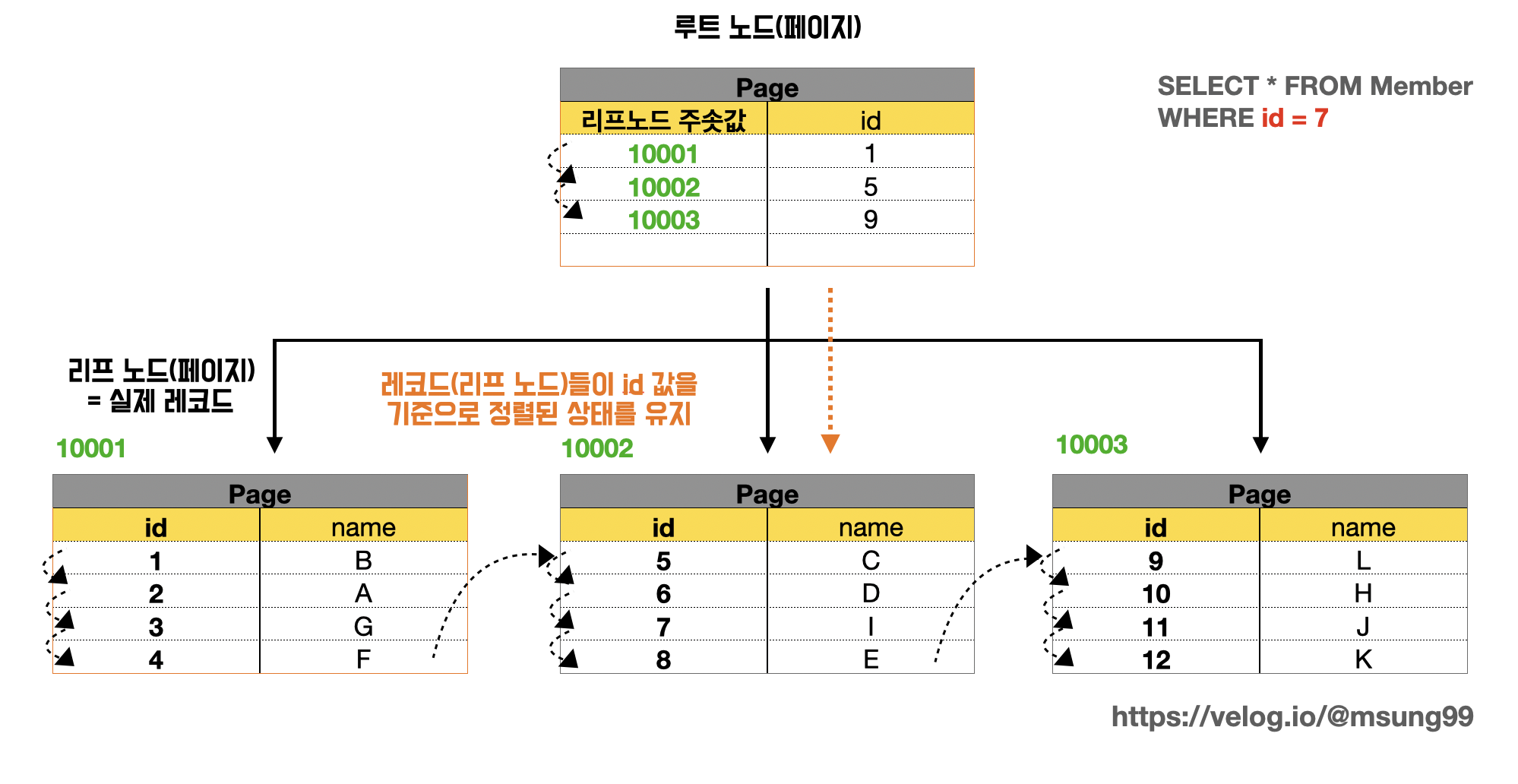
"클러스터링" 이란 군집화의 의미와도 같습니다. 클러스터링 인덱스란 B+ Tree 구조에서 리프 노드가 실제 데이터와 별도로 분리되지 않고 함께 군집화되어 인덱싱되는 방식입니다. 데이터와 함께 전체 테이블이 함께 정렬됩니다.
