검색엔진을 이용하다보면, 검색어를 타이밍하는 순간 연관된 추천 검색어들이 등장하는 것을 알 수 있다. 그런데, 어떻게해서 사용자가 타이핑을 하는 그 '찰나' 에 추천 검색어를 빠르게 찾아낼 수 있을까? 그리고 많은 인터넷 문서들 가운데, 검색 키워드에 맞는 문서를 찾아낼 수 있을까? 일반적인 선형탐색을 떠올린다면 절대로 불가능한 속도이다. 이를 가능하게 하는 방법 중 하나가 바로 Elastic Search 를 활용하는 것이다.
Elastic Search
엘라스틱 서치는 Lucene 기반의 오픈소스 검색엔진이다. 잠시 RDBMS 의 인덱스를 떠올려보자. MySQL 과 같은 RDBMS 를 떠올려본다면, 테이블이 인덱싱되면 복잡한 쿼리에서 훨씬 빠른 성능을 보여준다는 것을 알 것이다. 인덱스를 생성하면, 주어진 검색어를 찾기 위해 모든 열을 찾아보는 대신에 인덱스를 활용하여 원하는 데이터가 어디있는지를 찾아낼 수 있다.
엘라스틱 서치의 경우, 검색어가 될 수 있는 문자 또는 문자열에 대해 유연하게 여러 토큰(term)으로 토큰화하고 역 인덱싱한다. (역 인덱스에 대한 내용은 조금 뒤에 설명하도록 한다.) 예를들어 "Hello my world" 가 있다고 해보자. 이 문자열에 대해 빠른 검색 기능을 제공하고자 Elastic Search 를 도입한다면, 이 문장에 대해선 아래와 같은 방법으로 토큰화되고, 인덱싱 될 것이다.
- ["Hello my world"] : 문자를 통째로 토큰화 할 수 있고,
- ["Hello", "my", "world"] : 각각의 단어를 토큰화 할 수도 있고,
- ["Hello", "world"] : 의미있는 중요한 단어들로만 토큰화 할수도 있고,
- ["hElLo", "WoRlD"] : 대소문자를 구분하지 않고 모두 검색 대상에 포함될 수 있도록 다양하게 토큰화할 수 있다.
이렇게 토큰화된 단어들은 인덱스 key 가 되어, 훨씬 빠른 검색 기능을 지원하게 된다.
역 인덱스 (Inverted Index)
엘라스틱 서치는 검색할 데이터를 역 인덱싱한다. 역 인덱스란 무엇일까? 우리가 일반적으로 알고있는 데이터베이스 인덱스는 책 앞 부분의 목차로 비유한다. 그에 반면, 역 인덱스는 책 뒷부분의 찾아보기에 비유할 수 있다. 책에서 찾아보기는 특정 키워드가 책의 몇 페이지에서 등장했는지를 나타낸다.
MySQL 과 같이 일반적인 RDBMS는 텍스트로 데이터를 검색하기 위해서 LIKE 연산, 즉 패턴 매칭으로 데이터를 탐색한다. 그런데 문제는, LIKE 연산은 성능이 못하다는 점이다. 데이터베이스의 50번째 행, 1,000번째 행에 devhaon 라는 데이터가 저장되어있는 경우를 가정해보자. 만약 RDBMS 에서 LIKE %devhaon% 으로 데이터를 검색한다면, 1,000번째 행까지 모두 탐색을 해야한다. 반면 역 인덱스 구조에선 devhaon 이라는 키워드가 어디있는지 바로 알 수 있다.
