아키텍처란
본 아키텍처에 대해 알아보기전에, 저희는 아키텍처의 주목적에 대해 다시 되짚어봐야합니다. 아키텍처는 소프트웨어가 확장과 변경 에 용이하도록 설계해서 쉽게 유지.보수를 할 수 있도록 만드는 기법이죠. 하지만 프로젝트를 이루는 각 구성단위는 서로에게 지나친 의존성 을 지니게 되어서, 확장과 변경에 닫혀있게 될 수 있습니다.
소프트웨어의 구성
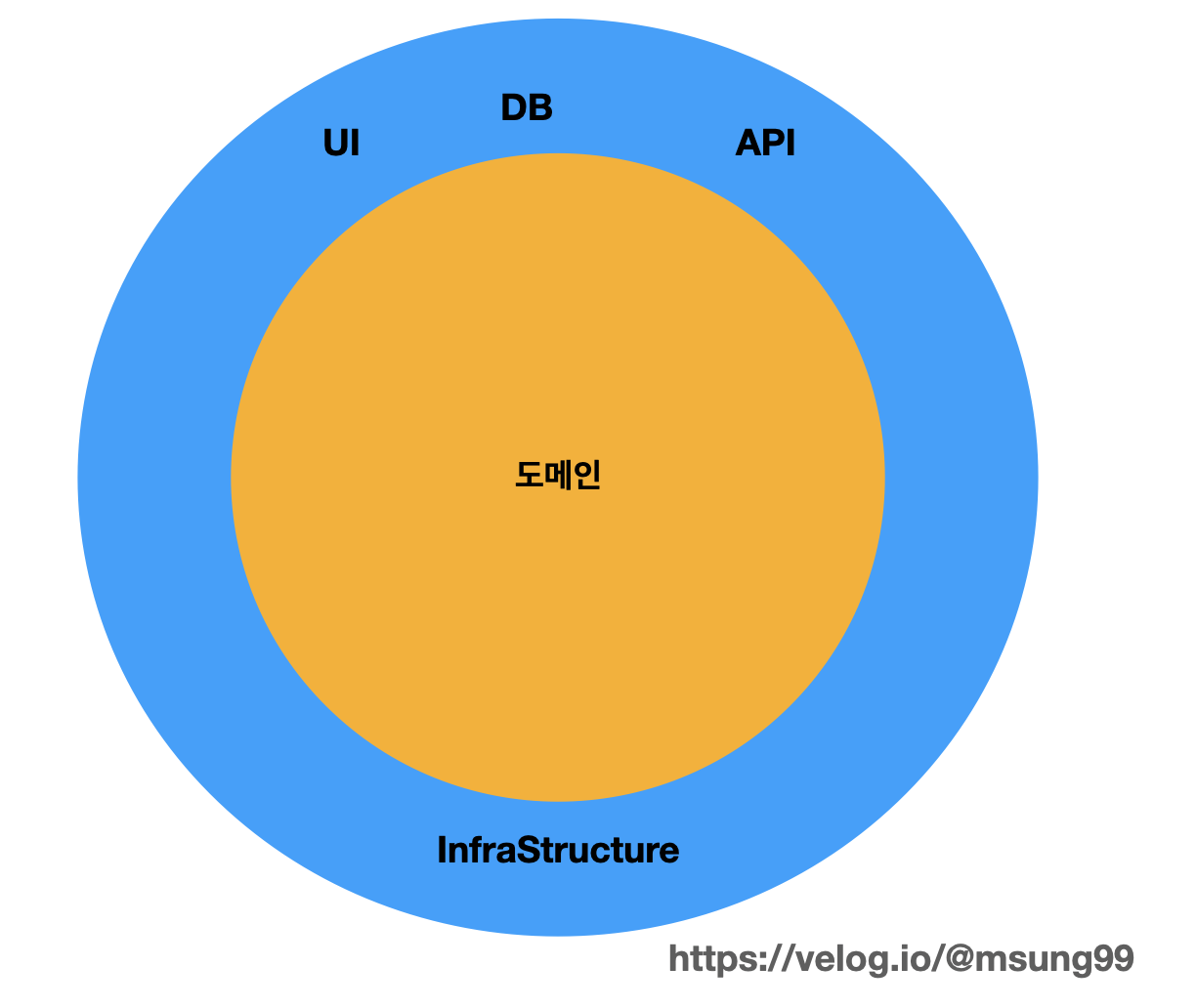
한 소프트웨어, 즉 서비스는 크게 도메인 영역과 인프라스트럭처(InfraStructure) 영역으로 구분됩니다. 도메인이란 시스템의 핵심 데이터를 나타내는 것이며, 인프라스트럭처란 도메인을 뒷받침해서 사용자들에게 서비스를 제공하기 위한 서브 요소입니다. 데이터를 저장할 DB, 외부 서비스 API, 도메인을 화면에 표시할 UI 등이 이에 해당되죠.
