카니널리티(Cardinality)
카니덜리티(Cardinality) 란 사전적 의미로 "그룹 내 요소의 개수" 를 의미합니다. 인덱스를 적용시, 카디널리티가 높은, 즉 중복 수치가 낮은컬럼 에 대해 적용시켜주면 됩니다. 예를들어 PK 컬럼이 카디널리티가 높은 경우에 해당될텐데, 유니크한 특성으로인해 중복되는 값이 존재하지 않으므로 수치가 높을것입니다.
예를들어 아래와 같은 Member 테이블이 있다고 해봅시다. 각 컬럼의 카디널리티(= 요소의 개수) 를 계산해보면, "성별" 컬럼의 경우, 값의 중복이 굉장히 많고 남자와 여자밖에 존재하지 않기 때문에 카디널리티가 굉장히 낮은것을 볼 수 있습니다.
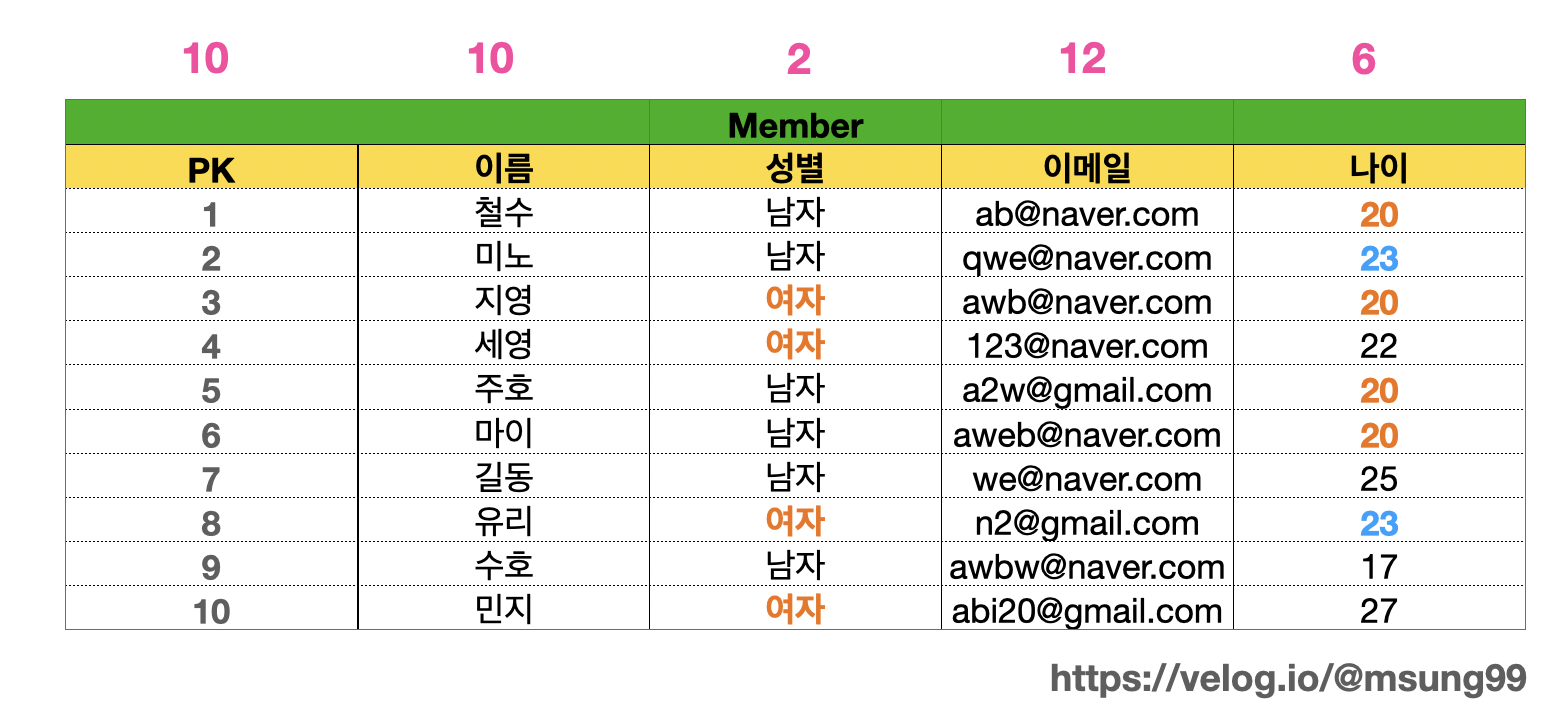
따라서 우리는 카디널리티가 낮은, 즉 중복도가 높은 컬럼에 대해 인덱스를 적용해야합니다. 여기서는 id 나 이메일, 주민번호, 이름등이 인덱스 적용 대상이 될 것이다.