테이블에 중복되는 값이 있어서는 안되며, 이 때문에 기본키(primary key) 와 UNIQUE+NOT NULL 제약조건이 걸린 특정 컬럼에 대해서만 인덱스를 생성가능합니다. 만약 기본키와 UNIQUE 제약조건이 걸린 컬럼에 대해서 별도로 명시적으로 인덱스를 생성하지 않았더라도 자동으로 생성됩니다. 만약 테이블에 위 조건을 만족하는 컬럼이 없다면, InnoDB 엔진은 내부적으로 GEN_CLUST_INDEX 라는 컬럼을 생성해서 클러스터형 인덱스를 생성합니다. GEN_CLUST_INDEX 는 행이 생성된 순서대로 값이 부여됩니다.
각 루트 및 브랜치 노드는 인덱스 컬럼 값(ex. PK값) 을 보유하며, 리프 노드(실제 레코드) 를 가리키고 있는 형태가됩니다.
InnoDB 엔진의 디폴트 클러스터링 인덱스 선택방식
위 예시를 보면 id 컬럼은 대학교 학생들의 각 학번이라고 해봅시다. 이 컬럼을 PK 로 설정해 클러스터링 인덱스를 생성한 모습이라고 이해하면 될것입니다. 걸론적으로, InnoDB 엔진에서는 리프 페이지에서 기본적으로 key 값으로 PK 를 가지고 있고, 데이터를 직접 들고있는 모습입니다. 즉 리프 노드는 실제 데이터 레코드 그 자체로 동일한 객체입니다. 또, InnoDB 엔진에서는 직접 들고있는 이 레코드들을 PK 값 을 기준으로 순차정렬하고, 군집화하는 형태를 지닙니다.
InnoDB 는 아래와 같은 기준에따라 우선순위를 클러스터링 인덱스를 선정하니, 참고하기릴 바랍니다.