전통적 계층형 아키텍처
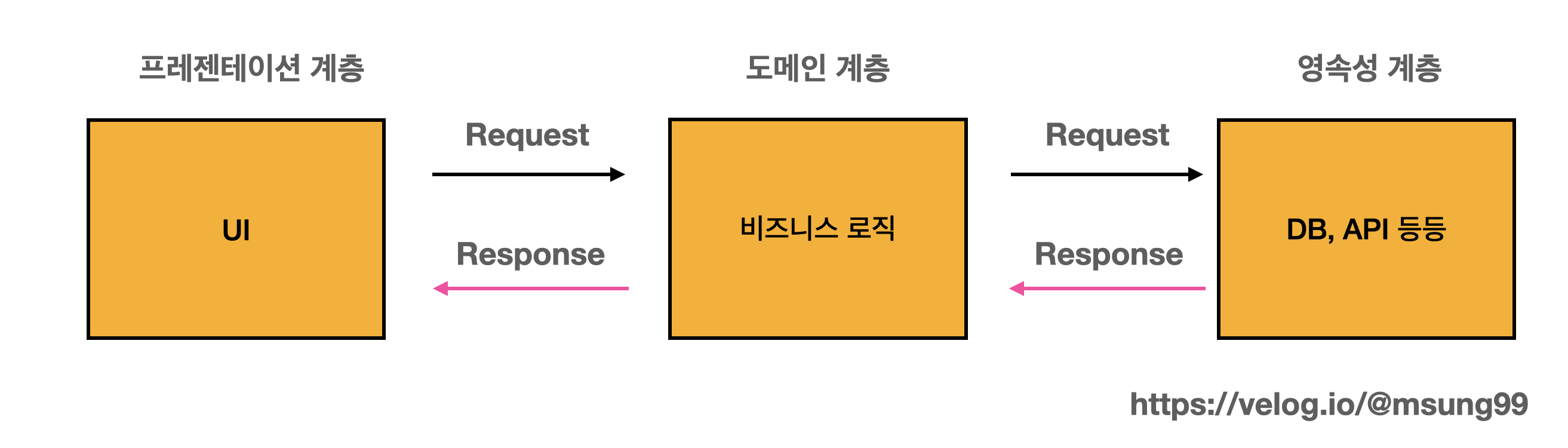
계층적 아키텍처는 같은 목적의 코드들을 한 계층에 모아놓음으로써, 코드들의 관심사를 분리하는 아키텍처입니다. 가령 위처럼 UI 를 표현하기 위한 코드들은 프레젠테이션 계층에 모아놓고, 비즈니스 로직들은 도메인 계층에 놓는 방식인것입니다. 저도 최근까지만 해도 이 방식으로 단순한 계층구조를 만들고 개발을 진행했었습니다.
계층간의 의존성 문제
그러나 위와 같은 전통적인 계층적 아키텍처 구조는 연쇄적인 참조관계 를 가진다는 문제점이 있습니다. 프레젠테이션은 도메인 계층의 비즈니스 로직을 참조하고, 이 비즈니스 로직은 또 영속성 계층의 데이터를 참조하므로, 결국 프레젠테이션의 UI 가 영속성 계층의 데이터를 직접 참조하는 꼴이 되버리죠.
결국 한 계층의 변경사항이 일어나면 그 변경의 여파가 모든 계층에 전파될 수 있으며, 확장과 변경에 닫혀있다고 할 수 있습니다. 즉, 각 계층은 서로에게 의존성을 지니고 있습니다.