인덱스를 적용시키기 좋은 추가 case
카티널리티 외에도 추가적으로 어떤 경우에 인덱스를 적용시키면 좋을까요?
1. Cardinality
앞서 말했듯이, 중복도가 낮은 컬럼에 대해 인덱스를 적용시키면 좋을겁니다. 만야 중복도가 높은 컬럼에 대해 인덱스를 적용시키고 추후 조건절에서 활용한다면, 인덱스 탐색 범위가 굉장히 넓어지게 되고 최악의 경우는 차리리 테이블 풀 스캔(Table Full Scan) 을 시도하는 경우가 더 나을 수도 있습니다.
예를들어 인덱스 레인지 스캔을 수행하는 경우, [MySQL 8.0] 데이터베이스의 쿼리 성능 튜닝을 위한 랜덤 I/O 와 순차 I/O 에서도 언급했듯이 이 기준은 읽어야할 레코드가 20~25% 를 넘으면 테이블의 데이터를 직접 읽는것이 더 효율적인 처리 방식이라고 했었습니다.
2. 조건절에 자주 사용되는 컬럼인 경우
WHERE , JOIN, ORDER BY 와 같이 조건절에 자주 사용되는 컬럼인 경우, 인덱스를 적용시키는게 좋습니다. [MySQL 8.0] MySQL 에서 B+ Tree 인덱스 스캔을 통한 성능 최적화 방식 (Index Scan) 에서도 언급했듯이, 만약 조건절에 인덱스 컬럼이 없다면 인덱스는 활용되지 못하고 방치되는 상황이기 때문에 쓸모없는 추가 공간만 낭비하는 상황이 되는 것입니다.
3. insert, update, delete 가 자주 발생 안하는 컬럼인 경우
계속 언급했던 것이지만, B+ Tree 구조는 삽입, 수정, 삭제 성능을 버린 대신에 조회(select) 의 성능에 최적화된 구조입니다. 때문에 이러한 연산이 자주 발생하지 않는 컬럼에 대해 인덱스를 만드는것이 좋습니다.
4. 규모가 작지 않은 테이블
그리고 규모가 작은 테이블에는 인덱스를 적용하더라도 효과가 미미하기 떄문에, 규모가 작지 않은 테이블에 인덱스를 적용하는 것이 효과가 좋습니다.
인덱스 유의사항
추가적으로 인덱스를 사용시, 잘 호출되지 않는 컬럼에 대한 인덱스는 과감히 제거하는 것이 좋습니다. 조건절에 사용되더라도 자주 사용해야 가치가 있기 때문이죠. 방치되는 인덱스라면 불필요한 인덱스로써 성능 저하의 요인만 될 것입니다.
반대로 자주 사용되는 컬럼이더라도 삽입, 수정, 삭제가 자주 일어나는지 고려하는 것이 좋습니다. 일반적인 트랜잭션 온라인 환경에서는 읽기와 쓰기의 비율이 2:8 ~ 1:9 수준입니다.
클러스터링 인덱스 (Clustering Index)
장점
지난 [MySQL 8.0] 클러스터형 인덱스(Clustered Index) 와 비클러스터형 인덱스(Non-Clustered Index), 기본키를 통한 군집화 에서도 언급했듯이, MySQL 8.0 에서는 클러스터링 인덱스로 PK 를 보통 취하고있습니다. 이러한 클러스터링 인덱스를 통해,
PK 값으로 조회 쿼리문을 수행시 처리 속도가 매우빠르다 는 특징을 지니고있습니다. 또 테이블의 모든 세컨터리 인덱스가 PK 를 가지고있기 때문에, 인덱스만으로 처리될 수 있는 경우가 굉장히 많습니다. 이를 커버링 인덱스 라고 했습니다.