- primary key 가 있으면 1순위로 primary key 를 클러스터링 인덱스로 선택
-
- pk가 없다면, UNIQUE + NOT NULL 제약조건이 걸맄 컬럼을 선택
-
- 둘다 없다면, "GEN_CLUST_INDEX" 이라는 자동으로 유니크한 값을 가지도록 증가되는 컬럼을 내부적으로 추가한 후, 클러스터링 인덱스로 선택 (쿼리에서 명시적으로 사용 불가능)
비클러스터링 인덱스 (Non-Clustering Index)
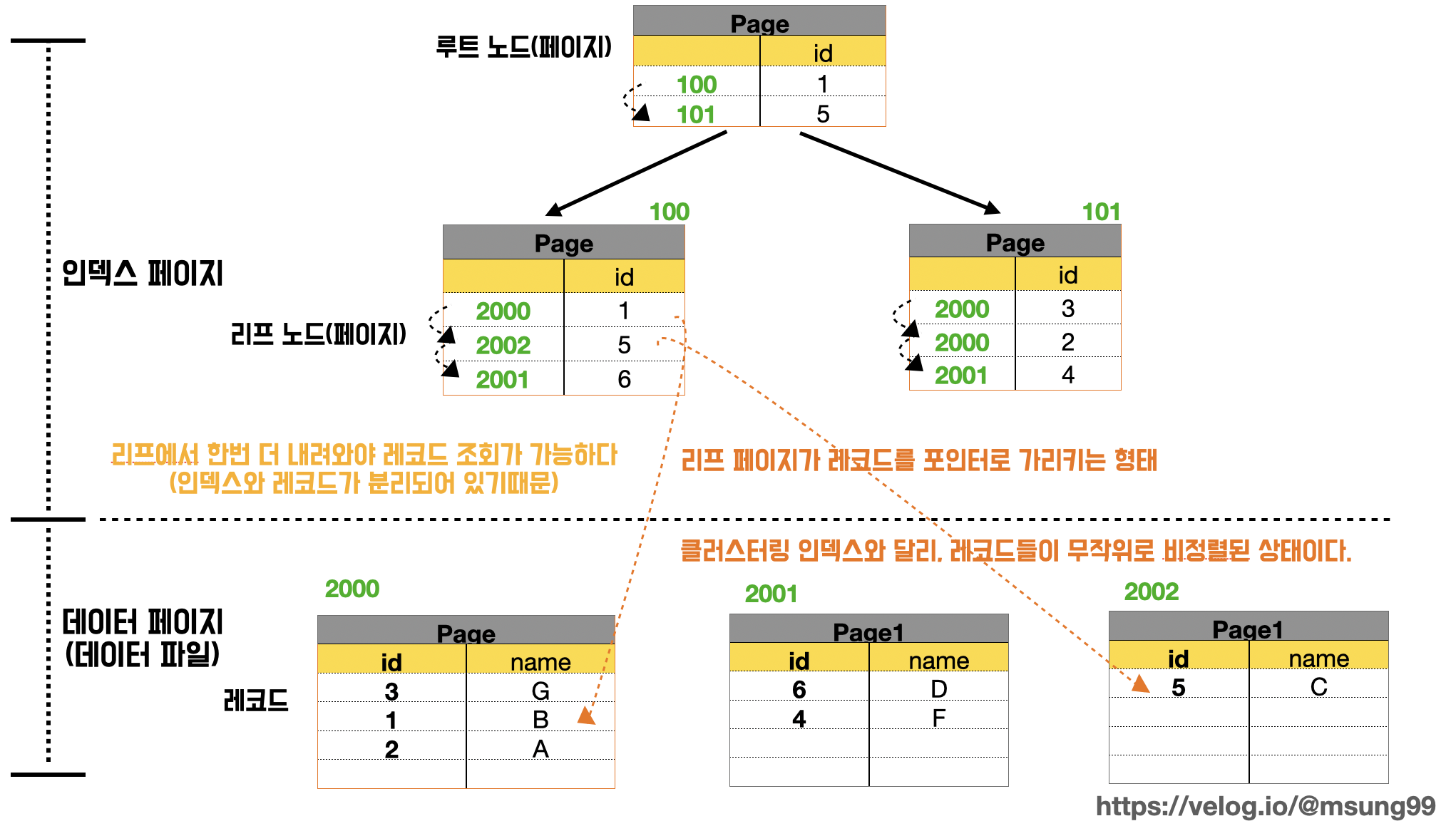
비 클러스터링 인덱스와 클러스터링 인덱스의 차이는 리프노드가 실제 레코드를 군집화해서 저장하는가, 아니면 따로 저장하는가에 있습니다. 비 클러스터링 인덱스는 실제 레코드를 따로 관리(저장)하는데, 인덱스와 분리된 실제 레코드를 포인터로 가리키는 방식입니다. 즉, 리프 페이지에는 인덱스 컬럼값외에도 실제 레코드의 주솟값을 저장하고 있습니다.
한 컬럼에 UNIQUE 제약조건을 걸면 자동 생성 가능하며, 또는 개발자가 직접 UNIQUE INDEX 쿼리로 중복을 허용하지 않으면서 인덱스를 직접 생성 가능합니다. 이때 UNIQUE 옵션을 빼면 중복이 허용된다는점에 유의합시다.
인덱스 페이지는 정렬되어 있지만, 실제 데이터 페이지는 정렬되지 않으므로 클러스터형 인덱스에 비해 삽입, 수정, 삭제 작업이 비교적 빠릅니다. 데이터 페이지에는 정렬 순서 상관없이 빈 곳에 데이터를 삽입하면 되기 때문이죠.