특히 비즈니스 로직이 흐르고 있는 도메인 영역은 철저지 보호되어야 하는데, 의존성 문제로 인해 다른 계층에서 빈번한 수정이 일어나면 도메인 영역에 손상을 입히게 됩니다.
클린 아키텍처의 등장
기존의 계층적 구조는 보듯이 의존성 이라는 것 떄문에 꽤나 번거로움을 지니고 있었죠. 의존성 이슈를 보완하고자 고안한 방법이 바로 클린 아키텍처입니다.
클린 아키텍처에서는 의존성 규칙 과 경계성 규칙 을 준수하며 시스템을 구성할 것을 강조하고 있습니다.
의존성 규칙
의존성 규칙이란, 모든 소스코드의 의존성은 반드시 외부에서 내부로, 즉 고수준 정책을 향해야 한다는 것입니다. 즉, 비즈니스 로직을 담당하는 코드들이 DB 또는 UI 같이 구체적인 세부사항을 의존하지 않아야 한다는 것입니다.
추후 서술하겠지만, 클린 아키텍처의 내부 구성요소는 추상화된 인퍼페이스(포트) 를 톤해 외부 계층의 구성요소와 통신합니다. 이를통해 비즈니즈 로직(고수준 정책)은 세부 사항들(저수준 정책)의 변경에 영향을 받지 않도록 할 수 있습니다.
- 고수준 정책 : 상위 수준의 개념, 추상화된 개념 (ex. 데이터를 저장한다, 주문을 처리한다)
- 저수준 정책 : 추상화된 개념을 실제로 어떻게 구현할지에 대한 세부적인 개념 (ex. MySQL 에 데이터를 저장한다, 유저 A 에 대한 주문을 처리한다)
경계성 규칙
경계성 규칙이란 서비스(소프트웨어)를 데이터가 오가는 외부-내부의 경계(Bounary) 를 명확히 그어두어서, 데이터의 흐름을 효율적으로 제어하자는 규칙입니다. 이것도 뒤 이어서 서술하겠지만, 경계성 규칙은 어댑터를 통해 구현됩니다. 가령 DB, UI 와 같은것들을 시스템의 외부로 구분짓고, 그 안의 엔티티, 유즈케이스등을 내부 시스템으로 구분지은후, 이 외부와 내부를 어댑터로 확실히 경계를 긋고 분리시키는 것입니다.
클린 아키텍처
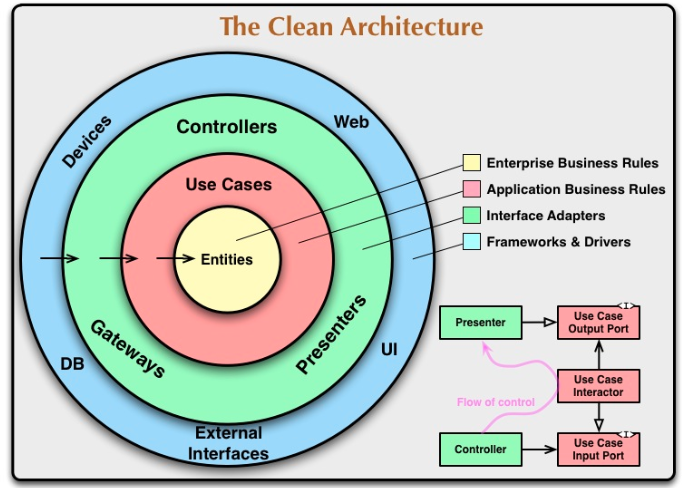
위 그림은 클린 아키텍처에서 제시하는 계층구조입니다. 화살표를 볼 수 있는데, 이는 의존성의 방향을 나타내는 것입니다. 여기서 중요한 것은, 하위 계층은 상위 계층을 단방향으로 의존하고 있다는 것입니다. 즉, 엔티티와 유즈케이스와 같은 상위 계층은 하위 계층을 의존할 수 없습니다.
추후 계속 설명하겠지만, 이렇게 의존성의 방향을 가지면서 바깥 계층에 변화가 일어나더라도, 내부 계층의 고수준 정책은 영향을 받지 않게 된다는 점을 다시 강조하고 싶습니다. 또 클린 아키텍처의 구성요소를 설명해보자면 다음과 같습니다.