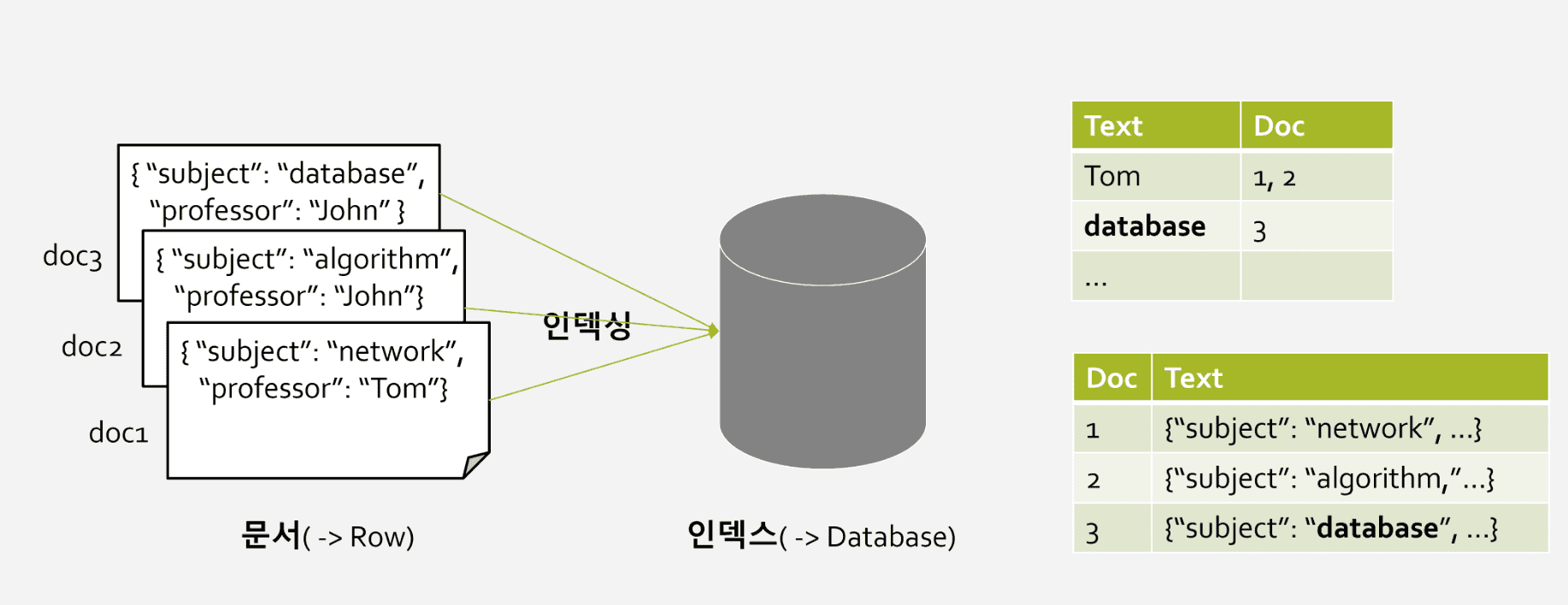
위 그림을 살펴보자. 우선 Doc1 ~ 3 을 일반적인 RDBNS 에 저장하고, LIKE 연산자를 활용하여 database 라는 단어가 포함된 테이블을 검색한다고 해보자. (Doc 은 마치 데이터베이스의 하나의 행(row) 개념이라고 이해하면 쉽다.) 이 경우 해당 테이블의 모든 row 를 탐색해야 하므로, O(n) 이라는 시간이 소요될 것이다.
반면 Elastic Search 를 사용하여 역 인덱스를 검색하는 경우라면, 곧 바로 database 행을 찾아보니 3번째 Doc 에 있다는 것을 알 수 있다. 마치 해시 테이블과 같이, key 값만 안다면 그 즉시 value 를 O(1) 에 찾아낼 수 있는 것과 같다. 이때 key 값이란 역 인덱스에서 토큰(term) 이 될 것이다.
역 인덱싱 과정 (토큰 생성 과정)
다시 한 번 앞서 예시로 들었던 "Hello My World" 를 예시로 들어, Elastic Search 에서 토큰이 생성되는 과정을 알아보자.
(1)텍스트를 특정 단위 (여기서는 띄어쓰기) 단위로 분리한다. ["Hello", "My", "World"] 와 같이 분리한다.(2)대문자를 모두 소문자로 변경하고, 토큰을 아스키 코드 순서대로 정렬한다.(3)검색에 잘 사용되지 않는 굳이 필요없는 불용어(a, the, of, for, to 등) 를 제거한다.(4)형태소 분석 과정을 거쳐서 단어를 원형으로 변환한다. (예를들어 executing 단어를 execute 와 같이 원형으로 변환)(5)중복되는 토큰에 대해 토큰 단 1개만을 남긴다. (중복 토큰 제거)
이렇듯 역 인덱스는 생각보다 생성하는데에 많은 작업이 요구된다. 그 때문에 원하는 데이터가 역 인덱싱되는데 까지 걸리는 시간이 좀 오래 걸리는데, 이 생성되는데 까지 걸리는 시간을 NRT(Near Real Time) 이라고 한다.