// 논 클러스터링 인덱스 생성 예시
ALTER TABLE Member
ADD CONSTRAINT uniq_name UNIQUE(name);
CREATE UNIQUE INDEX unq_idx_name
ON Member (name);
CREATE INDEX idx_name; // => 중복 허용
ON Member (name);멀티 인덱스 : 클러스터링 인덱스와 비클러스터링 인덱스의 혼합된 형태
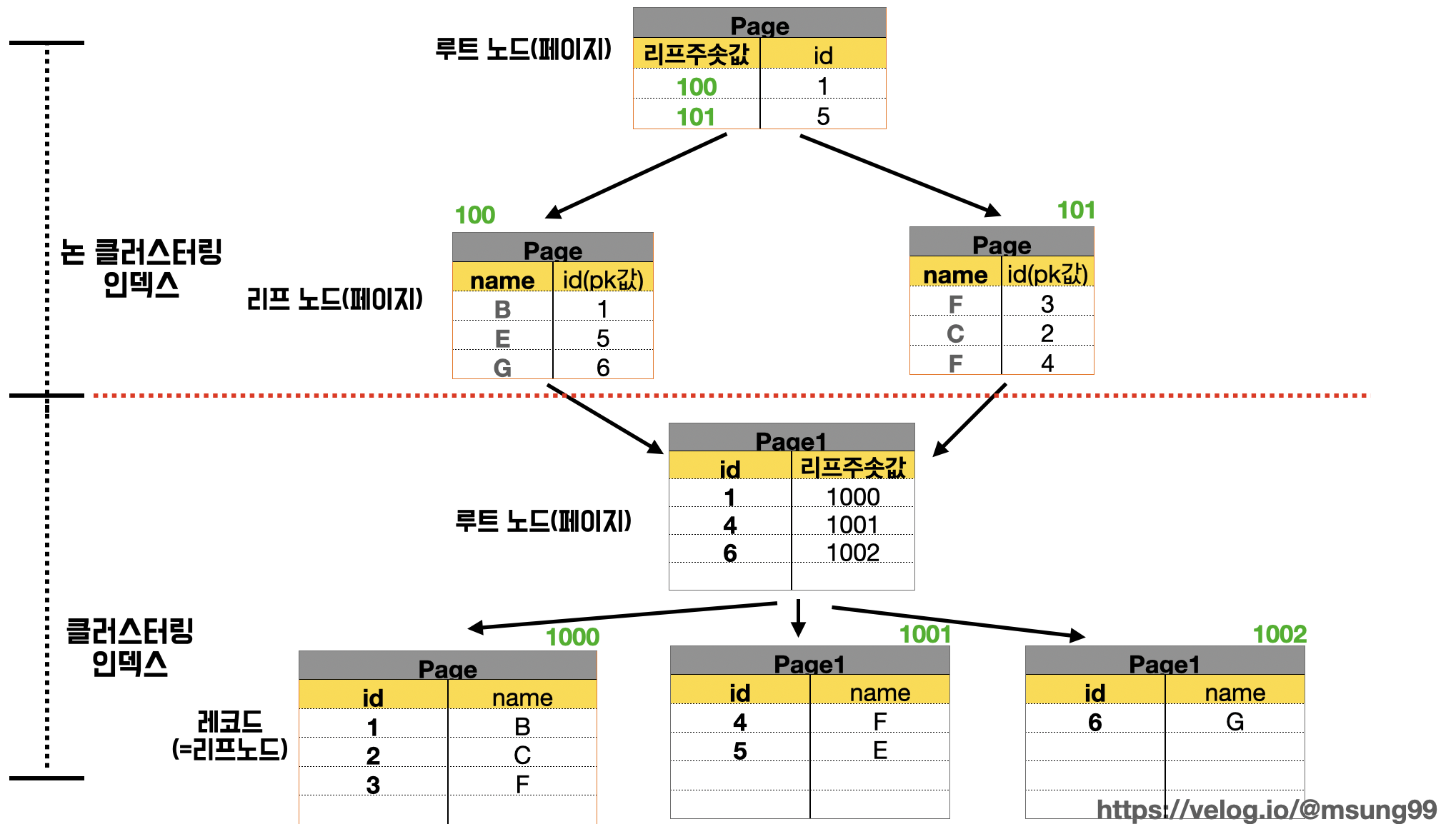
그런데 현실적으로는 기본적으로 생성되는 클러스터링 인덱스 외에도 논 클러스터링 인덱스 가 생성되는 경우가 대다수입니다. 즉, 하나에 테이블에 클러스터형 인덱스와 논 클러스터링 인덱스가 혼합되어 있는 경우가 많죠. 클러스터링 인덱스는 대부분 PK 일텐데 PK 는 기본적으로 대부분의 테이블에 반드시 존재하며, 추가적으로 조회가 자주 발생하는 컬럼에 대해 개발자가 새로운 논 클러스터링 인덱스를 추가하기 때문입니다.