Entity & 유즈케이스
Entity(엔티티) 와 유즈케이스는 내부 계층에 위치한 가장 중요한 요소들입니다. 엔티티는 도메인 계층에 속하며, 유즈케이스는 보통 애플리케이션 계층에 위치해 있습니다.
Entity 는 시스템 내부의 핵심 데이터를 표현하는 것입니다. 반면 유즈케이스(Use Case) 는 애플리케이션의 기능을 구현하는 역할을 담당하며, Entity 를 참조해서 구현합니다. 이 유즈케이스에는 비즈니스 로직이 흐르고 있죠. 또 유즈케이스는 양쪽에 어뎁터(Adapter) 를 통해 외부(저수준 정책)와 연결되는 구조를 지닙니다.
어댑터(Adatper)
어댑터는 외부의 데이터 흐름을 내부 도메인에서 사용할 수 있는 데이터 형식으로 변환해주는 역할을 수행합니다. 어댑터의 종류로는 크게 '컨트롤러(Controller)', 'Presenter(프레젠터)', 'Gateway', 'Repository' 등이 있습니다. 위 그림에서는 녹색 계층에 해당됩니다.
예를들어 Presenter 는 화면 UI 의 입력을 도메인에 맞는 데이터로 변환하는 역할을 수행하며, Repository 는 외부의 DB, 또는 API 데이터를 도메인에 맞는 데이터로 변환하는 역할을 수행합니다.
포트 (인터페이스)
포트(Port) 는 인터페이스로 구현되는 개념입니다. 포트는 특정한 계층 내부에서 어떤 역할을 수행하기 위한 인터페이스를 정의하죠. 포트는 유스케이스와 어댑터 사이에 위치해서, 유스케이스가 제공하는 기능과 필요한 기능을 제공하는 역할을 수행합니다. 위 그림에서는 보이지 않지만, 적색 계층(애플리케이션 계층) 과 녹색 계층 사이에 위치해서 서로를 연결하는 징검다리 역할을 수행하게 됩니다.
유스케이스와 어댑터는 서로 직접 연결된 것이 아닌, 사전에 정의된 포트라는 인터페이스로 연결되기만 하면 됩니다. 때문에 유스케이스와 어댑터는 서로 구체적인 명세 없이도 추상화 개념을 도입해서, 서로에게 변경사항이 있어도 영향을 미치지 않을 수 있습니다.
기존 계층구조에 클린 아키텍처를 적용해볼까?