AUTO-INCREMENT 보다 업무적인 컬럼으로 PK 를 생성하자
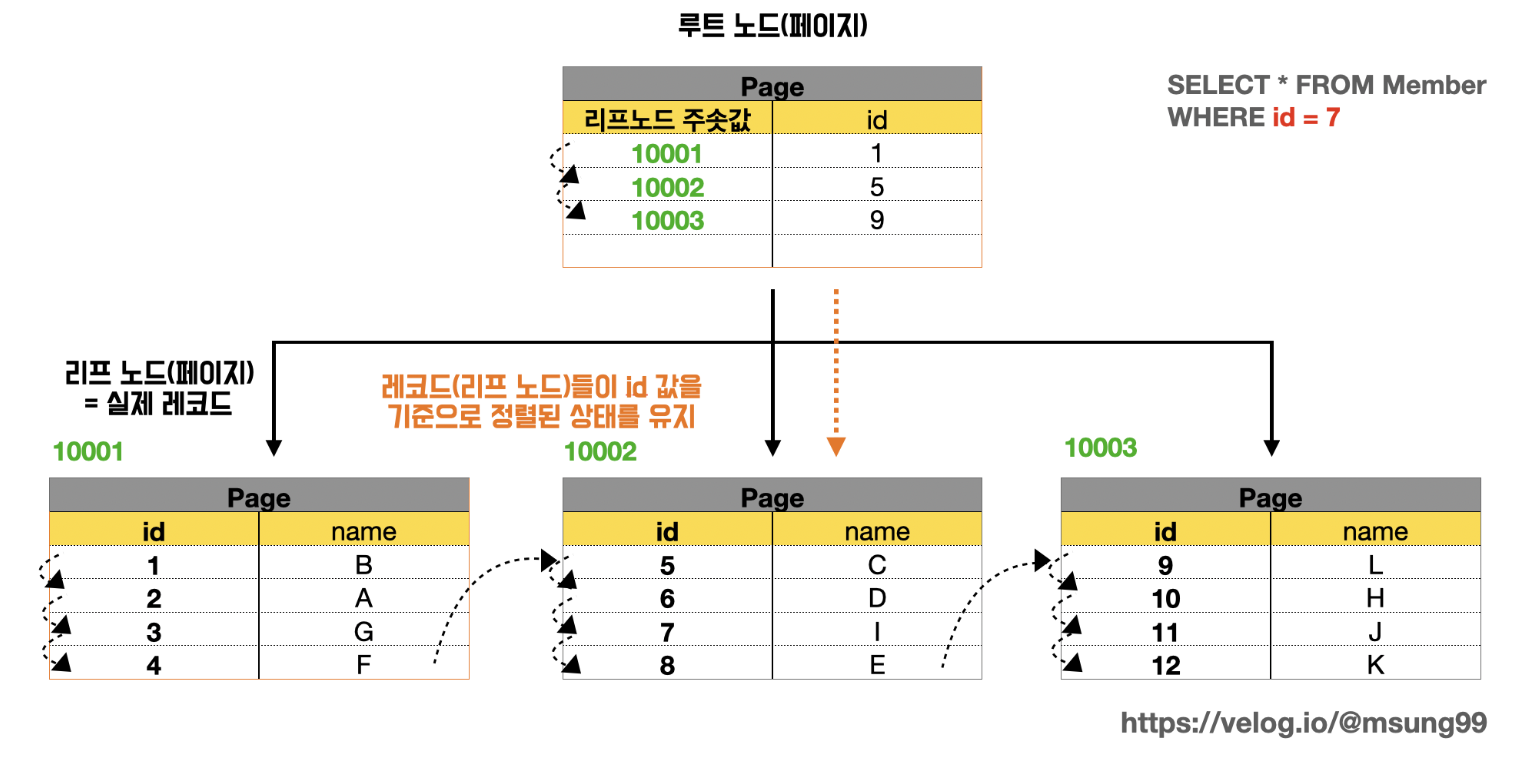
InnoDB 의 PK 는 대부분의 경우 클러스터링 키로 사용되며, 이 값에의해 레코드의 위치가 결정됩니다. 즉, PK 로 조회 쿼리문을 실행하는 경우 클러스터링 되지 않은 테이블에 비해 매우 빠르게 처리될 수가 있죠. 따라서 AUTO INCREMENT 전략도 좋겠지만, 매우 중요한 key 인 만큼 업무적으로 해당 레코드를 대표할 수 있게 만들어준다면 더 좋을것입니다.
PK 값이 변경되는 일은 거의 없겠지만, 만약 변동이 생긴다면 레코드의 구조를 PK 값을 기준으로 재정렬 해야하는 비용이 발생하므로, 이를 최소화하는 것이 좋을겁니다.
PK 는 반드시 명시하자
가끔 PK 가 없는 테이블을 볼 수 있는데, 가능하면 AUTO INCREMENT 컬럼을 이용해서라도 PK 는 생성하는게 좋습니다. 이전에 다루었듯이, 만약 PK 를 정의하지 않으면 InnoDB 스토리지 엔진에 내부적으로 GEN_CLUST_INDEX 라는 값을 자동으로 추가하며 이는 사용자에게 보이지도 않고 쿼리문에서 활용하지도 못합니다.
결국 PK 를 정의하지 않은 경우와 AUTO_INCREMENT 컬럼을 생성하고 PK 를 설정한 경우가 모두 똑같은 상황입니다. 따라서 이왕이면 사용자가 사용 가능한 PK 로 설정하는게 좋을겁니다.
더 학습해볼 키워드
- 옵티마이저
- 다중 컬럼 인덱스
참고
- Real MySQL 8.0 (백은빈, 이성욱 지음)
- https://www.youtube.com/watch?v=edpYzFgHbqs&t=1230s