이런 경우에는 논 클러스터링 인덱스를 먼저 거치고, 이어 클러스터형 인덱스를 거쳐 데이터를 찾습니다. 이때, 비클러스터링 인덱스의 리프노드는 실제 레코드에 대한 주솟값 대신 클러스터링 인덱스에 대한 컬럼 값(PK 값)을 갖습니다.
또 유심히보면, 클러스터링 인덱스는 B+ Tree 트리의 구조를 이루기 때문에, InnoDB 엔진에서 조회문을 실행시 primary key 값을 활용해서 B+ Tree 구조에서 실제 레코드에 접근하는 흐름으로 처리된다고 이해하시면 됩니다.
정리)
- InnoDB 스토리지 엔진은 논 클러스터링 인덱스에서 클러스터링 인덱스로 넘어가는 형태이다.
- 논 클러스터링 인덱스의 리프노드는 PK 값을 저장하고있다. 이 PK 값에 해당하는 클러스터링 페이지를 특정 셀(실제 레코드)을 찾아내서, 그 실제 레코드로부터 원하는 컬럼 값을 조회하는 방식이다.
바로 위에서 정리한 내용중에 논 클러스터링 인데스의 리프노드는 "PK 값" 을 가지고 조회한다고 했는데, 정확히는 클러스터링 인덱스의 컬럼값이라고 보는게 맞긴합니다. 앞서 설명하길, 클러스터링 인덱스는 PK 값 외에도 unique 제약조건을 가진 컬럼이 될수도 있다고 했기 때문에, 반드시 PK 값이라고도 정의내릴 순 없습니다.
다중 컬럼 인덱스 (Multi Column Index)
추가적으로, 학습을 하면서 햇갈렸던점을 하나 정리해보고자 합니다.
우선 다중 컬럼 인덱스(Multi Column Index) 란 개발자가 인덱스를 생성시 2개 이상의 여러 컬럼으로 생성해낸 인덱스입니다.
예를들어 Member 라는 테이블이 있다고해봅시다. 이 테이블의 PK 는 member_id 이며, 그외의 컬럼으로는 name , std_id , grade 가 있다고해봅시다. 어떤 경우가 클러스터링/논 클러스터링 인덱스만 존재하며, 또는 어떤 경우가 혼합된 멀티 인덱스가 존재하는 경우일까요? 또 어떤 경우가 다중 컬럼 인덱스일까요? 아래와 같이 개발자가 인덱스를 생성하는 5가지 경우를 생각해봅시다.
-
- (name, std_id)
-
- (name, grade)
-
- (member_id, name, std_id)
-
- (name, member_id)
-
- (name)
우선 member_id 에 대한 클러스터링 인덱스가 자동으로 생성되었을 겁니다. 또 5가지 경우 모두 논 클러스터링 인덱스가 생성되는 경우로 생각할 수 있습니다. 앞서 언급했듯이, 직접 인덱스를 생성하는 경우는 모두 논 클러스터링 인덱스임을 잊지맙시다.
위 케이스는 모두 "멀티 인덱스"가 됩니다. 즉, 기존에 자동으로 생성된 PK 기반의 클러스터링 인덱스에 위와 같은 논 클러스터링 인덱스를 개발자가 직접 추가해주었으니, 멀티 인덱스 형태가 되는 것입니다.
또 5번을 제외하면 "다중 컬럼 인덱스(Multi Column Index)" 에 모두 해당됩니다. 5번의 경우는 2개 이상의 컬럼을 활용하지 않았기 떄문에 해당되지 않습니다.
비효율적인 인덱스
또 위 인덱스에서 어떤 인덱스가 비효율적으로 생성되었는지 생각해봤을 때, PK 를 포함하는 3번과 4번이 해당됩니다. PK 는 이미 클러스터링 인덱스를 통해 생성되었으므로 인덱스로 조회 가능한데도, 굳이 논 클러스터링 인덱스 (다중 컬림 인덱스) 에서 또 PK 값을 포함해서 새로운 인덱스를 중복해서 생성할 필요는 없습니다. 커버링 인덱스 와 같은 혜택을 누리는 것도, 이렇게 중복 생성을 하지 않고도 누릴 수 있습니다.
더 학습해볼 키워드
- 옵티마이저
- 파티셔닝과 샤딩