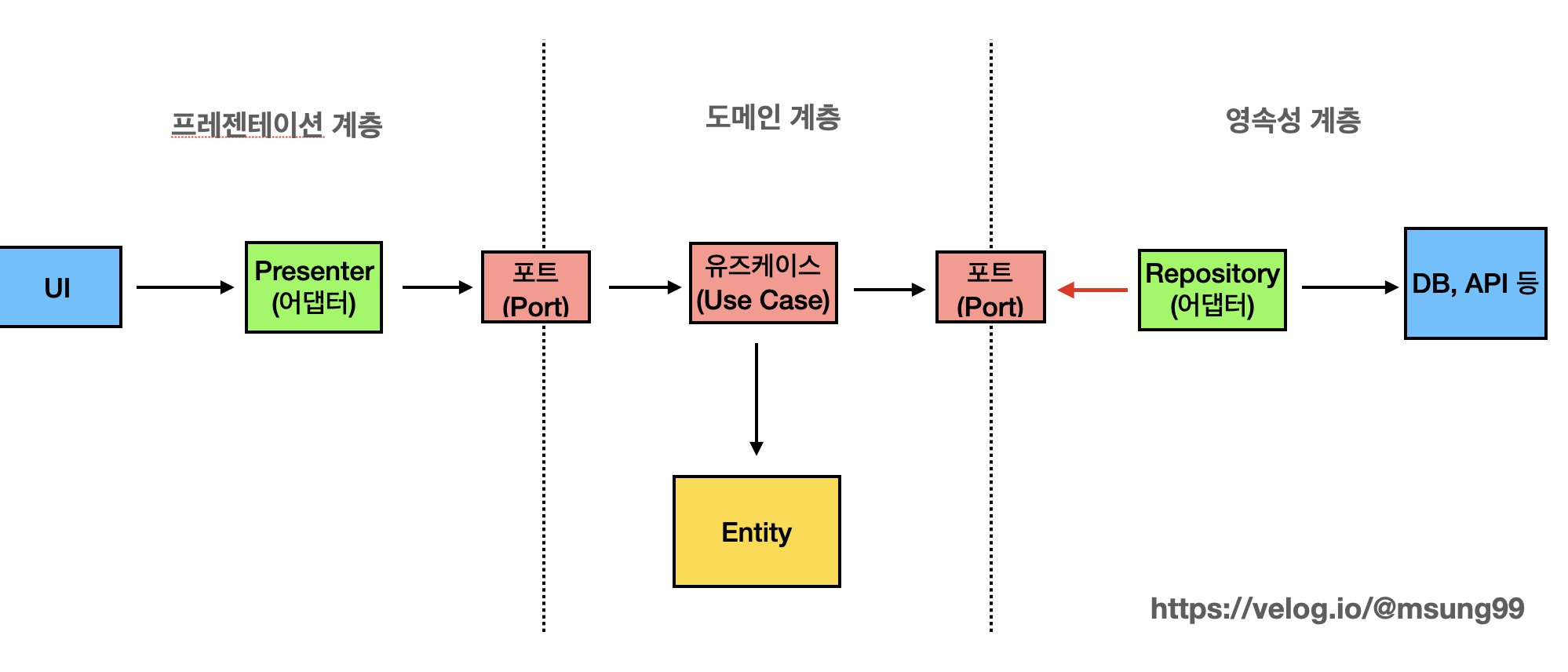
앞서 살펴봤던 기존 계층적 구조로 구성된 클린 아키텍처를 도입해보면, 위와 같은 리팩토링 구조가 나타나게 될것입니다. 화살표는 참조의 방향, 즉 의존성의 방향을 뜻합니다.
우선 외부의 변경으로부터 보호되어야할 엔티티가 가운대에 위치해있으며, 유스케이스는 엔티티를 참조하여 애플리케이션이 제공해야할 기능을 구현할 것입니다.
또 유스케이스의 양쪽에는 Presenter, Repository 어댑터가 달려있는데, 이 어댑터들로 UI, DB, API 와 같은 외부의 존재로부터 유입되는 데이터 흐름을 내부 도메인에서 사용할 수 있는 데이터 형식으로 변환해주는 역할을 수행합니다. 앞서 말한 내용이지만, Presenter 는 화면 UI 의 입력을 도메인에 맞는 데이터로 변환하는 역할을 수행하며, Repository 는 외부의 DB, 또는 API 데이터를 도메인에 맞는 데이터로 변환하는 역할을 수행합니다.
인터페이스(포트)는 일종의 약속으로써, 유즈케이스가 제공하는 기능과 필요한 기능을 포트에다 추상화해놓으면, 각 어댑터는 인터페이스만을 보고 구현하면 됩니다.
객체지향으로 귀결되는 클린 아키텍처
클린 아키텍처의 컨셉을 처음접하며 느낀바는, 결국 클린 아키텍처의 내용도 객체지향으로 귀결되는듯 하다는걸 느꼈습니다. 포트(Port) 라는 추상화 인터페이스를 제공하는 것은 의존성 주입, 즉 DI(Dependency Injection) 를 위한 것입니다. 또 DI 를 통해 SOLID 원칙의 DIP 의존관계 원칙도 지킬 수 있게 되는 것이겠죠. 예제로 이해하는 SOLID 설계원칙, 그리고 스프링 DI 컨테이너의 등장 에서 다루었던 내용을 다시 자연스래 복기해보게 되었네요.
또한 객체지향의 기초이자 핵심이라 할 수 있는 변경과 확장성 측면에서 바라봐도, 클린 아키텍처를 도입시 용이하게 설계를 고려해볼 수 있을것이란 생각이듭니다. 조만간 학습할 헥사고날 아키텍처 의 경우도 클린 아키텍처에서 파생된 것이므로, 이 또한 객체지향으로 귀결되는 내용이라고 생각합니다.