ELK Stack 에서의 역할

Elatic Search 는 흔히 부르는 ELK Stack 에 사용된다. ELK Stack 이란 Elastic Search, Logstatch, Kibana 를 합친 약자로, 데이터를 수집하고 분석하는 도구를 뜻환다.
그 중에서 Elastic Search 는 Lucene 기반 검색엔진 (NoSQL 데이터베이스로도 분류하기도 함) 이며, 대량의 데이터를 빠르게 저장하고 검색할 수도 있도록 지원한다. 앞서 살펴봤듯이, 빠른 데이터 검색을 위해 데이터를 역 인덱싱(Inverted Index) 하여 저장한다. Elastic Search 는 클러스터 구조로 분산 구성된다. 따라서 고가용성과 확장성있는 설계에 유리하다. 또한 우리가 아는 일반적인 RDBMS 와 다르게 SQL 을 지원하지 않고, Restful API 를 통해 데이터를 추가하고, 검색한다. 마치 SQL 의 SELECT 쿼리가 엘라스틱 서치에서는 GET 요청에 대응되고, INSERT 는 POST 요청에 대응된다.
ELK 스택은 일반적으로 로그 수집, 처리 및 분석에 활용된다. 이 중에서 엘라스틱 서치는 계속 설명했듯이 검색 엔진으로, 수집한 로그를 저장하는데에 활용된다.
단점
엘라스틱 서치 또한 단점이 존재하기에, RDBMS 를 많이 사용한다. 엘라스틱 서치는 JOIN 절을 지원하지 않는다고 한다. 또한 트랜잭션을 지원하지 않는다.
정리
-
엘라스틱 서치란? : 엘라스틱 서치는 역 인덱스 구조의 검색엔진으로, 검색어가 될 수 있는 문자에 대해 여러 토큰(term) 을 생성하고 O(1) 에 검색할 수 있도록 지원한다.
-
Elastic Search의 인덱스구조와 RDBMS의 인덱스 구조의 차이점 : 일반적인 RDBMS의 인덱스는 B+ Tree 기반의 자료구조로 구성되며, 정형 데이터에 대한 검색만을 빠르게 지원한다. 반면, 엘라스틱 서치는 역 인덱스 자료구조로 구성되며, 비정형 데이터에 대한 검색을 빠르게 지원한다.
-
Elastic Search의 키워드 검색과 RDBMS의 LIKE 검색의 차이점 : RDBMS 는 단순히 패턴과 일치하는 검색(단순 패턴 매칭)만을 제공하여, 동의어나 유의어 같은 검색은 불가능하다. 하지만, 엘라스틱 서치는 동의어나 유의어를 활용한 검색이 가능하며, 비정형 데이터의 색인과 검색이 가능하고, 역 인덱스를 지원하므로 매우 빠른 검색이 가능하다.
💡 MySQL 최신 버전에서 n-gram 기반의 Full-Text Search 지원하여, 동의어와 유의어에 대한 검색이 가능해졌다고는 한다. 하지만, 한글 검색의 경우 아직 많이 빈약한 감이 있다고 한다. 이때 Full-Text 란 이미지, CSS, 글 등의 복합적으로 이루어진 컨텐트에서 순수하게 텍스트만 추출한 데이터를 뜻한다.
참고
- https://hudi.blog/elasticsearch-inverted-index/
- https://sirzzang.github.io/dev/Dev-elk-stack-01/
- https://esbook.kimjmin.net/06-text-analysis/6.1-indexing-data
- https://lcs1245.tistory.com/entry/SQL-LIKE-%EC%97%B0%EC%82%B0%EC%9E%90-%EB%AC%B8%EC%9E%90%EC%97%B4-%EB%B6%80%EB%B6%84%EC%9D%BC%EC%B9%98-%EA%B2%80%EC%83%89
- https://dev-coco.tistory.com/158